 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling up sign spotting through sign language dictionaries
Paper and Code
May 09, 2022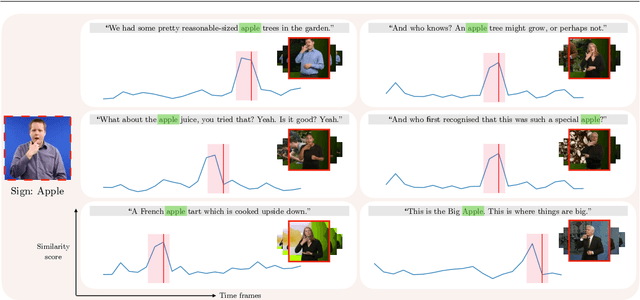
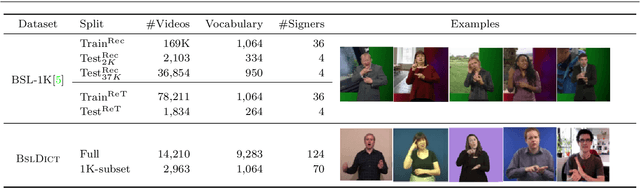
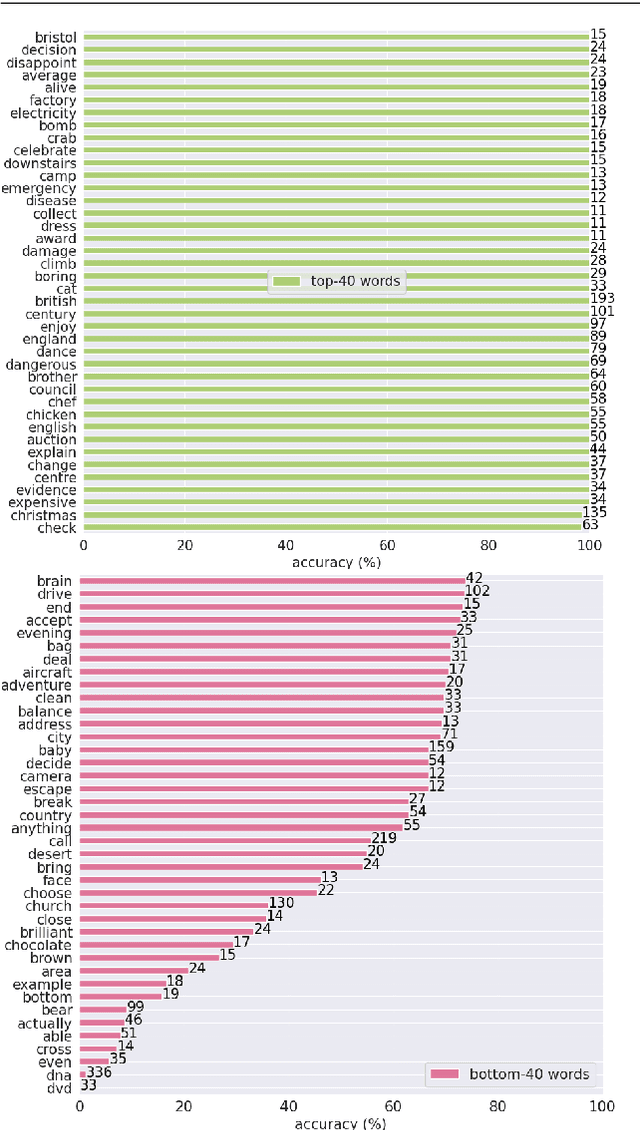
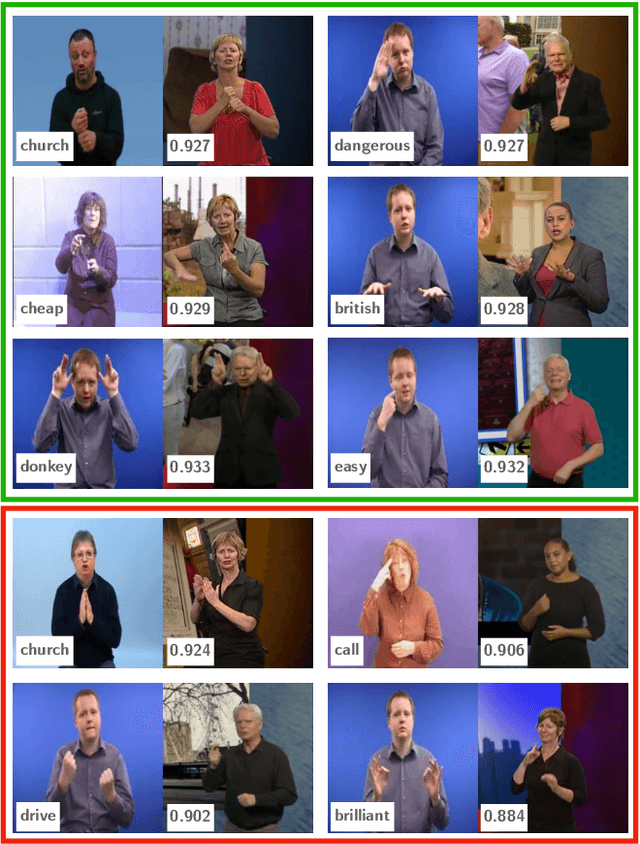
The focus of this work is $\textit{sign spotting}$ - given a video of an isolated sign, our task is to identify $\textit{whether}$ and $\textit{where}$ it has been signed in a continuous, co-articulated sign language video. To achieve this sign spotting task, we train a model using multiple types of available supervision by: (1) $\textit{watching}$ existing footage which is sparsely labelled using mouthing cues; (2) $\textit{reading}$ associated subtitles (readily available translations of the signed content) which provide additional $\textit{weak-supervision}$; (3) $\textit{looking up}$ words (for which no co-articulated labelled examples are available) in visual sign language dictionaries to enable novel sign spotting. These three tasks are integrated into a unified learning framework using the principles of Noise Contrastive Estimation and Multiple Instance Learning. We validate the effectiveness of our approach on low-shot sign spotting benchmarks. In addition, we contribute a machine-readable British Sign Language (BSL) dictionary dataset of isolated signs, BSLDict, to facilitate study of this task. The dataset, models and code are available at our project page.