 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Compute as Teacher: Turning Inference Compute Into Reference-Free Supervision
Sep 17, 2025Where do learning signals come from when there is no ground truth in post-training? We propose turning exploration into supervision through Compute as Teacher (CaT), which converts the model's own exploration at inference-time into reference-free supervision by synthesizing a single reference from a group of parallel rollouts and then optimizing toward it. Concretely, the current policy produces a group of rollouts; a frozen anchor (the initial policy) reconciles omissions and contradictions to estimate a reference, turning extra inference-time compute into a teacher signal. We turn this into rewards in two regimes: (i) verifiable tasks use programmatic equivalence on final answers; (ii) non-verifiable tasks use self-proposed rubrics-binary, auditable criteria scored by an independent LLM judge, with reward given by the fraction satisfied. Unlike selection methods (best-of-N, majority, perplexity, or judge scores), synthesis may disagree with the majority and be correct even when all rollouts are wrong; performance scales with the number of rollouts. As a test-time procedure, CaT improves Gemma 3 4B, Qwen 3 4B, and Llama 3.1 8B (up to +27% on MATH-500; +12% on HealthBench). With reinforcement learning (CaT-RL), we obtain further gains (up to +33% and +30%), with the trained policy surpassing the initial teacher signal.
HalluLens: LLM Hallucination Benchmark
Apr 24, 2025



Large language models (LLMs) often generate responses that deviate from user input or training data, a phenomenon known as "hallucination." These hallucinations undermine user trust and hinder the adoption of generative AI systems. Addressing hallucinations is essential for the advancement of LLMs. This paper introduces a comprehensive hallucination benchmark, incorporating both new extrinsic and existing intrinsic evaluation tasks, built upon clear taxonomy of hallucination. A major challenge in benchmarking hallucinations is the lack of a unified framework due to inconsistent definitions and categorizations. We disentangle LLM hallucination from "factuality," proposing a clear taxonomy that distinguishes between extrinsic and intrinsic hallucinations, to promote consistency and facilitate research. Extrinsic hallucinations, where the generated content is not consistent with the training data, are increasingly important as LLMs evolve. Our benchmark includes dynamic test set generation to mitigate data leakage and ensure robustness against such leakage. We also analyze existing benchmarks, highlighting their limitations and saturation. The work aims to: (1) establish a clear taxonomy of hallucinations, (2) introduce new extrinsic hallucination tasks, with data that can be dynamically regenerated to prevent saturation by leakage, (3) provide a comprehensive analysis of existing benchmarks, distinguishing them from factuality evaluations.
Calibrating Verbal Uncertainty as a Linear Feature to Reduce Hallucinations
Mar 18, 2025



LLMs often adopt an assertive language style also when making false claims. Such ``overconfident hallucinations'' mislead users and erode trust. Achieving the ability to express in language the actual degree of uncertainty around a claim is therefore of great importance. We find that ``verbal uncertainty'' is governed by a single linear feature in the representation space of LLMs, and show that this has only moderate correlation with the actual ``semantic uncertainty'' of the model. We apply this insight and show that (1) the mismatch between semantic and verbal uncertainty is a better predictor of hallucinations than semantic uncertainty alone and (2) we can intervene on verbal uncertainty at inference time and reduce hallucinations on short-form answers, achieving an average relative reduction of 32%.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Llama 2: Open Foundation and Fine-Tuned Chat Models
Jul 19, 2023



In this work, we develop and release Llama 2, a collection of pretrained and fine-tuned large language models (LLMs) ranging in scale from 7 billion to 70 billion parameters. Our fine-tuned LLMs, called Llama 2-Chat, are optimized for dialogue use cases. Our models outperform open-source chat models on most benchmarks we tested, and based on our human evaluations for helpfulness and safety, may be a suitable substitute for closed-source models. We provide a detailed description of our approach to fine-tuning and safety improvements of Llama 2-Chat in order to enable the community to build on our work and contribute to the responsible development of LLMs.
Using Titles vs. Full-text as Source for Automated Semantic Document Annotation
Sep 27, 2017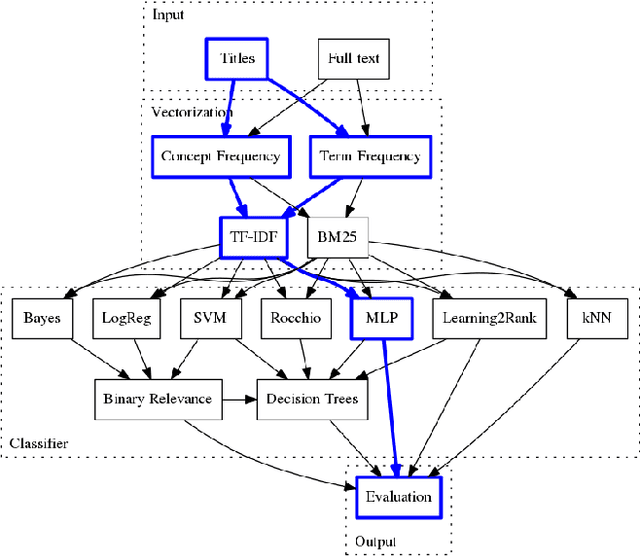
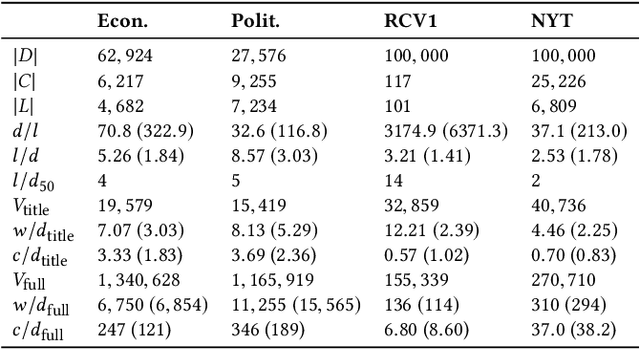


A significant part of the largest Knowledge Graph today, the Linked Open Data cloud, consists of metadata about documents such as publications, news reports, and other media articles. While the widespread access to the document metadata is a tremendous advancement, it is yet not so easy to assign semantic annotations and organize the documents along semantic concepts. Providing semantic annotations like concepts in SKOS thesauri is a classical research topic, but typically it is conducted on the full-text of the documents. For the first time, we offer a systematic comparison of classification approaches to investigate how far semantic annotations can be conducted using just the metadata of the documents such as titles published as labels on the Linked Open Data cloud. We compare the classifications obtained from analyzing the documents' titles with semantic annotations obtained from analyzing the full-text. Apart from the prominent text classification baselines kNN and SVM, we also compare recent techniques of Learning to Rank and neural networks and revisit the traditional methods logistic regression, Rocchio, and Naive Bayes. The results show that across three of our four datasets, the performance of the classifications using only titles reaches over 90% of the quality compared to the classification performance when using the full-text. Thus, conducting document classification by just using the titles is a reasonable approach for automated semantic annotation and opens up new possibilities for enriching Knowledge Graphs.