 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditioning Matters: Stabilizing Inversion and Attention in Diffusion Image Editing
Jun 12, 2026Inversion-based image editing offers flexible and training-free control but still struggles with inversion accuracy and the trade-off between editing fidelity and background preservation. While recent methods improve inversion formulations or attention interactions, the role of textual conditioning in shaping diffusion dynamics and editing behavior remains underexplored. We show both empirically and theoretically that the precision of textual conditioning influences inversion stability by modulating the geometry of the diffusion velocity field, while also affecting the consistency of cross-branch attention during editing. These effects directly impact background preservation and semantic fidelity. Building on this analysis, we propose SimEdit, a conditioning-aware framework with two complementary components: (a) conditioning refinement, which constructs conditioning signals with improved semantic precision and structural alignment to facilitate stable inversion and consistent attention manipulation, and (b) token-wise cross-branch attention control, which separates edit-relevant and structure-preserving components and modulates them asymmetrically during attention manipulation. Extensive experiments on PIE-Bench demonstrate that SimEdit consistently improves both inversion reconstruction quality and editing performance over previous attention-manipulation approaches. Our code is available at https://github.com/zju-pi/SimEdit.
Generative AI for Film Creation: A Survey of Recent Advances
Apr 11, 2025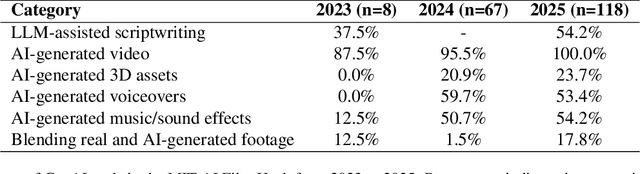


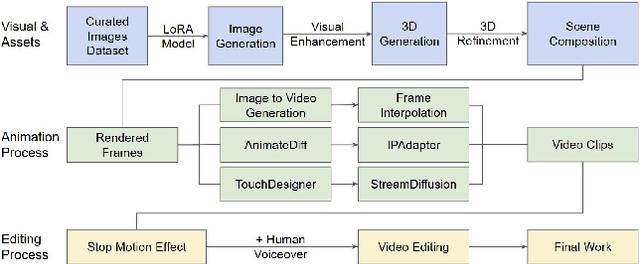
Generative AI (GenAI) is transforming filmmaking, equipping artists with tools like text-to-image and image-to-video diffusion, neural radiance fields, avatar generation, and 3D synthesis. This paper examines the adoption of these technologies in filmmaking, analyzing workflows from recent AI-driven films to understand how GenAI contributes to character creation, aesthetic styling, and narration. We explore key strategies for maintaining character consistency, achieving stylistic coherence, and ensuring motion continuity. Additionally, we highlight emerging trends such as the growing use of 3D generation and the integration of real footage with AI-generated elements. Beyond technical advancements, we examine how GenAI is enabling new artistic expressions, from generating hard-to-shoot footage to dreamlike diffusion-based morphing effects, abstract visuals, and unworldly objects. We also gather artists' feedback on challenges and desired improvements, including consistency, controllability, fine-grained editing, and motion refinement. Our study provides insights into the evolving intersection of AI and filmmaking, offering a roadmap for researchers and artists navigating this rapidly expanding field.
HOIGPT: Learning Long Sequence Hand-Object Interaction with Language Models
Mar 24, 2025



We introduce HOIGPT, a token-based generative method that unifies 3D hand-object interactions (HOI) perception and generation, offering the first comprehensive solution for captioning and generating high-quality 3D HOI sequences from a diverse range of conditional signals (\eg text, objects, partial sequences). At its core, HOIGPT utilizes a large language model to predict the bidrectional transformation between HOI sequences and natural language descriptions. Given text inputs, HOIGPT generates a sequence of hand and object meshes; given (partial) HOI sequences, HOIGPT generates text descriptions and completes the sequences. To facilitate HOI understanding with a large language model, this paper introduces two key innovations: (1) a novel physically grounded HOI tokenizer, the hand-object decomposed VQ-VAE, for discretizing HOI sequences, and (2) a motion-aware language model trained to process and generate both text and HOI tokens. Extensive experiments demonstrate that HOIGPT sets new state-of-the-art performance on both text generation (+2.01% R Precision) and HOI generation (-2.56 FID) across multiple tasks and benchmarks.
Your Text Encoder Can Be An Object-Level Watermarking Controller
Mar 15, 2025Invisible watermarking of AI-generated images can help with copyright protection, enabling detection and identification of AI-generated media. In this work, we present a novel approach to watermark images of T2I Latent Diffusion Models (LDMs). By only fine-tuning text token embeddings $W_*$, we enable watermarking in selected objects or parts of the image, offering greater flexibility compared to traditional full-image watermarking. Our method leverages the text encoder's compatibility across various LDMs, allowing plug-and-play integration for different LDMs. Moreover, introducing the watermark early in the encoding stage improves robustness to adversarial perturbations in later stages of the pipeline. Our approach achieves $99\%$ bit accuracy ($48$ bits) with a $10^5 \times$ reduction in model parameters, enabling efficient watermarking.
MultiEdits: Simultaneous Multi-Aspect Editing with Text-to-Image Diffusion Models
Jun 03, 2024



Text-driven image synthesis has made significant advancements with the development of diffusion models, transforming how visual content is generated from text prompts. Despite these advances, text-driven image editing, a key area in computer graphics, faces unique challenges. A major challenge is making simultaneous edits across multiple objects or attributes. Applying these methods sequentially for multi-aspect edits increases computational demands and efficiency losses. In this paper, we address these challenges with significant contributions. Our main contribution is the development of MultiEdits, a method that seamlessly manages simultaneous edits across multiple attributes. In contrast to previous approaches, MultiEdits not only preserves the quality of single attribute edits but also significantly improves the performance of multitasking edits. This is achieved through an innovative attention distribution mechanism and a multi-branch design that operates across several processing heads. Additionally, we introduce the PIE-Bench++ dataset, an expansion of the original PIE-Bench dataset, to better support evaluating image-editing tasks involving multiple objects and attributes simultaneously. This dataset is a benchmark for evaluating text-driven image editing methods in multifaceted scenarios. Dataset and code are available at https://mingzhenhuang.com/projects/MultiEdits.html.
Exposing Text-Image Inconsistency Using Diffusion Models
Apr 28, 2024



In the battle against widespread online misinformation, a growing problem is text-image inconsistency, where images are misleadingly paired with texts with different intent or meaning. Existing classification-based methods for text-image inconsistency can identify contextual inconsistencies but fail to provide explainable justifications for their decisions that humans can understand. Although more nuanced, human evaluation is impractical at scale and susceptible to errors. To address these limitations, this study introduces D-TIIL (Diffusion-based Text-Image Inconsistency Localization), which employs text-to-image diffusion models to localize semantic inconsistencies in text and image pairs. These models, trained on large-scale datasets act as ``omniscient" agents that filter out irrelevant information and incorporate background knowledge to identify inconsistencies. In addition, D-TIIL uses text embeddings and modified image regions to visualize these inconsistencies. To evaluate D-TIIL's efficacy, we introduce a new TIIL dataset containing 14K consistent and inconsistent text-image pairs. Unlike existing datasets, TIIL enables assessment at the level of individual words and image regions and is carefully designed to represent various inconsistencies. D-TIIL offers a scalable and evidence-based approach to identifying and localizing text-image inconsistency, providing a robust framework for future research combating misinformation.
Language-guided Human Motion Synthesis with Atomic Actions
Aug 18, 2023Language-guided human motion synthesis has been a challenging task due to the inherent complexity and diversity of human behaviors. Previous methods face limitations in generalization to novel actions, often resulting in unrealistic or incoherent motion sequences. In this paper, we propose ATOM (ATomic mOtion Modeling) to mitigate this problem, by decomposing actions into atomic actions, and employing a curriculum learning strategy to learn atomic action composition. First, we disentangle complex human motions into a set of atomic actions during learning, and then assemble novel actions using the learned atomic actions, which offers better adaptability to new actions. Moreover, we introduce a curriculum learning training strategy that leverages masked motion modeling with a gradual increase in the mask ratio, and thus facilitates atomic action assembly. This approach mitigates the overfitting problem commonly encountered in previous methods while enforcing the model to learn better motion representations. We demonstrate the effectiveness of ATOM through extensive experiments, including text-to-motion and action-to-motion synthesis tasks. We further illustrate its superiority in synthesizing plausible and coherent text-guided human motion sequences.
AutoSplice: A Text-prompt Manipulated Image Dataset for Media Forensics
Apr 14, 2023



Recent advancements in language-image models have led to the development of highly realistic images that can be generated from textual descriptions. However, the increased visual quality of these generated images poses a potential threat to the field of media forensics. This paper aims to investigate the level of challenge that language-image generation models pose to media forensics. To achieve this, we propose a new approach that leverages the DALL-E2 language-image model to automatically generate and splice masked regions guided by a text prompt. To ensure the creation of realistic manipulations, we have designed an annotation platform with human checking to verify reasonable text prompts. This approach has resulted in the creation of a new image dataset called AutoSplice, containing 5,894 manipulated and authentic images. Specifically, we have generated a total of 3,621 images by locally or globally manipulating real-world image-caption pairs, which we believe will provide a valuable resource for developing generalized detection methods in this area. The dataset is evaluated under two media forensic tasks: forgery detection and localization. Our extensive experiments show that most media forensic models struggle to detect the AutoSplice dataset as an unseen manipulation. However, when fine-tuned models are used, they exhibit improved performance in both tasks.
Variational Transfer Learning for Fine-grained Few-shot Visual Recognition
Oct 12, 2020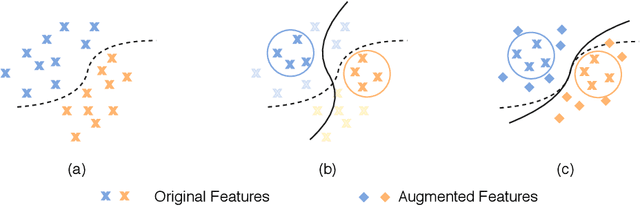

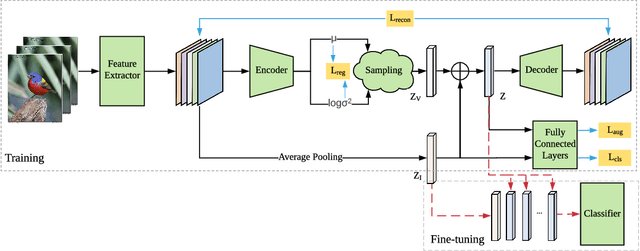
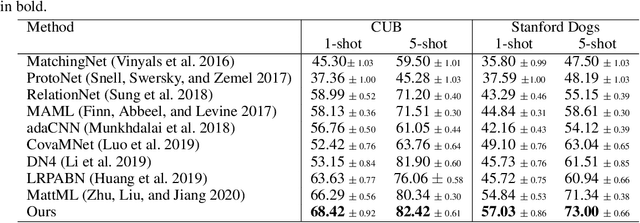
Fine-grained few-shot recognition often suffers from the problem of training data scarcity for novel categories.The network tends to overfit and does not generalize well to unseen classes due to insufficient training data. Many methods have been proposed to synthesize additional data to support the training. In this paper, we focus one enlarging the intra-class variance of the unseen class to improve few-shot classification performance. We assume that the distribution of intra-class variance generalizes across the base class and the novel class. Thus, the intra-class variance of the base set can be transferred to the novel set for feature augmentation. Specifically, we first model the distribution of intra-class variance on the base set via variational inference. Then the learned distribution is transferred to the novel set to generate additional features, which are used together with the original ones to train a classifier. Experimental results show a significant boost over the state-of-the-art methods on the challenging fine-grained few-shot image classification benchmarks.
LaSOT: A High-quality Large-scale Single Object Tracking Benchmark
Sep 12, 2020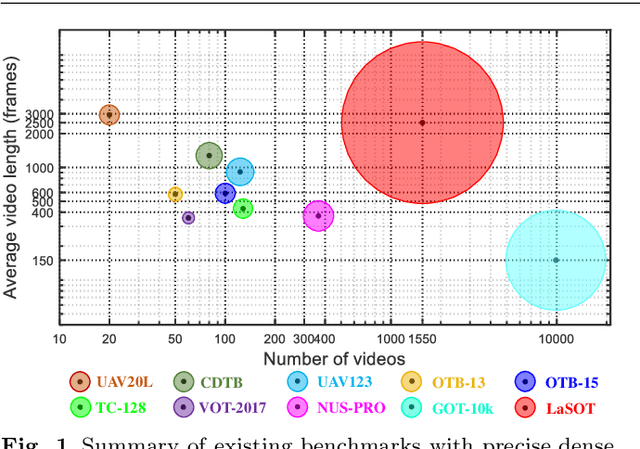
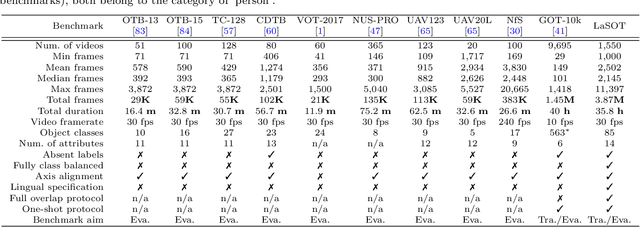
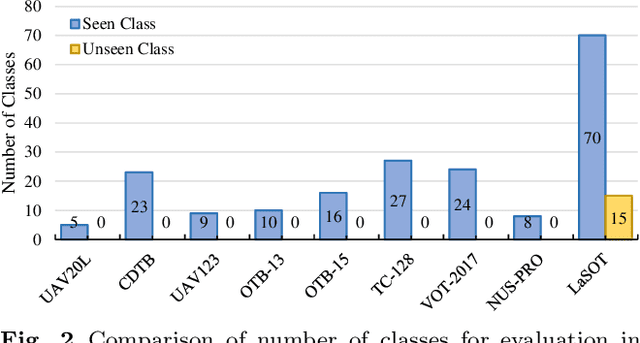

Despite great recent advances in visual tracking, its further development, including both algorithm design and evaluation, is limited due to lack of dedicated large-scale benchmarks. To address this problem, we present LaSOT, a high-quality Large-scale Single Object Tracking benchmark. LaSOT contains a diverse selection of 85 object classes, and offers 1,550 totaling more than 3.87 million frames. Each video frame is carefully and manually annotated with a bounding box. This makes LaSOT, to our knowledge, the largest densely annotated tracking benchmark. Our goal in releasing LaSOT is to provide a dedicated high quality platform for both training and evaluation of trackers. The average video length of LaSOT is around 2,500 frames, where each video contains various challenge factors that exist in real world video footage,such as the targets disappearing and re-appearing. These longer video lengths allow for the assessment of long-term trackers. To take advantage of the close connection between visual appearance and natural language, we provide language specification for each video in LaSOT. We believe such additions will allow for future research to use linguistic features to improve tracking. Two protocols, full-overlap and one-shot, are designated for flexible assessment of trackers. We extensively evaluate 48 baseline trackers on LaSOT with in-depth analysis, and results reveal that there still exists significant room for improvement. The complete benchmark, tracking results as well as analysis are available at http://vision.cs.stonybrook.edu/~lasot/.