 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGliTr: Glimpse Transformers with Spatiotemporal Consistency for Online Action Prediction
Oct 24, 2022Many online action prediction models observe complete frames to locate and attend to informative subregions in the frames called glimpses and recognize an ongoing action based on global and local information. However, in applications with constrained resources, an agent may not be able to observe the complete frame, yet must still locate useful glimpses to predict an incomplete action based on local information only. In this paper, we develop Glimpse Transformers (GliTr), which observe only narrow glimpses at all times, thus predicting an ongoing action and the following most informative glimpse location based on the partial spatiotemporal information collected so far. In the absence of a ground truth for the optimal glimpse locations for action recognition, we train GliTr using a novel spatiotemporal consistency objective: We require GliTr to attend to the glimpses with features similar to the corresponding complete frames (i.e. spatial consistency) and the resultant class logits at time t equivalent to the ones predicted using whole frames up to t (i.e. temporal consistency). Inclusion of our proposed consistency objective yields ~10% higher accuracy on the Something-Something-v2 (SSv2) dataset than the baseline cross-entropy objective. Overall, despite observing only ~33% of the total area per frame, GliTr achieves 53.02%and 93.91% accuracy on the SSv2 and Jester datasets, respectively.
A deep learning framework for segmentation of retinal layers from OCT images
Jun 22, 2018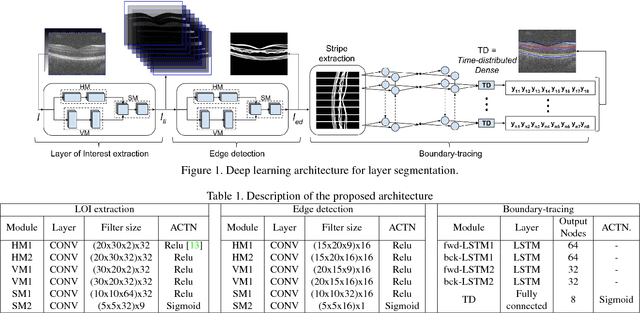
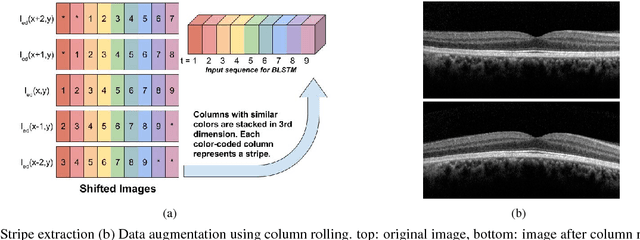
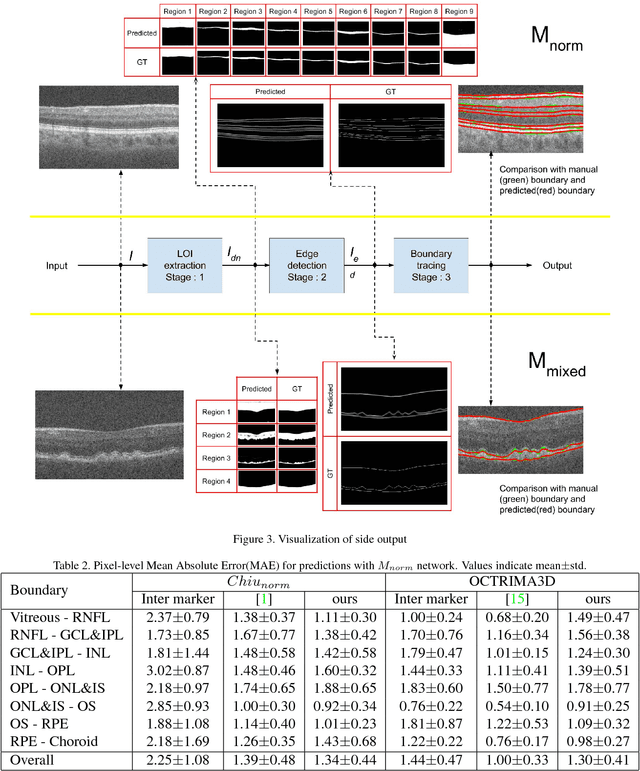
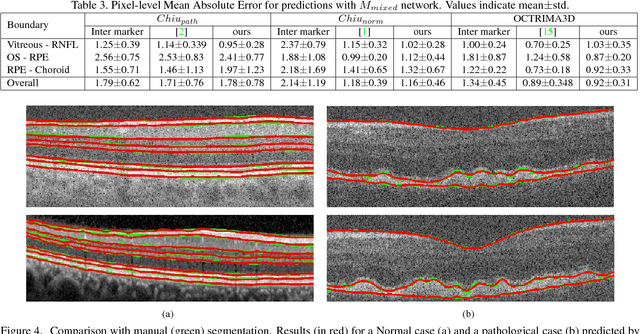
Segmentation of retinal layers from Optical Coherence Tomography (OCT) volumes is a fundamental problem for any computer aided diagnostic algorithm development. This requires preprocessing steps such as denoising, region of interest extraction, flattening and edge detection all of which involve separate parameter tuning. In this paper, we explore deep learning techniques to automate all these steps and handle the presence/absence of pathologies. A model is proposed consisting of a combination of Convolutional Neural Network (CNN) and Long Short Term Memory (LSTM). The CNN is used to extract layers of interest image and extract the edges, while the LSTM is used to trace the layer boundary. This model is trained on a mixture of normal and AMD cases using minimal data. Validation results on three public datasets show that the pixel-wise mean absolute error obtained with our system is 1.30 plus or minus 0.48 which is lower than the inter-marker error of 1.79 plus or minus 0.76. Our model's performance is also on par with the existing methods.