 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerceptionLM: Open-Access Data and Models for Detailed Visual Understanding
Apr 17, 2025



Vision-language models are integral to computer vision research, yet many high-performing models remain closed-source, obscuring their data, design and training recipe. The research community has responded by using distillation from black-box models to label training data, achieving strong benchmark results, at the cost of measurable scientific progress. However, without knowing the details of the teacher model and its data sources, scientific progress remains difficult to measure. In this paper, we study building a Perception Language Model (PLM) in a fully open and reproducible framework for transparent research in image and video understanding. We analyze standard training pipelines without distillation from proprietary models and explore large-scale synthetic data to identify critical data gaps, particularly in detailed video understanding. To bridge these gaps, we release 2.8M human-labeled instances of fine-grained video question-answer pairs and spatio-temporally grounded video captions. Additionally, we introduce PLM-VideoBench, a suite for evaluating challenging video understanding tasks focusing on the ability to reason about "what", "where", "when", and "how" of a video. We make our work fully reproducible by providing data, training recipes, code & models.
Learning Activity View-invariance Under Extreme Viewpoint Changes via Curriculum Knowledge Distillation
Apr 07, 2025



Traditional methods for view-invariant learning from video rely on controlled multi-view settings with minimal scene clutter. However, they struggle with in-the-wild videos that exhibit extreme viewpoint differences and share little visual content. We introduce a method for learning rich video representations in the presence of such severe view-occlusions. We first define a geometry-based metric that ranks views at a fine-grained temporal scale by their likely occlusion level. Then, using those rankings, we formulate a knowledge distillation objective that preserves action-centric semantics with a novel curriculum learning procedure that pairs incrementally more challenging views over time, thereby allowing smooth adaptation to extreme viewpoint differences. We evaluate our approach on two tasks, outperforming SOTA models on both temporal keystep grounding and fine-grained keystep recognition benchmarks - particularly on views that exhibit severe occlusion.
VITED: Video Temporal Evidence Distillation
Mar 17, 2025We investigate complex video question answering via chain-of-evidence reasoning -- identifying sequences of temporal spans from multiple relevant parts of the video, together with visual evidence within them. Existing models struggle with multi-step reasoning as they uniformly sample a fixed number of frames, which can miss critical evidence distributed nonuniformly throughout the video. Moreover, they lack the ability to temporally localize such evidence in the broader context of the full video, which is required for answering complex questions. We propose a framework to enhance existing VideoQA datasets with evidence reasoning chains, automatically constructed by searching for optimal intervals of interest in the video with supporting evidence, that maximizes the likelihood of answering a given question. We train our model (VITED) to generate these evidence chains directly, enabling it to both localize evidence windows as well as perform multi-step reasoning across them in long-form video content. We show the value of our evidence-distilled models on a suite of long video QA benchmarks where we outperform state-of-the-art approaches that lack evidence reasoning capabilities.
BIMBA: Selective-Scan Compression for Long-Range Video Question Answering
Mar 13, 2025Video Question Answering (VQA) in long videos poses the key challenge of extracting relevant information and modeling long-range dependencies from many redundant frames. The self-attention mechanism provides a general solution for sequence modeling, but it has a prohibitive cost when applied to a massive number of spatiotemporal tokens in long videos. Most prior methods rely on compression strategies to lower the computational cost, such as reducing the input length via sparse frame sampling or compressing the output sequence passed to the large language model (LLM) via space-time pooling. However, these naive approaches over-represent redundant information and often miss salient events or fast-occurring space-time patterns. In this work, we introduce BIMBA, an efficient state-space model to handle long-form videos. Our model leverages the selective scan algorithm to learn to effectively select critical information from high-dimensional video and transform it into a reduced token sequence for efficient LLM processing. Extensive experiments demonstrate that BIMBA achieves state-of-the-art accuracy on multiple long-form VQA benchmarks, including PerceptionTest, NExT-QA, EgoSchema, VNBench, LongVideoBench, and Video-MME. Code, and models are publicly available at https://sites.google.com/view/bimba-mllm.
TimeRefine: Temporal Grounding with Time Refining Video LLM
Dec 12, 2024



Video temporal grounding aims to localize relevant temporal boundaries in a video given a textual prompt. Recent work has focused on enabling Video LLMs to perform video temporal grounding via next-token prediction of temporal timestamps. However, accurately localizing timestamps in videos remains challenging for Video LLMs when relying solely on temporal token prediction. Our proposed TimeRefine addresses this challenge in two ways. First, instead of directly predicting the start and end timestamps, we reformulate the temporal grounding task as a temporal refining task: the model first makes rough predictions and then refines them by predicting offsets to the target segment. This refining process is repeated multiple times, through which the model progressively self-improves its temporal localization accuracy. Second, to enhance the model's temporal perception capabilities, we incorporate an auxiliary prediction head that penalizes the model more if a predicted segment deviates further from the ground truth, thus encouraging the model to make closer and more accurate predictions. Our plug-and-play method can be integrated into most LLM-based temporal grounding approaches. The experimental results demonstrate that TimeRefine achieves 3.6% and 5.0% mIoU improvements on the ActivityNet and Charades-STA datasets, respectively. Code and pretrained models will be released.
Semantic Compositions Enhance Vision-Language Contrastive Learning
Jul 01, 2024



In the field of vision-language contrastive learning, models such as CLIP capitalize on matched image-caption pairs as positive examples and leverage within-batch non-matching pairs as negatives. This approach has led to remarkable outcomes in zero-shot image classification, cross-modal retrieval, and linear evaluation tasks. We show that the zero-shot classification and retrieval capabilities of CLIP-like models can be improved significantly through the introduction of semantically composite examples during pretraining. Inspired by CutMix in vision categorization, we create semantically composite image-caption pairs by merging elements from two distinct instances in the dataset via a novel procedure. Our method fuses the captions and blends 50% of each image to form a new composite sample. This simple technique (termed CLIP-C for CLIP Compositions), devoid of any additional computational overhead or increase in model parameters, significantly improves zero-shot image classification and cross-modal retrieval. The benefits of CLIP-C are particularly pronounced in settings with relatively limited pretraining data.
Step Differences in Instructional Video
Apr 24, 2024
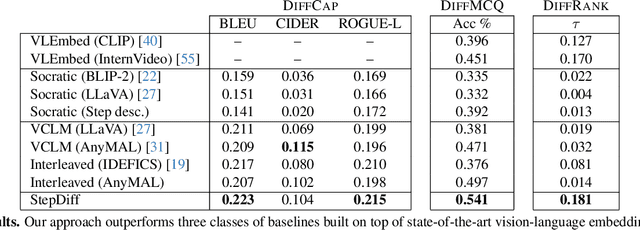


Comparing a user video to a reference how-to video is a key requirement for AR/VR technology delivering personalized assistance tailored to the user's progress. However, current approaches for language-based assistance can only answer questions about a single video. We propose an approach that first automatically generates large amounts of visual instruction tuning data involving pairs of videos from HowTo100M by leveraging existing step annotations and accompanying narrations, and then trains a video-conditioned language model to jointly reason across multiple raw videos. Our model achieves state-of-the-art performance at identifying differences between video pairs and ranking videos based on the severity of these differences, and shows promising ability to perform general reasoning over multiple videos.
Video ReCap: Recursive Captioning of Hour-Long Videos
Feb 28, 2024



Most video captioning models are designed to process short video clips of few seconds and output text describing low-level visual concepts (e.g., objects, scenes, atomic actions). However, most real-world videos last for minutes or hours and have a complex hierarchical structure spanning different temporal granularities. We propose Video ReCap, a recursive video captioning model that can process video inputs of dramatically different lengths (from 1 second to 2 hours) and output video captions at multiple hierarchy levels. The recursive video-language architecture exploits the synergy between different video hierarchies and can process hour-long videos efficiently. We utilize a curriculum learning training scheme to learn the hierarchical structure of videos, starting from clip-level captions describing atomic actions, then focusing on segment-level descriptions, and concluding with generating summaries for hour-long videos. Furthermore, we introduce Ego4D-HCap dataset by augmenting Ego4D with 8,267 manually collected long-range video summaries. Our recursive model can flexibly generate captions at different hierarchy levels while also being useful for other complex video understanding tasks, such as VideoQA on EgoSchema. Data, code, and models are available at: https://sites.google.com/view/vidrecap
Ego-Exo4D: Understanding Skilled Human Activity from First- and Third-Person Perspectives
Nov 30, 2023



We present Ego-Exo4D, a diverse, large-scale multimodal multiview video dataset and benchmark challenge. Ego-Exo4D centers around simultaneously-captured egocentric and exocentric video of skilled human activities (e.g., sports, music, dance, bike repair). More than 800 participants from 13 cities worldwide performed these activities in 131 different natural scene contexts, yielding long-form captures from 1 to 42 minutes each and 1,422 hours of video combined. The multimodal nature of the dataset is unprecedented: the video is accompanied by multichannel audio, eye gaze, 3D point clouds, camera poses, IMU, and multiple paired language descriptions -- including a novel "expert commentary" done by coaches and teachers and tailored to the skilled-activity domain. To push the frontier of first-person video understanding of skilled human activity, we also present a suite of benchmark tasks and their annotations, including fine-grained activity understanding, proficiency estimation, cross-view translation, and 3D hand/body pose. All resources will be open sourced to fuel new research in the community.
Multiscale Video Pretraining for Long-Term Activity Forecasting
Jul 24, 2023Long-term activity forecasting is an especially challenging research problem because it requires understanding the temporal relationships between observed actions, as well as the variability and complexity of human activities. Despite relying on strong supervision via expensive human annotations, state-of-the-art forecasting approaches often generalize poorly to unseen data. To alleviate this issue, we propose Multiscale Video Pretraining (MVP), a novel self-supervised pretraining approach that learns robust representations for forecasting by learning to predict contextualized representations of future video clips over multiple timescales. MVP is based on our observation that actions in videos have a multiscale nature, where atomic actions typically occur at a short timescale and more complex actions may span longer timescales. We compare MVP to state-of-the-art self-supervised video learning approaches on downstream long-term forecasting tasks including long-term action anticipation and video summary prediction. Our comprehensive experiments across the Ego4D and Epic-Kitchens-55/100 datasets demonstrate that MVP out-performs state-of-the-art methods by significant margins. Notably, MVP obtains a relative performance gain of over 20% accuracy in video summary forecasting over existing methods.