 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerceptionLM: Open-Access Data and Models for Detailed Visual Understanding
Apr 17, 2025



Vision-language models are integral to computer vision research, yet many high-performing models remain closed-source, obscuring their data, design and training recipe. The research community has responded by using distillation from black-box models to label training data, achieving strong benchmark results, at the cost of measurable scientific progress. However, without knowing the details of the teacher model and its data sources, scientific progress remains difficult to measure. In this paper, we study building a Perception Language Model (PLM) in a fully open and reproducible framework for transparent research in image and video understanding. We analyze standard training pipelines without distillation from proprietary models and explore large-scale synthetic data to identify critical data gaps, particularly in detailed video understanding. To bridge these gaps, we release 2.8M human-labeled instances of fine-grained video question-answer pairs and spatio-temporally grounded video captions. Additionally, we introduce PLM-VideoBench, a suite for evaluating challenging video understanding tasks focusing on the ability to reason about "what", "where", "when", and "how" of a video. We make our work fully reproducible by providing data, training recipes, code & models.
Ego-Exo4D: Understanding Skilled Human Activity from First- and Third-Person Perspectives
Nov 30, 2023



We present Ego-Exo4D, a diverse, large-scale multimodal multiview video dataset and benchmark challenge. Ego-Exo4D centers around simultaneously-captured egocentric and exocentric video of skilled human activities (e.g., sports, music, dance, bike repair). More than 800 participants from 13 cities worldwide performed these activities in 131 different natural scene contexts, yielding long-form captures from 1 to 42 minutes each and 1,422 hours of video combined. The multimodal nature of the dataset is unprecedented: the video is accompanied by multichannel audio, eye gaze, 3D point clouds, camera poses, IMU, and multiple paired language descriptions -- including a novel "expert commentary" done by coaches and teachers and tailored to the skilled-activity domain. To push the frontier of first-person video understanding of skilled human activity, we also present a suite of benchmark tasks and their annotations, including fine-grained activity understanding, proficiency estimation, cross-view translation, and 3D hand/body pose. All resources will be open sourced to fuel new research in the community.
Learning to Ground Instructional Articles in Videos through Narrations
Jun 06, 2023



In this paper we present an approach for localizing steps of procedural activities in narrated how-to videos. To deal with the scarcity of labeled data at scale, we source the step descriptions from a language knowledge base (wikiHow) containing instructional articles for a large variety of procedural tasks. Without any form of manual supervision, our model learns to temporally ground the steps of procedural articles in how-to videos by matching three modalities: frames, narrations, and step descriptions. Specifically, our method aligns steps to video by fusing information from two distinct pathways: i) {\em direct} alignment of step descriptions to frames, ii) {\em indirect} alignment obtained by composing steps-to-narrations with narrations-to-video correspondences. Notably, our approach performs global temporal grounding of all steps in an article at once by exploiting order information, and is trained with step pseudo-labels which are iteratively refined and aggressively filtered. In order to validate our model we introduce a new evaluation benchmark -- HT-Step -- obtained by manually annotating a 124-hour subset of HowTo100M\footnote{A test server is accessible at \url{https://eval.ai/web/challenges/challenge-page/2082}.} with steps sourced from wikiHow articles. Experiments on this benchmark as well as zero-shot evaluations on CrossTask demonstrate that our multi-modality alignment yields dramatic gains over several baselines and prior works. Finally, we show that our inner module for matching narration-to-video outperforms by a large margin the state of the art on the HTM-Align narration-video alignment benchmark.
MINOTAUR: Multi-task Video Grounding From Multimodal Queries
Feb 16, 2023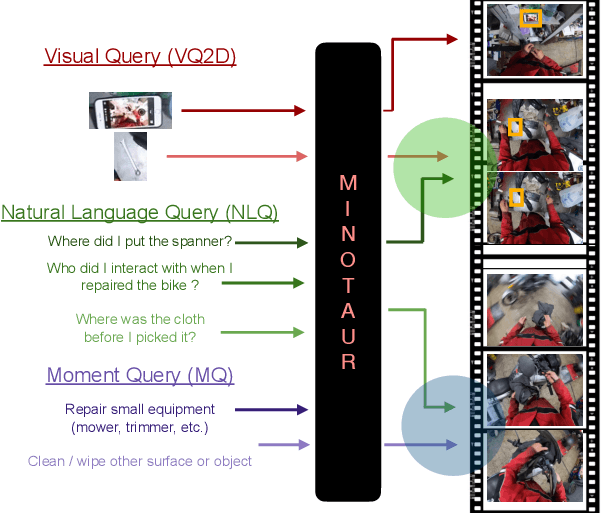

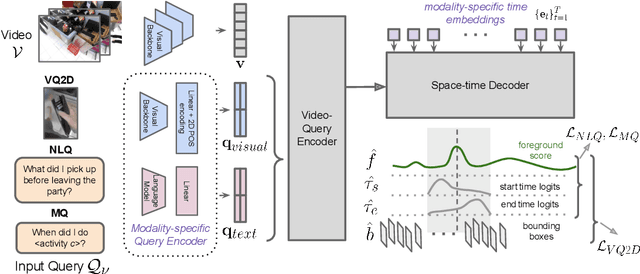
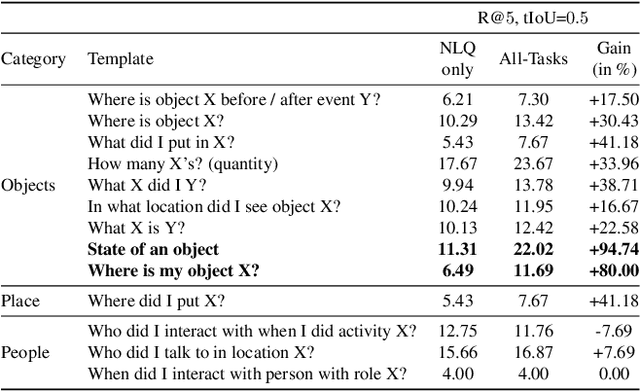
Video understanding tasks take many forms, from action detection to visual query localization and spatio-temporal grounding of sentences. These tasks differ in the type of inputs (only video, or video-query pair where query is an image region or sentence) and outputs (temporal segments or spatio-temporal tubes). However, at their core they require the same fundamental understanding of the video, i.e., the actors and objects in it, their actions and interactions. So far these tasks have been tackled in isolation with individual, highly specialized architectures, which do not exploit the interplay between tasks. In contrast, in this paper, we present a single, unified model for tackling query-based video understanding in long-form videos. In particular, our model can address all three tasks of the Ego4D Episodic Memory benchmark which entail queries of three different forms: given an egocentric video and a visual, textual or activity query, the goal is to determine when and where the answer can be seen within the video. Our model design is inspired by recent query-based approaches to spatio-temporal grounding, and contains modality-specific query encoders and task-specific sliding window inference that allow multi-task training with diverse input modalities and different structured outputs. We exhaustively analyze relationships among the tasks and illustrate that cross-task learning leads to improved performance on each individual task, as well as the ability to generalize to unseen tasks, such as zero-shot spatial localization of language queries.
Neural Message Passing on Hybrid Spatio-Temporal Visual and Symbolic Graphs for Video Understanding
May 17, 2019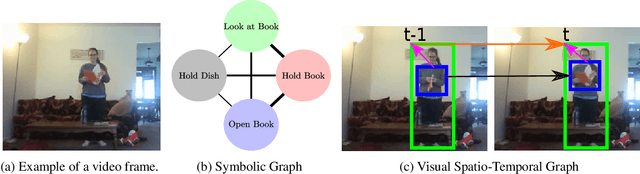
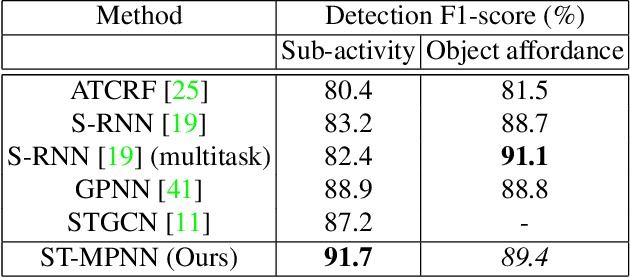
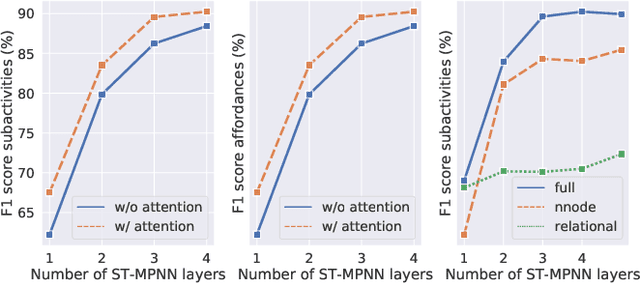
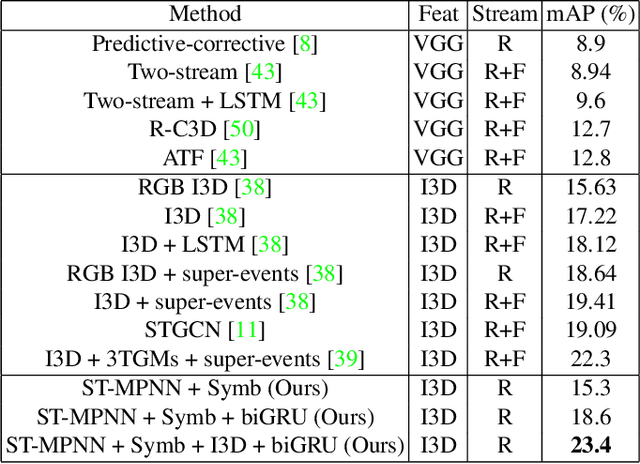
Many problems in video understanding require labeling multiple activities occurring concurrently in different parts of a video, including the objects and actors participating in such activities. However, state-of-the-art methods in computer vision focus primarily on tasks such as action classification, action detection, or action segmentation, where typically only one action label needs to be predicted. In this work, we propose a generic approach to classifying one or more nodes of a spatio-temporal graph grounded on spatially localized semantic entities in a video, such as actors and objects. In particular, we combine an attributed spatio-temporal visual graph, which captures visual context and interactions, with an attributed symbolic graph grounded on the semantic label space, which captures relationships between multiple labels. We further propose a neural message passing framework for jointly refining the representations of the nodes and edges of the hybrid visual-symbolic graph. Our framework features a) node-type and edge-type conditioned filters and adaptive graph connectivity, b) a soft-assignment module for connecting visual nodes to symbolic nodes and vice versa, c) a symbolic graph reasoning module that enforces semantic coherence and d) a pooling module for aggregating the refined node and edge representations for downstream classification tasks. We demonstrate the generality of our approach on a variety of tasks, such as temporal subactivity classification and object affordance classification on the CAD-120 dataset and multilabel temporal action localization on the large scale Charades dataset, where we outperform existing deep learning approaches, using only raw RGB frames.
End-to-End Fine-Grained Action Segmentation and Recognition Using Conditional Random Field Models and Discriminative Sparse Coding
Jan 29, 2018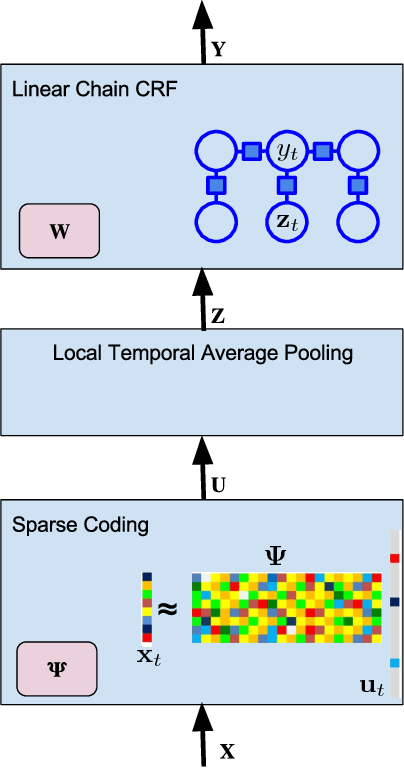
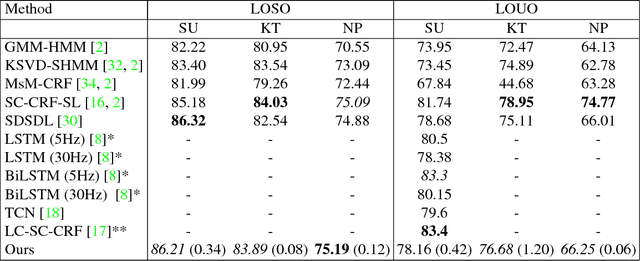
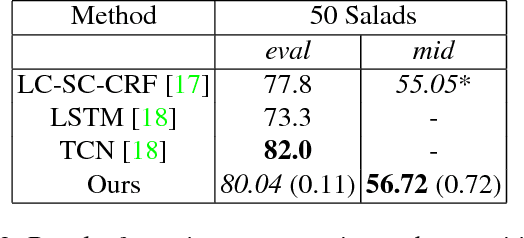
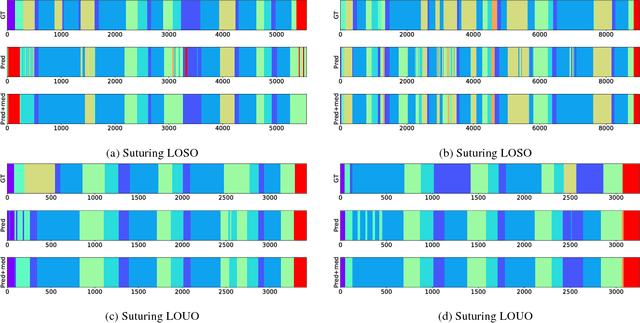
Fine-grained action segmentation and recognition is an important yet challenging task. Given a long, untrimmed sequence of kinematic data, the task is to classify the action at each time frame and segment the time series into the correct sequence of actions. In this paper, we propose a novel framework that combines a temporal Conditional Random Field (CRF) model with a powerful frame-level representation based on discriminative sparse coding. We introduce an end-to-end algorithm for jointly learning the weights of the CRF model, which include action classification and action transition costs, as well as an overcomplete dictionary of mid-level action primitives. This results in a CRF model that is driven by sparse coding features obtained using a discriminative dictionary that is shared among different actions and adapted to the task of structured output learning. We evaluate our method on three surgical tasks using kinematic data from the JIGSAWS dataset, as well as on a food preparation task using accelerometer data from the 50 Salads dataset. Our results show that the proposed method performs on par or better than state-of-the-art methods.