 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
MusicFlow: Cascaded Flow Matching for Text Guided Music Generation
Oct 27, 2024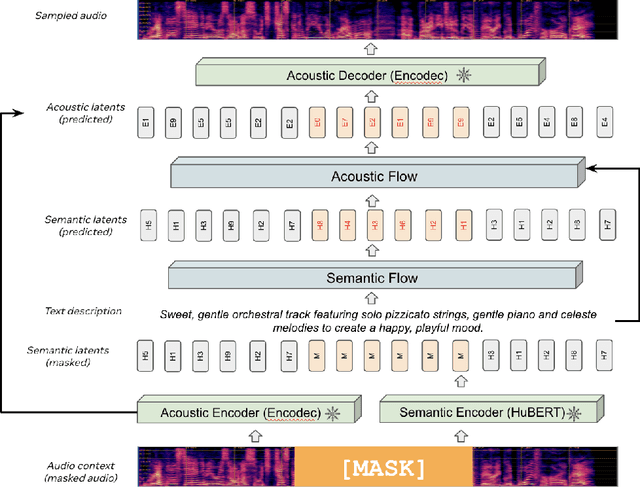
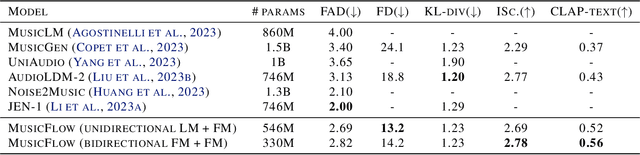
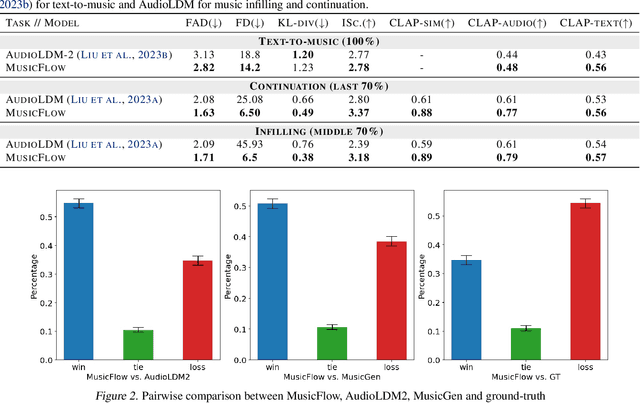
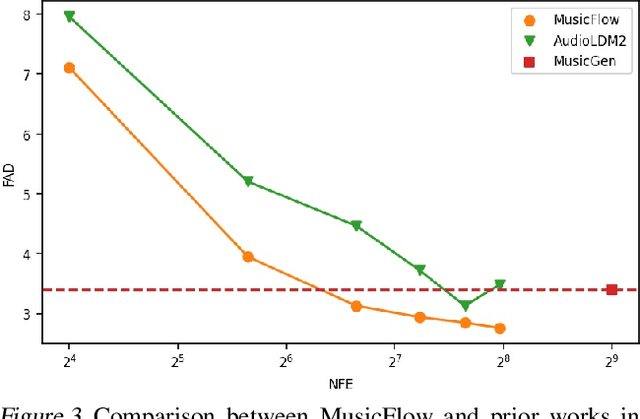
We introduce MusicFlow, a cascaded text-to-music generation model based on flow matching. Based on self-supervised representations to bridge between text descriptions and music audios, we construct two flow matching networks to model the conditional distribution of semantic and acoustic features. Additionally, we leverage masked prediction as the training objective, enabling the model to generalize to other tasks such as music infilling and continuation in a zero-shot manner. Experiments on MusicCaps reveal that the music generated by MusicFlow exhibits superior quality and text coherence despite being over $2\sim5$ times smaller and requiring $5$ times fewer iterative steps. Simultaneously, the model can perform other music generation tasks and achieves competitive performance in music infilling and continuation. Our code and model will be publicly available.
High Fidelity Text-Guided Music Generation and Editing via Single-Stage Flow Matching
Jul 04, 2024



We introduce a simple and efficient text-controllable high-fidelity music generation and editing model. It operates on sequences of continuous latent representations from a low frame rate 48 kHz stereo variational auto encoder codec that eliminates the information loss drawback of discrete representations. Based on a diffusion transformer architecture trained on a flow-matching objective the model can generate and edit diverse high quality stereo samples of variable duration, with simple text descriptions. We also explore a new regularized latent inversion method for zero-shot test-time text-guided editing and demonstrate its superior performance over naive denoising diffusion implicit model (DDIM) inversion for variety of music editing prompts. Evaluations are conducted on both objective and subjective metrics and demonstrate that the proposed model is not only competitive to the evaluated baselines on a standard text-to-music benchmark - quality and efficiency-wise - but also outperforms previous state of the art for music editing when combined with our proposed latent inversion. Samples are available at https://melodyflow.github.io.
In-Context Prompt Editing For Conditional Audio Generation
Nov 01, 2023Distributional shift is a central challenge in the deployment of machine learning models as they can be ill-equipped for real-world data. This is particularly evident in text-to-audio generation where the encoded representations are easily undermined by unseen prompts, which leads to the degradation of generated audio -- the limited set of the text-audio pairs remains inadequate for conditional audio generation in the wild as user prompts are under-specified. In particular, we observe a consistent audio quality degradation in generated audio samples with user prompts, as opposed to training set prompts. To this end, we present a retrieval-based in-context prompt editing framework that leverages the training captions as demonstrative exemplars to revisit the user prompts. We show that the framework enhanced the audio quality across the set of collected user prompts, which were edited with reference to the training captions as exemplars.
Stack-and-Delay: a new codebook pattern for music generation
Sep 15, 2023In language modeling based music generation, a generated waveform is represented by a sequence of hierarchical token stacks that can be decoded either in an auto-regressive manner or in parallel, depending on the codebook patterns. In particular, flattening the codebooks represents the highest quality decoding strategy, while being notoriously slow. To this end, we propose a novel stack-and-delay style of decoding strategy to improve upon the flat pattern decoding where generation speed is four times faster as opposed to vanilla flat decoding. This brings the inference time close to that of the delay decoding strategy, and allows for faster inference on GPU for small batch sizes. For the same inference efficiency budget as the delay pattern, we show that the proposed approach performs better in objective evaluations, almost closing the gap with the flat pattern in terms of quality. The results are corroborated by subjective evaluations which show that samples generated by the new model are slightly more often preferred to samples generated by the competing model given the same text prompts.
Simple and Controllable Music Generation
Jun 08, 2023We tackle the task of conditional music generation. We introduce MusicGen, a single Language Model (LM) that operates over several streams of compressed discrete music representation, i.e., tokens. Unlike prior work, MusicGen is comprised of a single-stage transformer LM together with efficient token interleaving patterns, which eliminates the need for cascading several models, e.g., hierarchically or upsampling. Following this approach, we demonstrate how MusicGen can generate high-quality samples, while being conditioned on textual description or melodic features, allowing better controls over the generated output. We conduct extensive empirical evaluation, considering both automatic and human studies, showing the proposed approach is superior to the evaluated baselines on a standard text-to-music benchmark. Through ablation studies, we shed light over the importance of each of the components comprising MusicGen. Music samples, code, and models are available at https://github.com/facebookresearch/audiocraft.
Self-Supervised Representations for Singing Voice Conversion
Mar 21, 2023A singing voice conversion model converts a song in the voice of an arbitrary source singer to the voice of a target singer. Recently, methods that leverage self-supervised audio representations such as HuBERT and Wav2Vec 2.0 have helped further the state-of-the-art. Though these methods produce more natural and melodic singing outputs, they often rely on confusion and disentanglement losses to render the self-supervised representations speaker and pitch-invariant. In this paper, we circumvent disentanglement training and propose a new model that leverages ASR fine-tuned self-supervised representations as inputs to a HiFi-GAN neural vocoder for singing voice conversion. We experiment with different f0 encoding schemes and show that an f0 harmonic generation module that uses a parallel bank of transposed convolutions (PBTC) alongside ASR fine-tuned Wav2Vec 2.0 features results in the best singing voice conversion quality. Additionally, the model is capable of making a spoken voice sing. We also show that a simple f0 shifting scheme during inference helps retain singer identity and bolsters the performance of our singing voice conversion model. Our results are backed up by extensive MOS studies that compare different ablations and baselines.