 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSet Block Decoding is a Language Model Inference Accelerator
Sep 04, 2025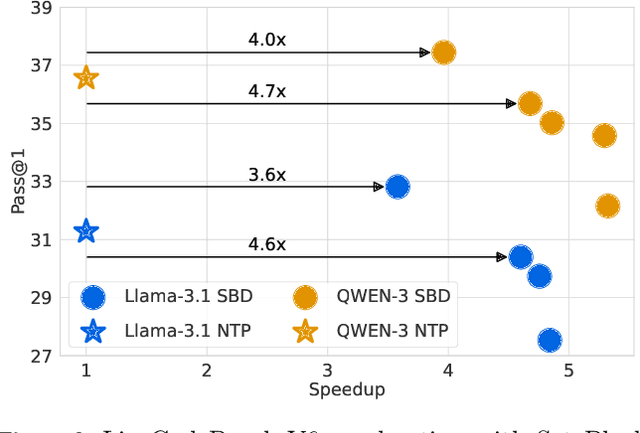
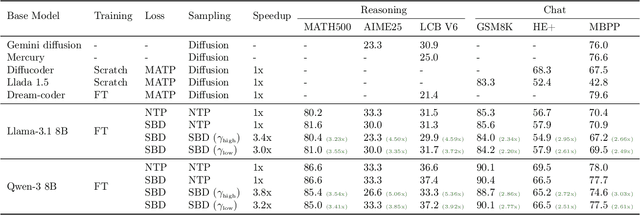
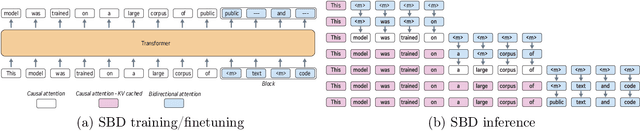

Autoregressive next token prediction language models offer powerful capabilities but face significant challenges in practical deployment due to the high computational and memory costs of inference, particularly during the decoding stage. We introduce Set Block Decoding (SBD), a simple and flexible paradigm that accelerates generation by integrating standard next token prediction (NTP) and masked token prediction (MATP) within a single architecture. SBD allows the model to sample multiple, not necessarily consecutive, future tokens in parallel, a key distinction from previous acceleration methods. This flexibility allows the use of advanced solvers from the discrete diffusion literature, offering significant speedups without sacrificing accuracy. SBD requires no architectural changes or extra training hyperparameters, maintains compatibility with exact KV-caching, and can be implemented by fine-tuning existing next token prediction models. By fine-tuning Llama-3.1 8B and Qwen-3 8B, we demonstrate that SBD enables a 3-5x reduction in the number of forward passes required for generation while achieving same performance as equivalent NTP training.
Edit Flows: Flow Matching with Edit Operations
Jun 10, 2025Autoregressive generative models naturally generate variable-length sequences, while non-autoregressive models struggle, often imposing rigid, token-wise structures. We propose Edit Flows, a non-autoregressive model that overcomes these limitations by defining a discrete flow over sequences through edit operations-insertions, deletions, and substitutions. By modeling these operations within a Continuous-time Markov Chain over the sequence space, Edit Flows enable flexible, position-relative generation that aligns more closely with the structure of sequence data. Our training method leverages an expanded state space with auxiliary variables, making the learning process efficient and tractable. Empirical results show that Edit Flows outperforms both autoregressive and mask models on image captioning and significantly outperforms the mask construction in text and code generation.
Corrector Sampling in Language Models
Jun 06, 2025



Autoregressive language models accumulate errors due to their fixed, irrevocable left-to-right token generation. To address this, we propose a new sampling method called Resample-Previous-Tokens (RPT). RPT mitigates error accumulation by iteratively revisiting and potentially replacing tokens in a window of previously generated text. This method can be integrated into existing autoregressive models, preserving their next-token-prediction quality and speed. Fine-tuning a pretrained 8B parameter model with RPT for only 100B resulted in ~10% relative improvements on reasoning and coding benchmarks compared to the standard sampling.
Accelerated Sampling from Masked Diffusion Models via Entropy Bounded Unmasking
May 30, 2025Recent masked diffusion models (MDMs) have shown competitive performance compared to autoregressive models (ARMs) for language modeling. While most literature has focused on performance enhancing sampling procedures, efficient sampling from MDMs has been scarcely explored. We make the observation that often a given sequence of partially masked tokens determines the values of multiple unknown tokens deterministically, meaning that a single prediction of a masked model holds additional information unused by standard sampling procedures. Based on this observation, we introduce EB-Sampler, a simple drop-in replacement for existing samplers, utilizing an Entropy Bounded unmasking procedure that dynamically unmasks multiple tokens in one function evaluation with predefined approximate error tolerance. We formulate the EB-Sampler as part of a broad family of adaptive samplers for which we provide an error analysis that motivates our algorithmic choices. EB-Sampler accelerates sampling from current state of the art MDMs by roughly 2-3x on standard coding and math reasoning benchmarks without loss in performance. We also validate the same procedure works well on smaller reasoning tasks including maze navigation and Sudoku, tasks ARMs often struggle with.
Flow Matching Guide and Code
Dec 09, 2024Flow Matching (FM) is a recent framework for generative modeling that has achieved state-of-the-art performance across various domains, including image, video, audio, speech, and biological structures. This guide offers a comprehensive and self-contained review of FM, covering its mathematical foundations, design choices, and extensions. By also providing a PyTorch package featuring relevant examples (e.g., image and text generation), this work aims to serve as a resource for both novice and experienced researchers interested in understanding, applying and further developing FM.
Flow Matching with General Discrete Paths: A Kinetic-Optimal Perspective
Dec 04, 2024The design space of discrete-space diffusion or flow generative models are significantly less well-understood than their continuous-space counterparts, with many works focusing only on a simple masked construction. In this work, we aim to take a holistic approach to the construction of discrete generative models based on continuous-time Markov chains, and for the first time, allow the use of arbitrary discrete probability paths, or colloquially, corruption processes. Through the lens of optimizing the symmetric kinetic energy, we propose velocity formulas that can be applied to any given probability path, completely decoupling the probability and velocity, and giving the user the freedom to specify any desirable probability path based on expert knowledge specific to the data domain. Furthermore, we find that a special construction of mixture probability paths optimizes the symmetric kinetic energy for the discrete case. We empirically validate the usefulness of this new design space across multiple modalities: text generation, inorganic material generation, and image generation. We find that we can outperform the mask construction even in text with kinetic-optimal mixture paths, while we can make use of domain-specific constructions of the probability path over the visual domain.
Generator Matching: Generative modeling with arbitrary Markov processes
Oct 27, 2024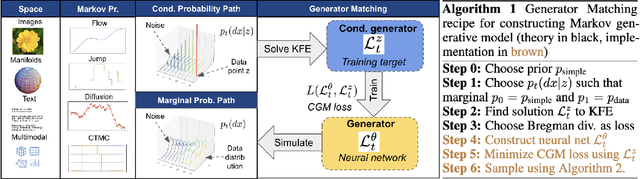

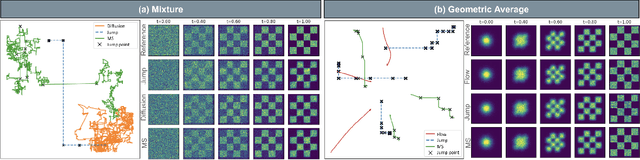
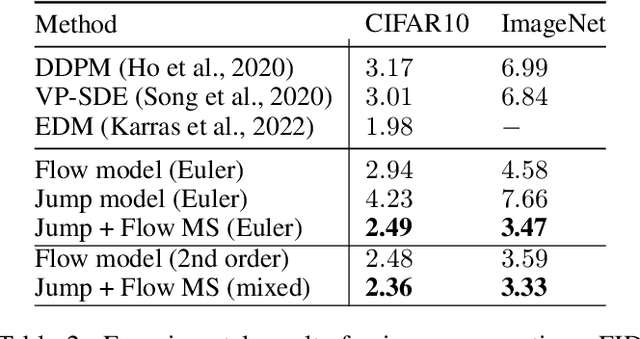
We introduce generator matching, a modality-agnostic framework for generative modeling using arbitrary Markov processes. Generators characterize the infinitesimal evolution of a Markov process, which we leverage for generative modeling in a similar vein to flow matching: we construct conditional generators which generate single data points, then learn to approximate the marginal generator which generates the full data distribution. We show that generator matching unifies various generative modeling methods, including diffusion models, flow matching and discrete diffusion models. Furthermore, it provides the foundation to expand the design space to new and unexplored Markov processes such as jump processes. Finally, generator matching enables the construction of superpositions of Markov generative processes and enables the construction of multimodal models in a rigorous manner. We empirically validate our method on protein and image structure generation, showing that superposition with a jump process improves image generation.
Exact Byte-Level Probabilities from Tokenized Language Models for FIM-Tasks and Model Ensembles
Oct 11, 2024



Tokenization is associated with many poorly understood shortcomings in language models (LMs), yet remains an important component for long sequence scaling purposes. This work studies how tokenization impacts model performance by analyzing and comparing the stochastic behavior of tokenized models with their byte-level, or token-free, counterparts. We discover that, even when the two models are statistically equivalent, their predictive distributions over the next byte can be substantially different, a phenomenon we term as "tokenization bias''. To fully characterize this phenomenon, we introduce the Byte-Token Representation Lemma, a framework that establishes a mapping between the learned token distribution and its equivalent byte-level distribution. From this result, we develop a next-byte sampling algorithm that eliminates tokenization bias without requiring further training or optimization. In other words, this enables zero-shot conversion of tokenized LMs into statistically equivalent token-free ones. We demonstrate its broad applicability with two use cases: fill-in-the-middle (FIM) tasks and model ensembles. In FIM tasks where input prompts may terminate mid-token, leading to out-of-distribution tokenization, our method mitigates performance degradation and achieves an approximately 18% improvement in FIM coding benchmarks, consistently outperforming the standard token healing fix. For model ensembles where each model employs a distinct vocabulary, our approach enables seamless integration, resulting in improved performance (up to 3.7%) over individual models across various standard baselines in reasoning, knowledge, and coding.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Discrete Flow Matching
Jul 22, 2024Despite Flow Matching and diffusion models having emerged as powerful generative paradigms for continuous variables such as images and videos, their application to high-dimensional discrete data, such as language, is still limited. In this work, we present Discrete Flow Matching, a novel discrete flow paradigm designed specifically for generating discrete data. Discrete Flow Matching offers several key contributions: (i) it works with a general family of probability paths interpolating between source and target distributions; (ii) it allows for a generic formula for sampling from these probability paths using learned posteriors such as the probability denoiser ($x$-prediction) and noise-prediction ($\epsilon$-prediction); (iii) practically, focusing on specific probability paths defined with different schedulers considerably improves generative perplexity compared to previous discrete diffusion and flow models; and (iv) by scaling Discrete Flow Matching models up to 1.7B parameters, we reach 6.7% Pass@1 and 13.4% Pass@10 on HumanEval and 6.7% Pass@1 and 20.6% Pass@10 on 1-shot MBPP coding benchmarks. Our approach is capable of generating high-quality discrete data in a non-autoregressive fashion, significantly closing the gap between autoregressive models and discrete flow models.