 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerceptionLM: Open-Access Data and Models for Detailed Visual Understanding
Apr 17, 2025



Vision-language models are integral to computer vision research, yet many high-performing models remain closed-source, obscuring their data, design and training recipe. The research community has responded by using distillation from black-box models to label training data, achieving strong benchmark results, at the cost of measurable scientific progress. However, without knowing the details of the teacher model and its data sources, scientific progress remains difficult to measure. In this paper, we study building a Perception Language Model (PLM) in a fully open and reproducible framework for transparent research in image and video understanding. We analyze standard training pipelines without distillation from proprietary models and explore large-scale synthetic data to identify critical data gaps, particularly in detailed video understanding. To bridge these gaps, we release 2.8M human-labeled instances of fine-grained video question-answer pairs and spatio-temporally grounded video captions. Additionally, we introduce PLM-VideoBench, a suite for evaluating challenging video understanding tasks focusing on the ability to reason about "what", "where", "when", and "how" of a video. We make our work fully reproducible by providing data, training recipes, code & models.
Reading to Listen at the Cocktail Party: Multi-Modal Speech Separation
Jan 02, 2025The goal of this paper is speech separation and enhancement in multi-speaker and noisy environments using a combination of different modalities. Previous works have shown good performance when conditioning on temporal or static visual evidence such as synchronised lip movements or face identity. In this paper, we present a unified framework for multi-modal speech separation and enhancement based on synchronous or asynchronous cues. To that end we make the following contributions: (i) we design a modern Transformer-based architecture tailored to fuse different modalities to solve the speech separation task in the raw waveform domain; (ii) we propose conditioning on the textual content of a sentence alone or in combination with visual information; (iii) we demonstrate the robustness of our model to audio-visual synchronisation offsets; and, (iv) we obtain state-of-the-art performance on the well-established benchmark datasets LRS2 and LRS3.
VoiceVector: Multimodal Enrolment Vectors for Speaker Separation
Jan 02, 2025



We present a transformer-based architecture for voice separation of a target speaker from multiple other speakers and ambient noise. We achieve this by using two separate neural networks: (A) An enrolment network designed to craft speaker-specific embeddings, exploiting various combinations of audio and visual modalities; and (B) A separation network that accepts both the noisy signal and enrolment vectors as inputs, outputting the clean signal of the target speaker. The novelties are: (i) the enrolment vector can be produced from: audio only, audio-visual data (using lip movements) or visual data alone (using lip movements from silent video); and (ii) the flexibility in conditioning the separation on multiple positive and negative enrolment vectors. We compare with previous methods and obtain superior performance.
MusicFlow: Cascaded Flow Matching for Text Guided Music Generation
Oct 27, 2024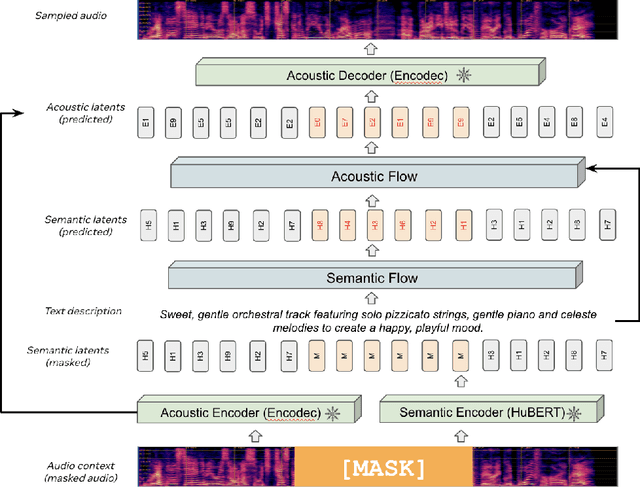
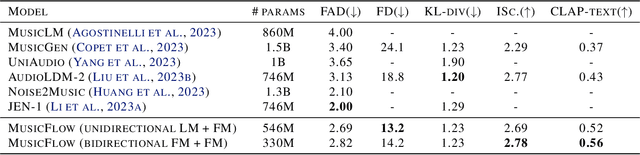
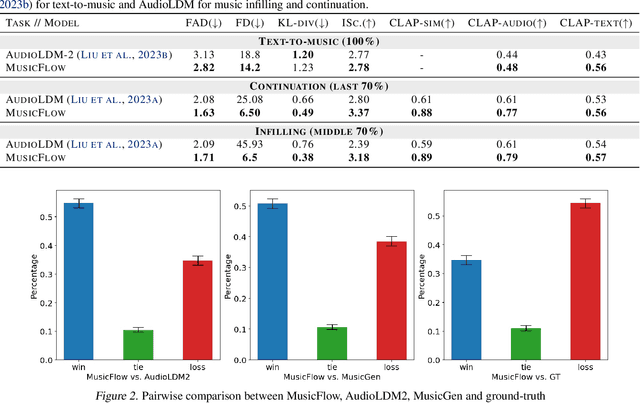
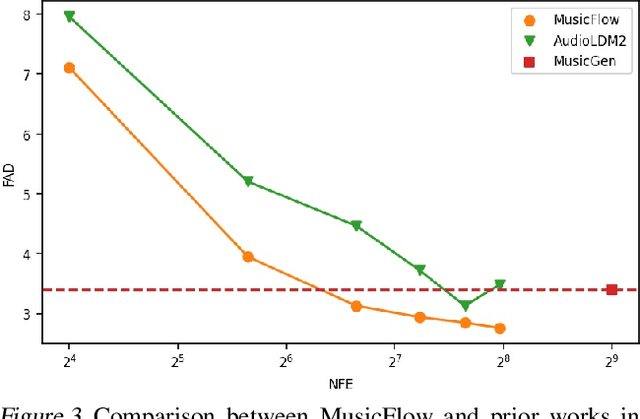
We introduce MusicFlow, a cascaded text-to-music generation model based on flow matching. Based on self-supervised representations to bridge between text descriptions and music audios, we construct two flow matching networks to model the conditional distribution of semantic and acoustic features. Additionally, we leverage masked prediction as the training objective, enabling the model to generalize to other tasks such as music infilling and continuation in a zero-shot manner. Experiments on MusicCaps reveal that the music generated by MusicFlow exhibits superior quality and text coherence despite being over $2\sim5$ times smaller and requiring $5$ times fewer iterative steps. Simultaneously, the model can perform other music generation tasks and achieves competitive performance in music infilling and continuation. Our code and model will be publicly available.
Ego-Exo4D: Understanding Skilled Human Activity from First- and Third-Person Perspectives
Nov 30, 2023



We present Ego-Exo4D, a diverse, large-scale multimodal multiview video dataset and benchmark challenge. Ego-Exo4D centers around simultaneously-captured egocentric and exocentric video of skilled human activities (e.g., sports, music, dance, bike repair). More than 800 participants from 13 cities worldwide performed these activities in 131 different natural scene contexts, yielding long-form captures from 1 to 42 minutes each and 1,422 hours of video combined. The multimodal nature of the dataset is unprecedented: the video is accompanied by multichannel audio, eye gaze, 3D point clouds, camera poses, IMU, and multiple paired language descriptions -- including a novel "expert commentary" done by coaches and teachers and tailored to the skilled-activity domain. To push the frontier of first-person video understanding of skilled human activity, we also present a suite of benchmark tasks and their annotations, including fine-grained activity understanding, proficiency estimation, cross-view translation, and 3D hand/body pose. All resources will be open sourced to fuel new research in the community.
Video-Mined Task Graphs for Keystep Recognition in Instructional Videos
Jul 17, 2023



Procedural activity understanding requires perceiving human actions in terms of a broader task, where multiple keysteps are performed in sequence across a long video to reach a final goal state -- such as the steps of a recipe or a DIY fix-it task. Prior work largely treats keystep recognition in isolation of this broader structure, or else rigidly confines keysteps to align with a predefined sequential script. We propose discovering a task graph automatically from how-to videos to represent probabilistically how people tend to execute keysteps, and then leverage this graph to regularize keystep recognition in novel videos. On multiple datasets of real-world instructional videos, we show the impact: more reliable zero-shot keystep localization and improved video representation learning, exceeding the state of the art.
Learning to Ground Instructional Articles in Videos through Narrations
Jun 06, 2023



In this paper we present an approach for localizing steps of procedural activities in narrated how-to videos. To deal with the scarcity of labeled data at scale, we source the step descriptions from a language knowledge base (wikiHow) containing instructional articles for a large variety of procedural tasks. Without any form of manual supervision, our model learns to temporally ground the steps of procedural articles in how-to videos by matching three modalities: frames, narrations, and step descriptions. Specifically, our method aligns steps to video by fusing information from two distinct pathways: i) {\em direct} alignment of step descriptions to frames, ii) {\em indirect} alignment obtained by composing steps-to-narrations with narrations-to-video correspondences. Notably, our approach performs global temporal grounding of all steps in an article at once by exploiting order information, and is trained with step pseudo-labels which are iteratively refined and aggressively filtered. In order to validate our model we introduce a new evaluation benchmark -- HT-Step -- obtained by manually annotating a 124-hour subset of HowTo100M\footnote{A test server is accessible at \url{https://eval.ai/web/challenges/challenge-page/2082}.} with steps sourced from wikiHow articles. Experiments on this benchmark as well as zero-shot evaluations on CrossTask demonstrate that our multi-modality alignment yields dramatic gains over several baselines and prior works. Finally, we show that our inner module for matching narration-to-video outperforms by a large margin the state of the art on the HTM-Align narration-video alignment benchmark.
Scaling up sign spotting through sign language dictionaries
May 09, 2022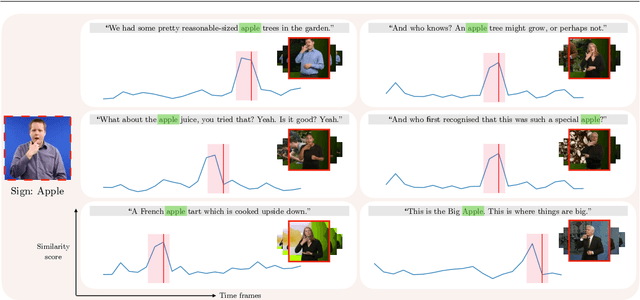
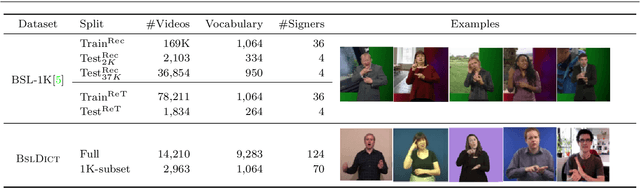
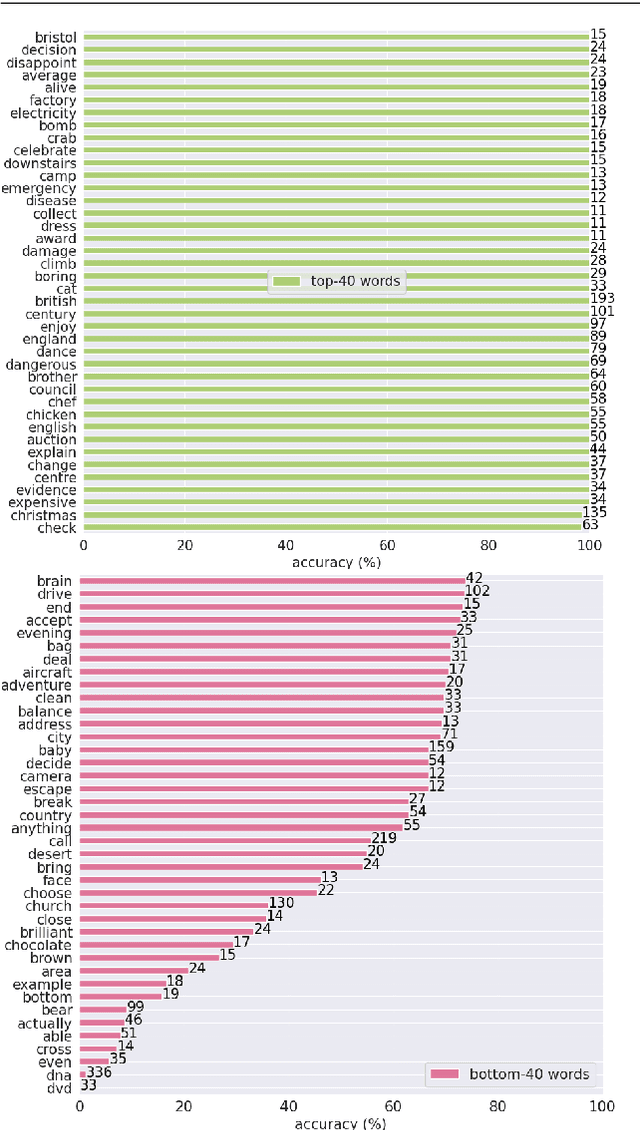
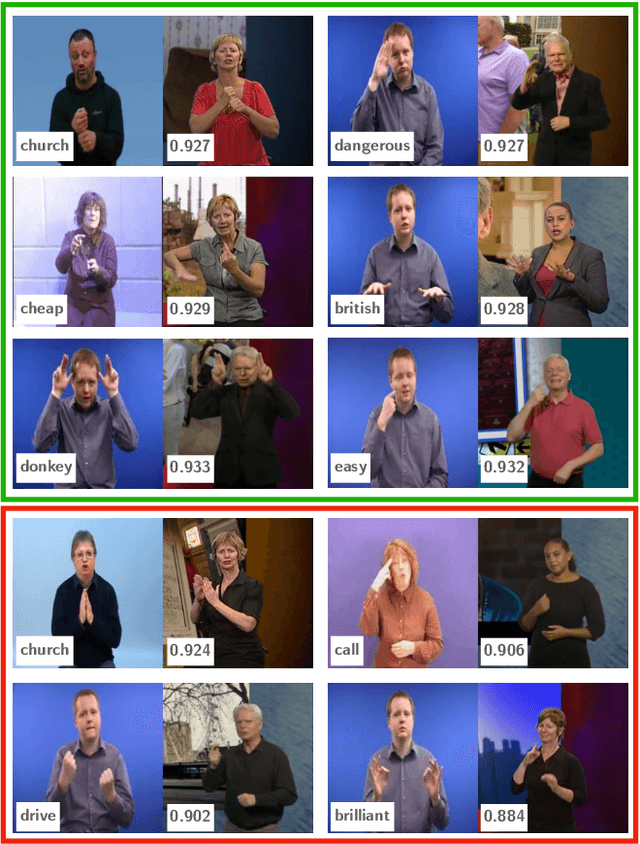
The focus of this work is $\textit{sign spotting}$ - given a video of an isolated sign, our task is to identify $\textit{whether}$ and $\textit{where}$ it has been signed in a continuous, co-articulated sign language video. To achieve this sign spotting task, we train a model using multiple types of available supervision by: (1) $\textit{watching}$ existing footage which is sparsely labelled using mouthing cues; (2) $\textit{reading}$ associated subtitles (readily available translations of the signed content) which provide additional $\textit{weak-supervision}$; (3) $\textit{looking up}$ words (for which no co-articulated labelled examples are available) in visual sign language dictionaries to enable novel sign spotting. These three tasks are integrated into a unified learning framework using the principles of Noise Contrastive Estimation and Multiple Instance Learning. We validate the effectiveness of our approach on low-shot sign spotting benchmarks. In addition, we contribute a machine-readable British Sign Language (BSL) dictionary dataset of isolated signs, BSLDict, to facilitate study of this task. The dataset, models and code are available at our project page.
* Appears in: 2022 International Journal of Computer Vision (IJCV). 25 pages. arXiv admin note: substantial text overlap with arXiv:2010.04002
Audio-Visual Synchronisation in the wild
Dec 08, 2021

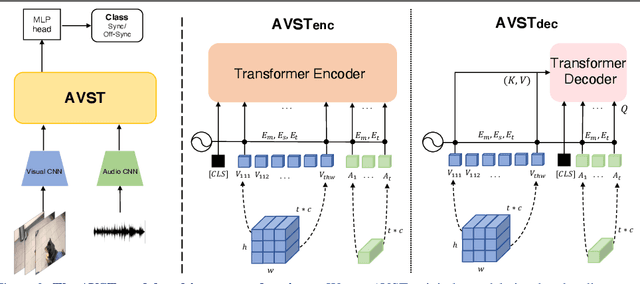
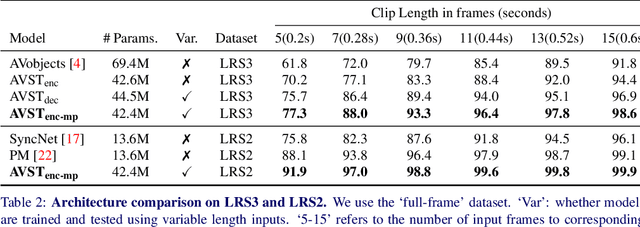
In this paper, we consider the problem of audio-visual synchronisation applied to videos `in-the-wild' (ie of general classes beyond speech). As a new task, we identify and curate a test set with high audio-visual correlation, namely VGG-Sound Sync. We compare a number of transformer-based architectural variants specifically designed to model audio and visual signals of arbitrary length, while significantly reducing memory requirements during training. We further conduct an in-depth analysis on the curated dataset and define an evaluation metric for open domain audio-visual synchronisation. We apply our method on standard lip reading speech benchmarks, LRS2 and LRS3, with ablations on various aspects. Finally, we set the first benchmark for general audio-visual synchronisation with over 160 diverse classes in the new VGG-Sound Sync video dataset. In all cases, our proposed model outperforms the previous state-of-the-art by a significant margin.
BBC-Oxford British Sign Language Dataset
Nov 05, 2021

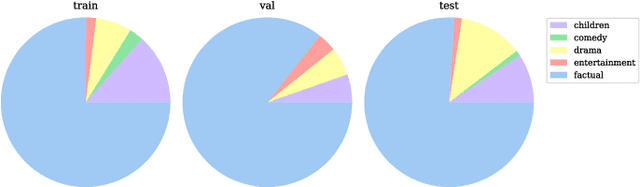
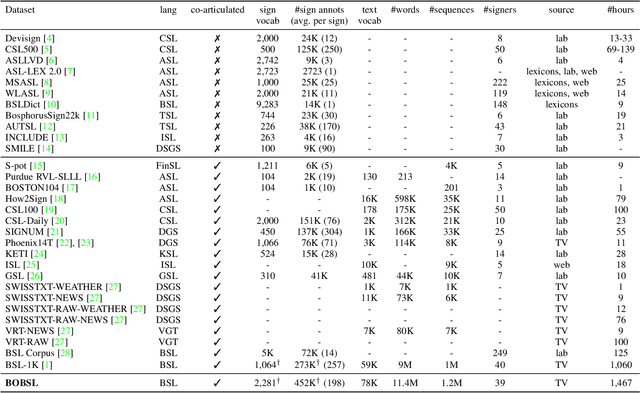
In this work, we introduce the BBC-Oxford British Sign Language (BOBSL) dataset, a large-scale video collection of British Sign Language (BSL). BOBSL is an extended and publicly released dataset based on the BSL-1K dataset introduced in previous work. We describe the motivation for the dataset, together with statistics and available annotations. We conduct experiments to provide baselines for the tasks of sign recognition, sign language alignment, and sign language translation. Finally, we describe several strengths and limitations of the data from the perspectives of machine learning and linguistics, note sources of bias present in the dataset, and discuss potential applications of BOBSL in the context of sign language technology. The dataset is available at https://www.robots.ox.ac.uk/~vgg/data/bobsl/.