 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSiamMM: A Mixture Model Perspective on Deep Unsupervised Learning
Nov 07, 2025Recent studies have demonstrated the effectiveness of clustering-based approaches for self-supervised and unsupervised learning. However, the application of clustering is often heuristic, and the optimal methodology remains unclear. In this work, we establish connections between these unsupervised clustering methods and classical mixture models from statistics. Through this framework, we demonstrate significant enhancements to these clustering methods, leading to the development of a novel model named SiamMM. Our method attains state-of-the-art performance across various self-supervised learning benchmarks. Inspection of the learned clusters reveals a strong resemblance to unseen ground truth labels, uncovering potential instances of mislabeling.
HOIGPT: Learning Long Sequence Hand-Object Interaction with Language Models
Mar 24, 2025



We introduce HOIGPT, a token-based generative method that unifies 3D hand-object interactions (HOI) perception and generation, offering the first comprehensive solution for captioning and generating high-quality 3D HOI sequences from a diverse range of conditional signals (\eg text, objects, partial sequences). At its core, HOIGPT utilizes a large language model to predict the bidrectional transformation between HOI sequences and natural language descriptions. Given text inputs, HOIGPT generates a sequence of hand and object meshes; given (partial) HOI sequences, HOIGPT generates text descriptions and completes the sequences. To facilitate HOI understanding with a large language model, this paper introduces two key innovations: (1) a novel physically grounded HOI tokenizer, the hand-object decomposed VQ-VAE, for discretizing HOI sequences, and (2) a motion-aware language model trained to process and generate both text and HOI tokens. Extensive experiments demonstrate that HOIGPT sets new state-of-the-art performance on both text generation (+2.01% R Precision) and HOI generation (-2.56 FID) across multiple tasks and benchmarks.
ICON: Incremental CONfidence for Joint Pose and Radiance Field Optimization
Jan 17, 2024Neural Radiance Fields (NeRF) exhibit remarkable performance for Novel View Synthesis (NVS) given a set of 2D images. However, NeRF training requires accurate camera pose for each input view, typically obtained by Structure-from-Motion (SfM) pipelines. Recent works have attempted to relax this constraint, but they still often rely on decent initial poses which they can refine. Here we aim at removing the requirement for pose initialization. We present Incremental CONfidence (ICON), an optimization procedure for training NeRFs from 2D video frames. ICON only assumes smooth camera motion to estimate initial guess for poses. Further, ICON introduces ``confidence": an adaptive measure of model quality used to dynamically reweight gradients. ICON relies on high-confidence poses to learn NeRF, and high-confidence 3D structure (as encoded by NeRF) to learn poses. We show that ICON, without prior pose initialization, achieves superior performance in both CO3D and HO3D versus methods which use SfM pose.
HyperMix: Out-of-Distribution Detection and Classification in Few-Shot Settings
Dec 22, 2023
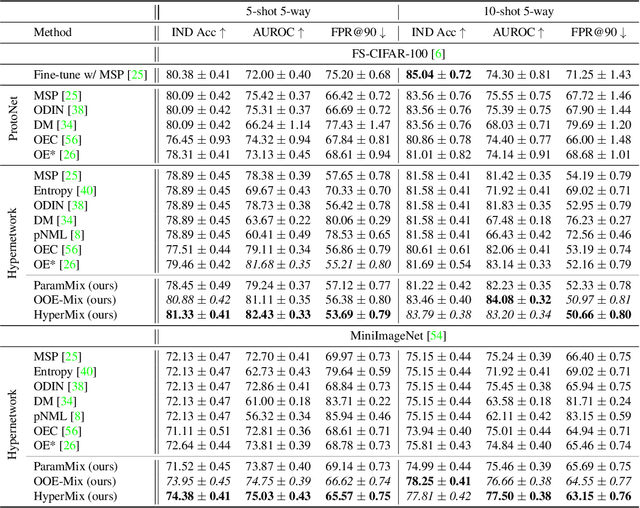
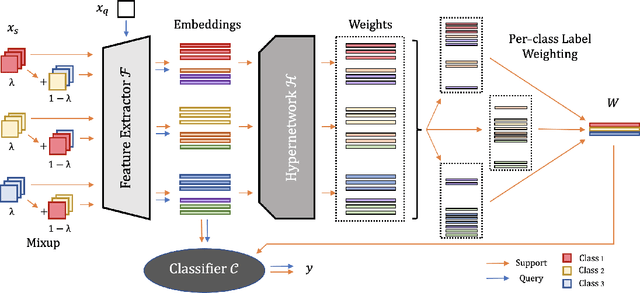
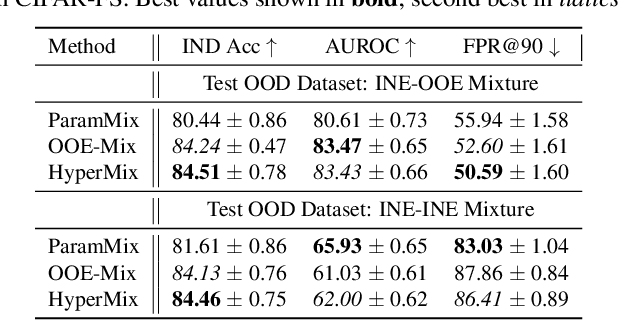
Out-of-distribution (OOD) detection is an important topic for real-world machine learning systems, but settings with limited in-distribution samples have been underexplored. Such few-shot OOD settings are challenging, as models have scarce opportunities to learn the data distribution before being tasked with identifying OOD samples. Indeed, we demonstrate that recent state-of-the-art OOD methods fail to outperform simple baselines in the few-shot setting. We thus propose a hypernetwork framework called HyperMix, using Mixup on the generated classifier parameters, as well as a natural out-of-episode outlier exposure technique that does not require an additional outlier dataset. We conduct experiments on CIFAR-FS and MiniImageNet, significantly outperforming other OOD methods in the few-shot regime.
Meta-Learned Attribute Self-Interaction Network for Continual and Generalized Zero-Shot Learning
Dec 02, 2023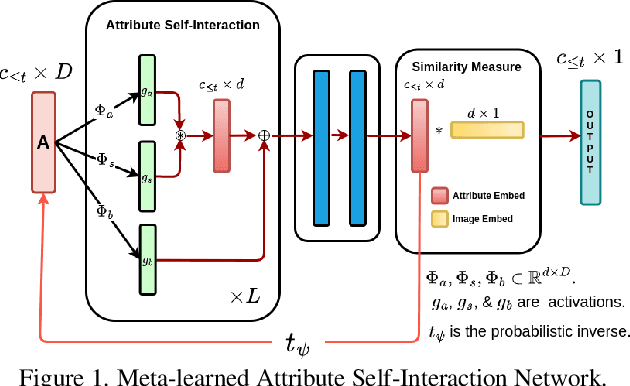
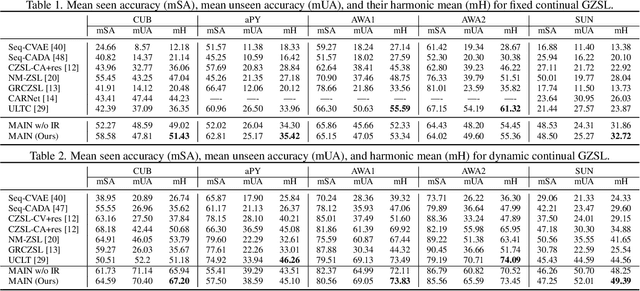
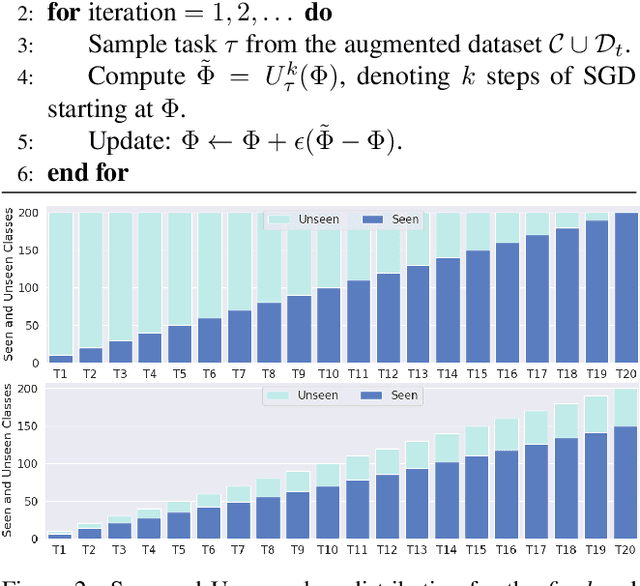
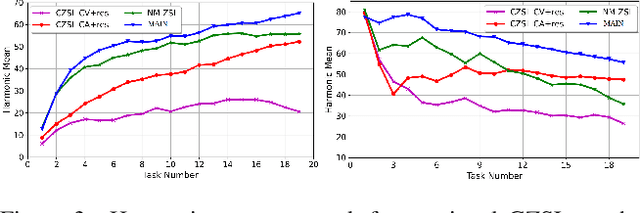
Zero-shot learning (ZSL) is a promising approach to generalizing a model to categories unseen during training by leveraging class attributes, but challenges remain. Recently, methods using generative models to combat bias towards classes seen during training have pushed state of the art, but these generative models can be slow or computationally expensive to train. Also, these generative models assume that the attribute vector of each unseen class is available a priori at training, which is not always practical. Additionally, while many previous ZSL methods assume a one-time adaptation to unseen classes, in reality, the world is always changing, necessitating a constant adjustment of deployed models. Models unprepared to handle a sequential stream of data are likely to experience catastrophic forgetting. We propose a Meta-learned Attribute self-Interaction Network (MAIN) for continual ZSL. By pairing attribute self-interaction trained using meta-learning with inverse regularization of the attribute encoder, we are able to outperform state-of-the-art results without leveraging the unseen class attributes while also being able to train our models substantially faster (>100x) than expensive generative-based approaches. We demonstrate this with experiments on five standard ZSL datasets (CUB, aPY, AWA1, AWA2, and SUN) in the generalized zero-shot learning and continual (fixed/dynamic) zero-shot learning settings. Extensive ablations and analyses demonstrate the efficacy of various components proposed.
Ego-Exo4D: Understanding Skilled Human Activity from First- and Third-Person Perspectives
Nov 30, 2023



We present Ego-Exo4D, a diverse, large-scale multimodal multiview video dataset and benchmark challenge. Ego-Exo4D centers around simultaneously-captured egocentric and exocentric video of skilled human activities (e.g., sports, music, dance, bike repair). More than 800 participants from 13 cities worldwide performed these activities in 131 different natural scene contexts, yielding long-form captures from 1 to 42 minutes each and 1,422 hours of video combined. The multimodal nature of the dataset is unprecedented: the video is accompanied by multichannel audio, eye gaze, 3D point clouds, camera poses, IMU, and multiple paired language descriptions -- including a novel "expert commentary" done by coaches and teachers and tailored to the skilled-activity domain. To push the frontier of first-person video understanding of skilled human activity, we also present a suite of benchmark tasks and their annotations, including fine-grained activity understanding, proficiency estimation, cross-view translation, and 3D hand/body pose. All resources will be open sourced to fuel new research in the community.
GliTr: Glimpse Transformers with Spatiotemporal Consistency for Online Action Prediction
Oct 24, 2022Many online action prediction models observe complete frames to locate and attend to informative subregions in the frames called glimpses and recognize an ongoing action based on global and local information. However, in applications with constrained resources, an agent may not be able to observe the complete frame, yet must still locate useful glimpses to predict an incomplete action based on local information only. In this paper, we develop Glimpse Transformers (GliTr), which observe only narrow glimpses at all times, thus predicting an ongoing action and the following most informative glimpse location based on the partial spatiotemporal information collected so far. In the absence of a ground truth for the optimal glimpse locations for action recognition, we train GliTr using a novel spatiotemporal consistency objective: We require GliTr to attend to the glimpses with features similar to the corresponding complete frames (i.e. spatial consistency) and the resultant class logits at time t equivalent to the ones predicted using whole frames up to t (i.e. temporal consistency). Inclusion of our proposed consistency objective yields ~10% higher accuracy on the Something-Something-v2 (SSv2) dataset than the baseline cross-entropy objective. Overall, despite observing only ~33% of the total area per frame, GliTr achieves 53.02%and 93.91% accuracy on the SSv2 and Jester datasets, respectively.
Task Grouping for Multilingual Text Recognition
Oct 13, 2022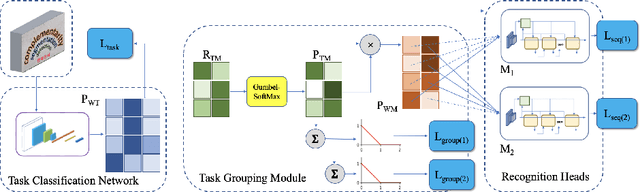
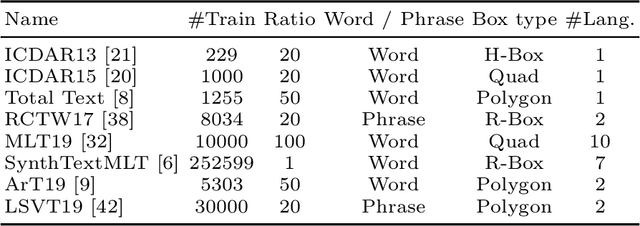
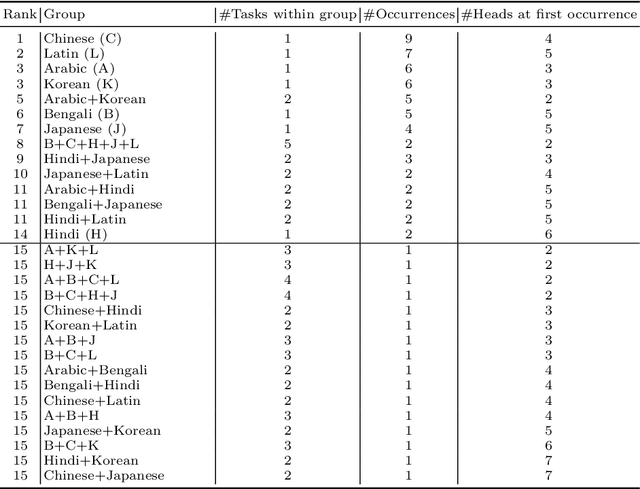

Most existing OCR methods focus on alphanumeric characters due to the popularity of English and numbers, as well as their corresponding datasets. On extending the characters to more languages, recent methods have shown that training different scripts with different recognition heads can greatly improve the end-to-end recognition accuracy compared to combining characters from all languages in the same recognition head. However, we postulate that similarities between some languages could allow sharing of model parameters and benefit from joint training. Determining language groupings, however, is not immediately obvious. To this end, we propose an automatic method for multilingual text recognition with a task grouping and assignment module using Gumbel-Softmax, introducing a task grouping loss and weighted recognition loss to allow for simultaneous training of the models and grouping modules. Experiments on MLT19 lend evidence to our hypothesis that there is a middle ground between combining every task together and separating every task that achieves a better configuration of task grouping/separation.
Few-shot Learning with Noisy Labels
Apr 12, 2022
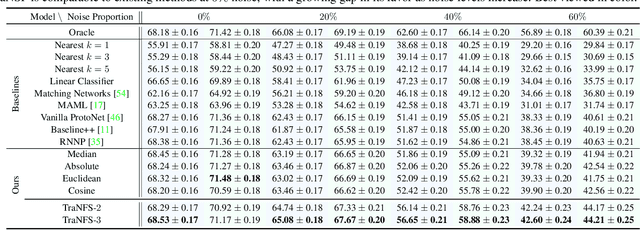
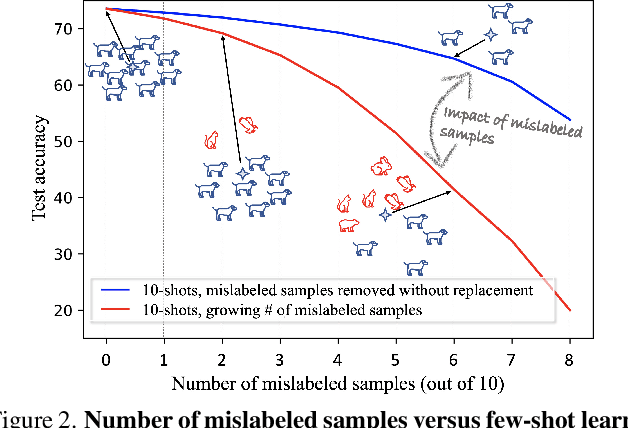

Few-shot learning (FSL) methods typically assume clean support sets with accurately labeled samples when training on novel classes. This assumption can often be unrealistic: support sets, no matter how small, can still include mislabeled samples. Robustness to label noise is therefore essential for FSL methods to be practical, but this problem surprisingly remains largely unexplored. To address mislabeled samples in FSL settings, we make several technical contributions. (1) We offer simple, yet effective, feature aggregation methods, improving the prototypes used by ProtoNet, a popular FSL technique. (2) We describe a novel Transformer model for Noisy Few-Shot Learning (TraNFS). TraNFS leverages a transformer's attention mechanism to weigh mislabeled versus correct samples. (3) Finally, we extensively test these methods on noisy versions of MiniImageNet and TieredImageNet. Our results show that TraNFS is on-par with leading FSL methods on clean support sets, yet outperforms them, by far, in the presence of label noise.
Sylph: A Hypernetwork Framework for Incremental Few-shot Object Detection
Apr 05, 2022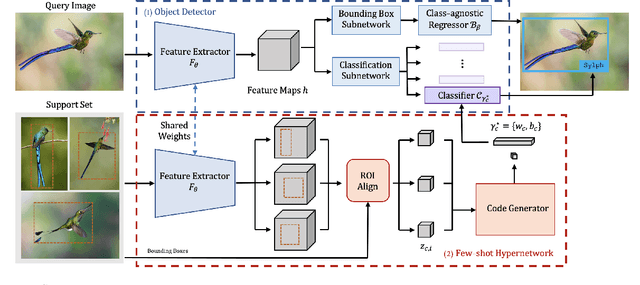
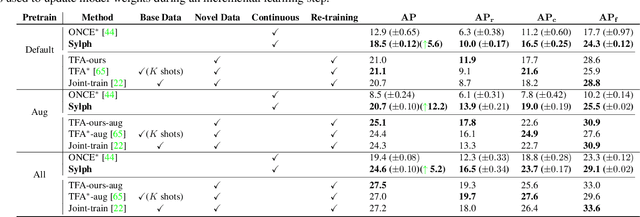
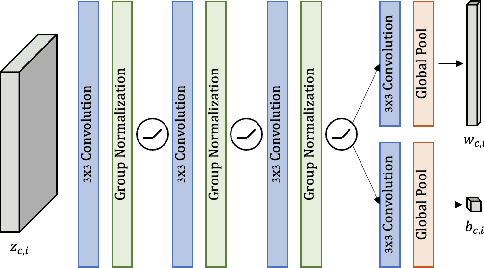
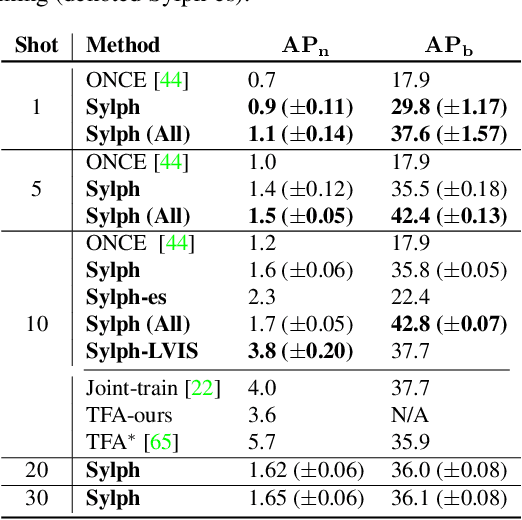
We study the challenging incremental few-shot object detection (iFSD) setting. Recently, hypernetwork-based approaches have been studied in the context of continuous and finetune-free iFSD with limited success. We take a closer look at important design choices of such methods, leading to several key improvements and resulting in a more accurate and flexible framework, which we call Sylph. In particular, we demonstrate the effectiveness of decoupling object classification from localization by leveraging a base detector that is pretrained for class-agnostic localization on a large-scale dataset. Contrary to what previous results have suggested, we show that with a carefully designed class-conditional hypernetwork, finetune-free iFSD can be highly effective, especially when a large number of base categories with abundant data are available for meta-training, almost approaching alternatives that undergo test-time-training. This result is even more significant considering its many practical advantages: (1) incrementally learning new classes in sequence without additional training, (2) detecting both novel and seen classes in a single pass, and (3) no forgetting of previously seen classes. We benchmark our model on both COCO and LVIS, reporting as high as 17% AP on the long-tail rare classes on LVIS, indicating the promise of hypernetwork-based iFSD.