 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot Everything That Counts Can Be Counted: A Case for Safe Qualitative AI
Nov 12, 2025Artificial intelligence (AI) and large language models (LLM) are reshaping science, with most recent advances culminating in fully-automated scientific discovery pipelines. But qualitative research has been left behind. Researchers in qualitative methods are hesitant about AI adoption. Yet when they are willing to use AI at all, they have little choice but to rely on general-purpose tools like ChatGPT to assist with interview interpretation, data annotation, and topic modeling - while simultaneously acknowledging these system's well-known limitations of being biased, opaque, irreproducible, and privacy-compromising. This creates a critical gap: while AI has substantially advanced quantitative methods, the qualitative dimensions essential for meaning-making and comprehensive scientific understanding remain poorly integrated. We argue for developing dedicated qualitative AI systems built from the ground up for interpretive research. Such systems must be transparent, reproducible, and privacy-friendly. We review recent literature to show how existing automated discovery pipelines could be enhanced by robust qualitative capabilities, and identify key opportunities where safe qualitative AI could advance multidisciplinary and mixed-methods research.
Gumbel-MPNN: Graph Rewiring with Gumbel-Softmax
Aug 24, 2025Graph homophily has been considered an essential property for message-passing neural networks (MPNN) in node classification. Recent findings suggest that performance is more closely tied to the consistency of neighborhood class distributions. We demonstrate that the MPNN performance depends on the number of components of the overall neighborhood distribution within a class. By breaking down the classes into their neighborhood distribution components, we increase measures of neighborhood distribution informativeness but do not observe an improvement in MPNN performance. We propose a Gumbel-Softmax-based rewiring method that reduces deviations in neighborhood distributions. Our results show that our new method enhances neighborhood informativeness, handles long-range dependencies, mitigates oversquashing, and increases the classification performance of the MPNN. The code is available at https://github.com/Bobowner/Gumbel-Softmax-MPNN.
Guarded Query Routing for Large Language Models
May 20, 2025Query routing, the task to route user queries to different large language model (LLM) endpoints, can be considered as a text classification problem. However, out-of-distribution queries must be handled properly, as those could be questions about unrelated domains, queries in other languages, or even contain unsafe text. Here, we thus study a \emph{guarded} query routing problem, for which we first introduce the Guarded Query Routing Benchmark (GQR-Bench), which covers three exemplary target domains (law, finance, and healthcare), and seven datasets to test robustness against out-of-distribution queries. We then use GQR-Bench to contrast the effectiveness and efficiency of LLM-based routing mechanisms (GPT-4o-mini, Llama-3.2-3B, and Llama-3.1-8B), standard LLM-based guardrail approaches (LlamaGuard and NVIDIA NeMo Guardrails), continuous bag-of-words classifiers (WideMLP, fastText), and traditional machine learning models (SVM, XGBoost). Our results show that WideMLP, enhanced with out-of-domain detection capabilities, yields the best trade-off between accuracy (88\%) and speed (<4ms). The embedding-based fastText excels at speed (<1ms) with acceptable accuracy (80\%), whereas LLMs yield the highest accuracy (91\%) but are comparatively slow (62ms for local Llama-3.1:8B and 669ms for remote GPT-4o-mini calls). Our findings challenge the automatic reliance on LLMs for (guarded) query routing and provide concrete recommendations for practical applications. GQR-Bench will be released as a Python package -- \texttt{gqr}.
Continual Quantization-Aware Pre-Training: When to transition from 16-bit to 1.58-bit pre-training for BitNet language models?
Feb 17, 2025
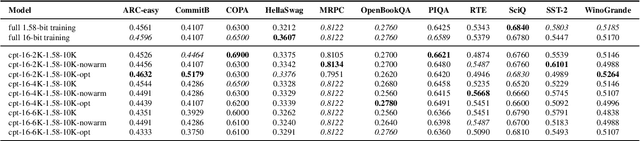
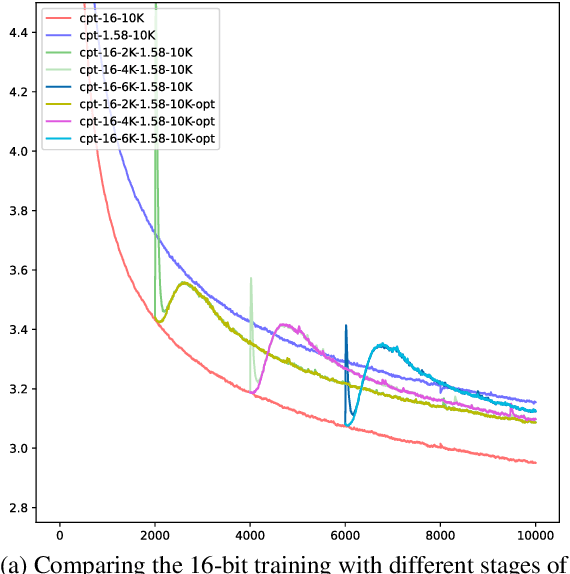
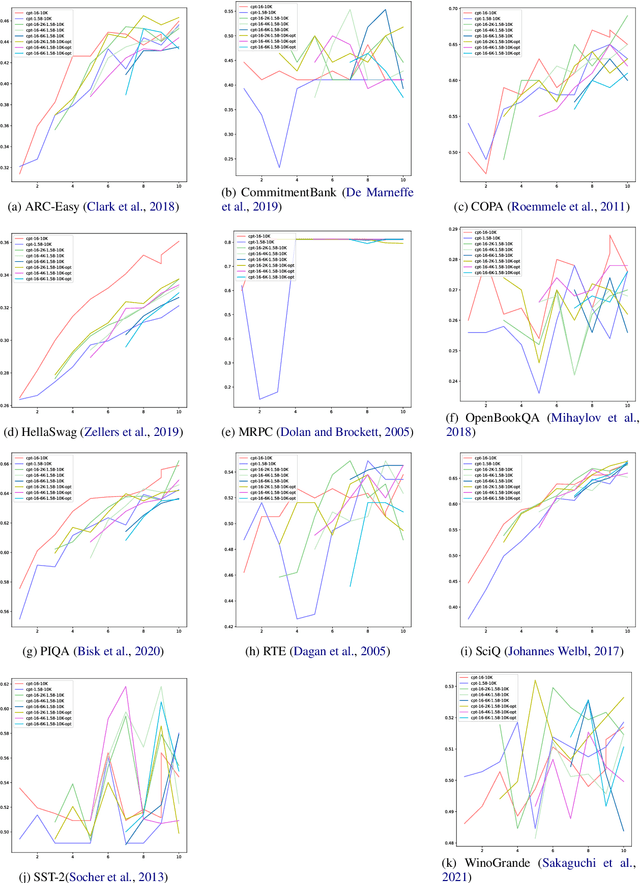
Large language models (LLMs) require immense resources for training and inference. Quantization, a technique that reduces the precision of model parameters, offers a promising solution for improving LLM efficiency and sustainability. While post-training quantization methods typically achieve 4-8 bits per parameter, recent research suggests that training LLMs with 1.58 bits per weight parameter from scratch can maintain model accuracy while greatly reducing memory requirements and energy consumption at inference time. Here, we investigate a training strategy for quantization-aware pre-training, where the models are first trained with 16-bit precision and then transition into 1.58-bit quantization-aware training. Our results on 11 downstream tasks show that this 16-to-1.58-bit training strategy is preferable over full 1.58-bit training and leaves models closer to those which have undergone 16-bit training. We further investigate the effects of retaining the optimizer state at the transition point and gradually phasing in quantization strength -- finding that both techniques alleviate the magnitude of loss spikes, but also that these effects can be compensated through further training.
FlexDeMo: Decoupled Momentum Optimization for Fully and Hybrid Sharded Training
Feb 10, 2025Training large neural network models requires extensive computational resources, often distributed across several nodes and accelerators. Recent findings suggest that it may be sufficient to only exchange the fast moving components of the gradients, while accumulating momentum locally (Decoupled Momentum, or DeMo). However, when considering larger models that do not fit on a single accelerate, the exchange of gradient information and the integration of DeMo needs to be reconsidered. Here, we propose employing a hybrid strategy, FlexDeMo, whereby nodes fully synchronize locally between different GPUs and inter-node communication is improved through only using the fast-moving components. This effectively combines previous hybrid sharding strategies with the advantages of decoupled momentum. Our experimental results show that FlexDeMo is on par with AdamW in terms of validation loss, demonstrating its viability.
A Transformer-based Autoregressive Decoder Architecture for Hierarchical Text Classification
Jan 23, 2025



Recent approaches in hierarchical text classification (HTC) rely on the capabilities of a pre-trained transformer model and exploit the label semantics and a graph encoder for the label hierarchy. In this paper, we introduce an effective hierarchical text classifier RADAr (Transformer-based Autoregressive Decoder Architecture) that is based only on an off-the-shelf RoBERTa transformer to process the input and a custom autoregressive decoder with two decoder layers for generating the classification output. Thus, unlike existing approaches for HTC, the encoder of RADAr has no explicit encoding of the label hierarchy and the decoder solely relies on the label sequences of the samples observed during training. We demonstrate on three benchmark datasets that RADAr achieves results competitive to the state of the art with less training and inference time. Our model consistently performs better when organizing the label sequences from children to parents versus the inverse, as done in existing HTC approaches. Our experiments show that neither the label semantics nor an explicit graph encoder for the hierarchy is needed. This has strong practical implications for HTC as the architecture has fewer requirements and provides a speed-up by a factor of 2 at inference time. Moreover, training a separate decoder from scratch in conjunction with fine-tuning the encoder allows future researchers and practitioners to exchange the encoder part as new models arise. The source code is available at https://github.com/yousef-younes/RADAr.
* 7 pages + 1 for references. 2 Figure. ECAI conference
Continual Learning for Encoder-only Language Models via a Discrete Key-Value Bottleneck
Dec 11, 2024Continual learning remains challenging across various natural language understanding tasks. When models are updated with new training data, they risk catastrophic forgetting of prior knowledge. In the present work, we introduce a discrete key-value bottleneck for encoder-only language models, allowing for efficient continual learning by requiring only localized updates. Inspired by the success of a discrete key-value bottleneck in vision, we address new and NLP-specific challenges. We experiment with different bottleneck architectures to find the most suitable variants regarding language, and present a generic discrete key initialization technique for NLP that is task independent. We evaluate the discrete key-value bottleneck in four continual learning NLP scenarios and demonstrate that it alleviates catastrophic forgetting. We showcase that it offers competitive performance to other popular continual learning methods, with lower computational costs.
Isotropy Matters: Soft-ZCA Whitening of Embeddings for Semantic Code Search
Nov 26, 2024Low isotropy in an embedding space impairs performance on tasks involving semantic inference. Our study investigates the impact of isotropy on semantic code search performance and explores post-processing techniques to mitigate this issue. We analyze various code language models, examine isotropy in their embedding spaces, and its influence on search effectiveness. We propose a modified ZCA whitening technique to control isotropy levels in embeddings. Our results demonstrate that Soft-ZCA whitening improves the performance of pre-trained code language models and can complement contrastive fine-tuning. The code for our experiments is available at https://github.com/drndr/code\_isotropy
Hierarchical Text Classification (HTC) vs. eXtreme Multilabel Classification (XML): Two Sides of the Same Medal
Nov 20, 2024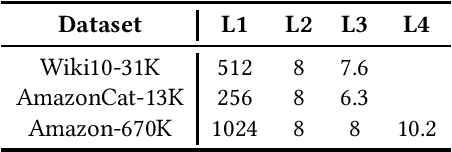
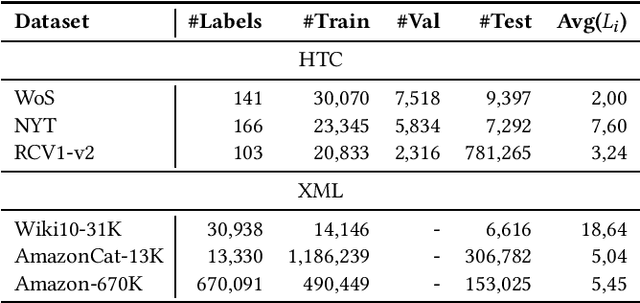
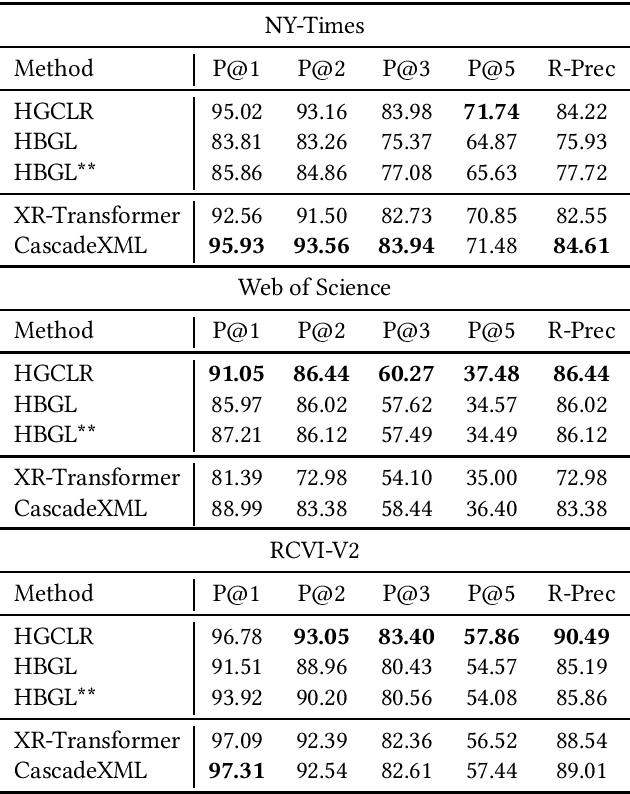
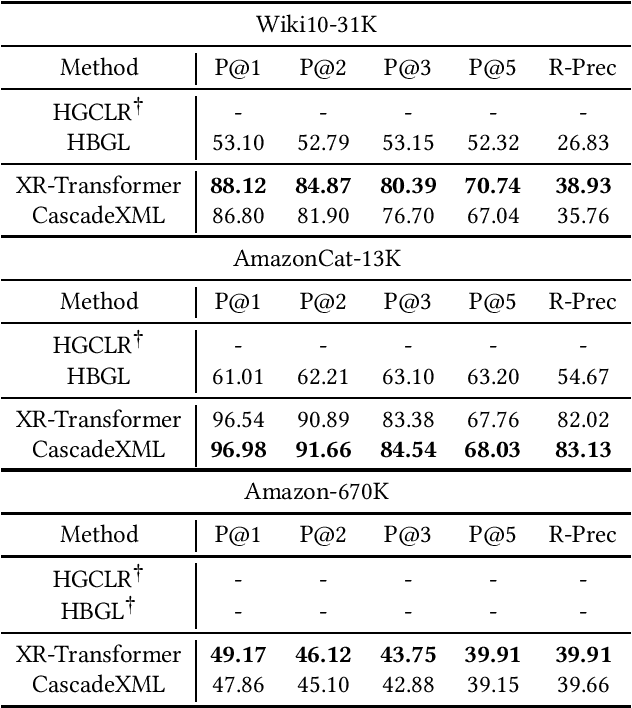
Assigning a subset of labels from a fixed pool of labels to a given input text is a text classification problem with many real-world applications, such as in recommender systems. Two separate research streams address this issue. Hierarchical Text Classification (HTC) focuses on datasets with smaller label pools of hundreds of entries, accompanied by a semantic label hierarchy. In contrast, eXtreme Multi-Label Text Classification (XML) considers very large label pools with up to millions of entries, in which the labels are not arranged in any particular manner. However, in XML, a common approach is to construct an artificial hierarchy without any semantic information before or during the training process. Here, we investigate how state-of-the-art models from one domain perform when trained and tested on datasets from the other domain. The HBGL and HGLCR models from the HTC domain are trained and tested on the datasets Wiki10-31K, AmazonCat-13K, and Amazon-670K from the XML domain. On the other side, the XML models CascadeXML and XR-Transformer are trained and tested on the datasets Web of Science, The New York Times Annotated Corpus, and RCV1-V2 from the HTC domain. HTC models, on the other hand, are not equipped to handle the size of XML datasets and achieve poor transfer results. The code and numerous files that are needed to reproduce our results can be obtained from https://github.com/FloHauss/XMC_HTC
When are 1.58 bits enough? A Bottom-up Exploration of BitNet Quantization
Nov 08, 2024
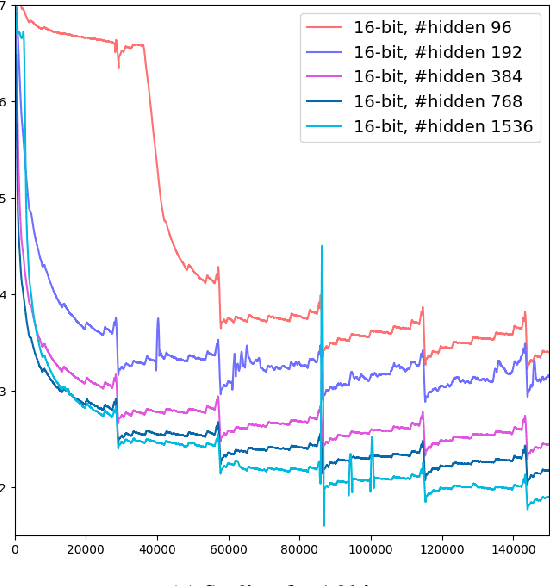
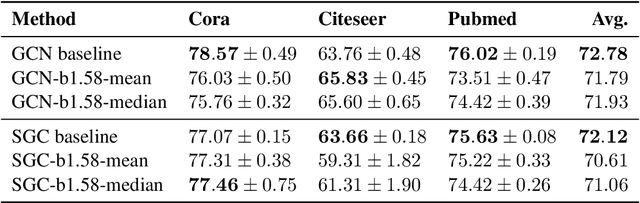
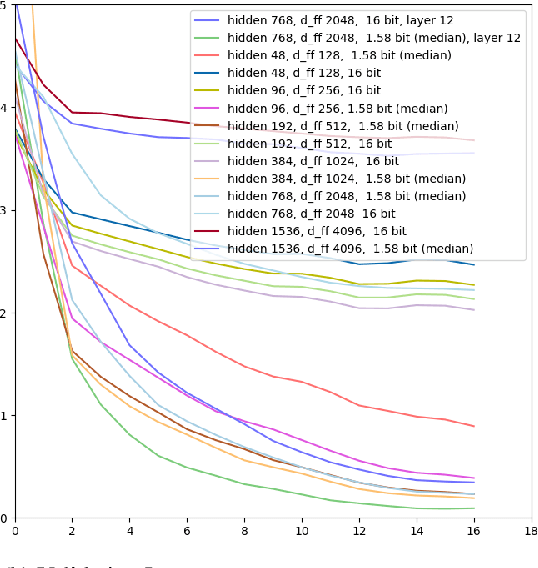
Contemporary machine learning models, such as language models, are powerful, but come with immense resource requirements both at training and inference time. It has been shown that decoder-only language models can be trained to a competitive state with ternary weights (1.58 bits per weight), facilitating efficient inference. Here, we start our exploration with non-transformer model architectures, investigating 1.58-bit training for multi-layer perceptrons and graph neural networks. Then, we explore 1.58-bit training in other transformer-based language models, namely encoder-only and encoder-decoder models. Our results show that in all of these settings, 1.58-bit training is on par with or sometimes even better than the standard 32/16-bit models.