 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Message Passing on Hybrid Spatio-Temporal Visual and Symbolic Graphs for Video Understanding
Paper and Code
May 17, 2019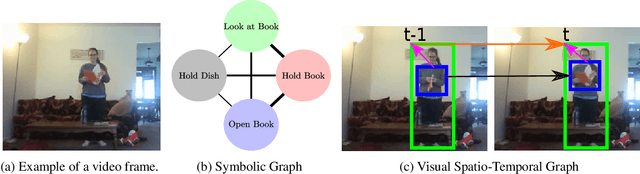
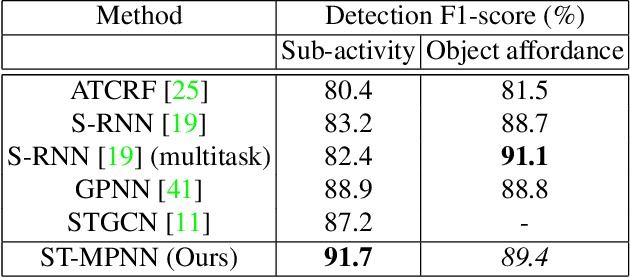
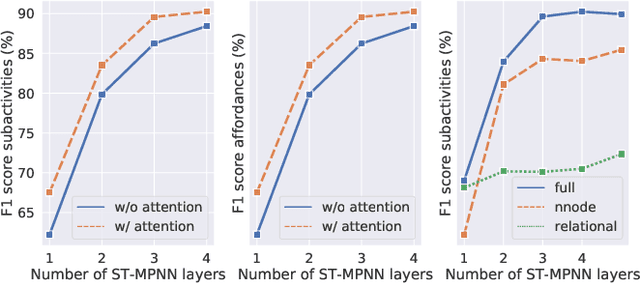
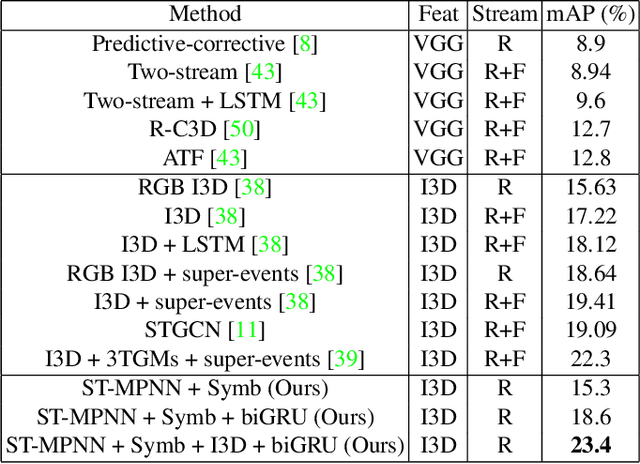
Many problems in video understanding require labeling multiple activities occurring concurrently in different parts of a video, including the objects and actors participating in such activities. However, state-of-the-art methods in computer vision focus primarily on tasks such as action classification, action detection, or action segmentation, where typically only one action label needs to be predicted. In this work, we propose a generic approach to classifying one or more nodes of a spatio-temporal graph grounded on spatially localized semantic entities in a video, such as actors and objects. In particular, we combine an attributed spatio-temporal visual graph, which captures visual context and interactions, with an attributed symbolic graph grounded on the semantic label space, which captures relationships between multiple labels. We further propose a neural message passing framework for jointly refining the representations of the nodes and edges of the hybrid visual-symbolic graph. Our framework features a) node-type and edge-type conditioned filters and adaptive graph connectivity, b) a soft-assignment module for connecting visual nodes to symbolic nodes and vice versa, c) a symbolic graph reasoning module that enforces semantic coherence and d) a pooling module for aggregating the refined node and edge representations for downstream classification tasks. We demonstrate the generality of our approach on a variety of tasks, such as temporal subactivity classification and object affordance classification on the CAD-120 dataset and multilabel temporal action localization on the large scale Charades dataset, where we outperform existing deep learning approaches, using only raw RGB frames.