 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Channel Unlabeled Sensing over a Union of Signal Subspaces
Jun 11, 2025Cross-channel unlabeled sensing addresses the problem of recovering a multi-channel signal from measurements that were shuffled across channels. This work expands the cross-channel unlabeled sensing framework to signals that lie in a union of subspaces. The extension allows for handling more complex signal structures and broadens the framework to tasks like compressed sensing. These mismatches between samples and channels often arise in applications such as whole-brain calcium imaging of freely moving organisms or multi-target tracking. We improve over previous models by deriving tighter bounds on the required number of samples for unique reconstruction, while supporting more general signal types. The approach is validated through an application in whole-brain calcium imaging, where organism movements disrupt sample-to-neuron mappings. This demonstrates the utility of our framework in real-world settings with imprecise sample-channel associations, achieving accurate signal reconstruction.
* Accepted to ICASSP 2025. \copyright 2025 IEEE. Personal use of this material is permitted
Reconstruction of Multivariate Sparse Signals from Mismatched Samples
Dec 21, 2022



Erroneous correspondences between samples and their respective channel or target commonly arise in several real-world applications. For instance, whole-brain calcium imaging of freely moving organisms, multiple target tracking or multi-person contactless vital sign monitoring may be severely affected by mismatched sample-channel assignments. To systematically address this fundamental problem, we pose it as a signal reconstruction problem where we have lost correspondences between the samples and their respective channels. We show that under the assumption that the signals of interest admit a sparse representation over an overcomplete dictionary, unique signal recovery is possible. Our derivations reveal that the problem is equivalent to a structured unlabeled sensing problem without precise knowledge of the sensing matrix. Unfortunately, existing methods are neither robust to errors in the regressors nor do they exploit the structure of the problem. Therefore, we propose a novel robust two-step approach for the reconstruction of shuffled sparse signals. The performance and robustness of the proposed approach is illustrated in an application of whole-brain calcium imaging in computational neuroscience. The proposed framework can be generalized to sparse signal representations other than the ones considered in this work to be applied in a variety of real-world problems with imprecise measurement or channel assignment.
Neural Message Passing on Hybrid Spatio-Temporal Visual and Symbolic Graphs for Video Understanding
May 17, 2019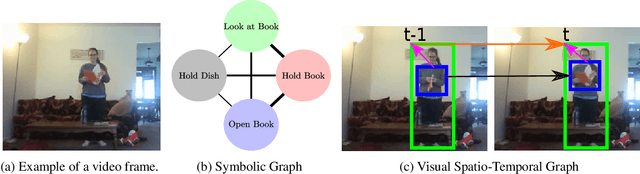
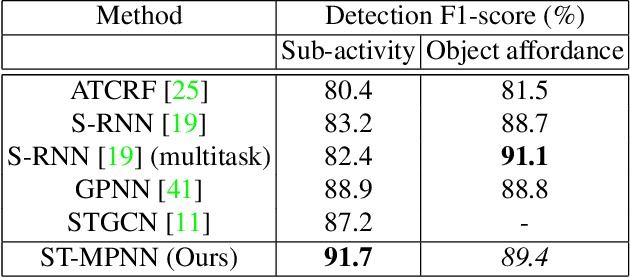
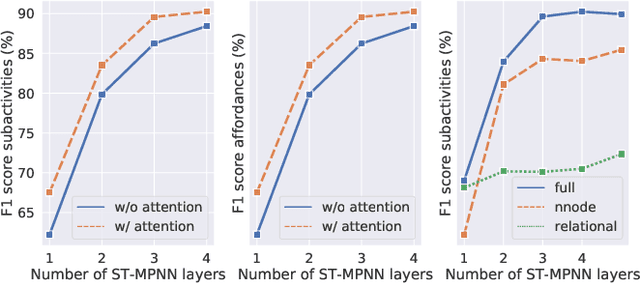
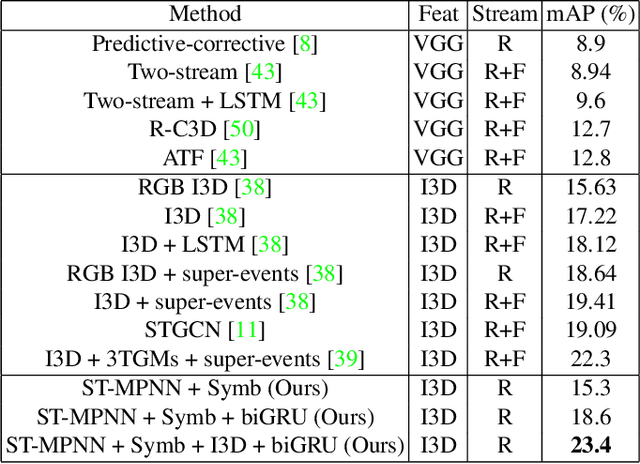
Many problems in video understanding require labeling multiple activities occurring concurrently in different parts of a video, including the objects and actors participating in such activities. However, state-of-the-art methods in computer vision focus primarily on tasks such as action classification, action detection, or action segmentation, where typically only one action label needs to be predicted. In this work, we propose a generic approach to classifying one or more nodes of a spatio-temporal graph grounded on spatially localized semantic entities in a video, such as actors and objects. In particular, we combine an attributed spatio-temporal visual graph, which captures visual context and interactions, with an attributed symbolic graph grounded on the semantic label space, which captures relationships between multiple labels. We further propose a neural message passing framework for jointly refining the representations of the nodes and edges of the hybrid visual-symbolic graph. Our framework features a) node-type and edge-type conditioned filters and adaptive graph connectivity, b) a soft-assignment module for connecting visual nodes to symbolic nodes and vice versa, c) a symbolic graph reasoning module that enforces semantic coherence and d) a pooling module for aggregating the refined node and edge representations for downstream classification tasks. We demonstrate the generality of our approach on a variety of tasks, such as temporal subactivity classification and object affordance classification on the CAD-120 dataset and multilabel temporal action localization on the large scale Charades dataset, where we outperform existing deep learning approaches, using only raw RGB frames.