 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Language Models Encode Semantic Relations? Probing and Sparse Feature Analysis
Mar 18, 2026Understanding whether large language models (LLMs) capture structured meaning requires examining how they represent concept relationships. In this work, we study three models of increasing scale: Pythia-70M, GPT-2, and Llama 3.1 8B, focusing on four semantic relations: synonymy, antonymy, hypernymy, and hyponymy. We combine linear probing with mechanistic interpretability techniques, including sparse autoencoders (SAE) and activation patching, to identify where these relations are encoded and how specific features contribute to their representation. Our results reveal a directional asymmetry in hierarchical relations: hypernymy is encoded redundantly and resists suppression, while hyponymy relies on compact features that are more easily disrupted by ablation. More broadly, relation signals are diffuse but exhibit stable profiles: they peak in the mid-layers and are stronger in post-residual/MLP pathways than in attention. Difficulty is consistent across models (antonymy easiest, synonymy hardest). Probe-level causality is capacity-dependent: on Llama 3.1, SAE-guided patching reliably shifts these signals, whereas on smaller models the shifts are weak or unstable. Our results clarify where and how reliably semantic relations are represented inside LLMs, and provide a reproducible framework for relating sparse features to probe-level causal evidence.
Continual Learning for Encoder-only Language Models via a Discrete Key-Value Bottleneck
Dec 11, 2024Continual learning remains challenging across various natural language understanding tasks. When models are updated with new training data, they risk catastrophic forgetting of prior knowledge. In the present work, we introduce a discrete key-value bottleneck for encoder-only language models, allowing for efficient continual learning by requiring only localized updates. Inspired by the success of a discrete key-value bottleneck in vision, we address new and NLP-specific challenges. We experiment with different bottleneck architectures to find the most suitable variants regarding language, and present a generic discrete key initialization technique for NLP that is task independent. We evaluate the discrete key-value bottleneck in four continual learning NLP scenarios and demonstrate that it alleviates catastrophic forgetting. We showcase that it offers competitive performance to other popular continual learning methods, with lower computational costs.
Isotropy Matters: Soft-ZCA Whitening of Embeddings for Semantic Code Search
Nov 26, 2024Low isotropy in an embedding space impairs performance on tasks involving semantic inference. Our study investigates the impact of isotropy on semantic code search performance and explores post-processing techniques to mitigate this issue. We analyze various code language models, examine isotropy in their embedding spaces, and its influence on search effectiveness. We propose a modified ZCA whitening technique to control isotropy levels in embeddings. Our results demonstrate that Soft-ZCA whitening improves the performance of pre-trained code language models and can complement contrastive fine-tuning. The code for our experiments is available at https://github.com/drndr/code\_isotropy
GenCodeSearchNet: A Benchmark Test Suite for Evaluating Generalization in Programming Language Understanding
Nov 16, 2023
Language models can serve as a valuable tool for software developers to increase productivity. Large generative models can be used for code generation and code completion, while smaller encoder-only models are capable of performing code search tasks using natural language queries.These capabilities are heavily influenced by the quality and diversity of the available training data. Source code datasets used for training usually focus on the most popular languages and testing is mostly conducted on the same distributions, often overlooking low-resource programming languages. Motivated by the NLP generalization taxonomy proposed by Hupkes et.\,al., we propose a new benchmark dataset called GenCodeSearchNet (GeCS) which builds upon existing natural language code search datasets to systemically evaluate the programming language understanding generalization capabilities of language models. As part of the full dataset, we introduce a new, manually curated subset StatCodeSearch that focuses on R, a popular but so far underrepresented programming language that is often used by researchers outside the field of computer science. For evaluation and comparison, we collect several baseline results using fine-tuned BERT-style models and GPT-style large language models in a zero-shot setting.
A Study on Extracting Named Entities from Fine-tuned vs. Differentially Private Fine-tuned BERT Models
Dec 07, 2022Privacy preserving deep learning is an emerging field in machine learning that aims to mitigate the privacy risks in the use of deep neural networks. One such risk is training data extraction from language models that have been trained on datasets , which contain personal and privacy sensitive information. In our study, we investigate the extent of named entity memorization in fine-tuned BERT models. We use single-label text classification as representative downstream task and employ three different fine-tuning setups in our experiments, including one with Differentially Privacy (DP). We create a large number of text samples from the fine-tuned BERT models utilizing a custom sequential sampling strategy with two prompting strategies. We search in these samples for named entities and check if they are also present in the fine-tuning datasets. We experiment with two benchmark datasets in the domains of emails and blogs. We show that the application of DP has a huge effect on the text generation capabilities of BERT. Furthermore, we show that a fine-tuned BERT does not generate more named entities entities specific to the fine-tuning dataset than a BERT model that is pre-trained only. This suggests that BERT is unlikely to emit personal or privacy sensitive named entities. Overall, our results are important to understand to what extent BERT-based services are prone to training data extraction attacks.
Bag-of-Words vs. Sequence vs. Graph vs. Hierarchy for Single- and Multi-Label Text Classification
Apr 08, 2022
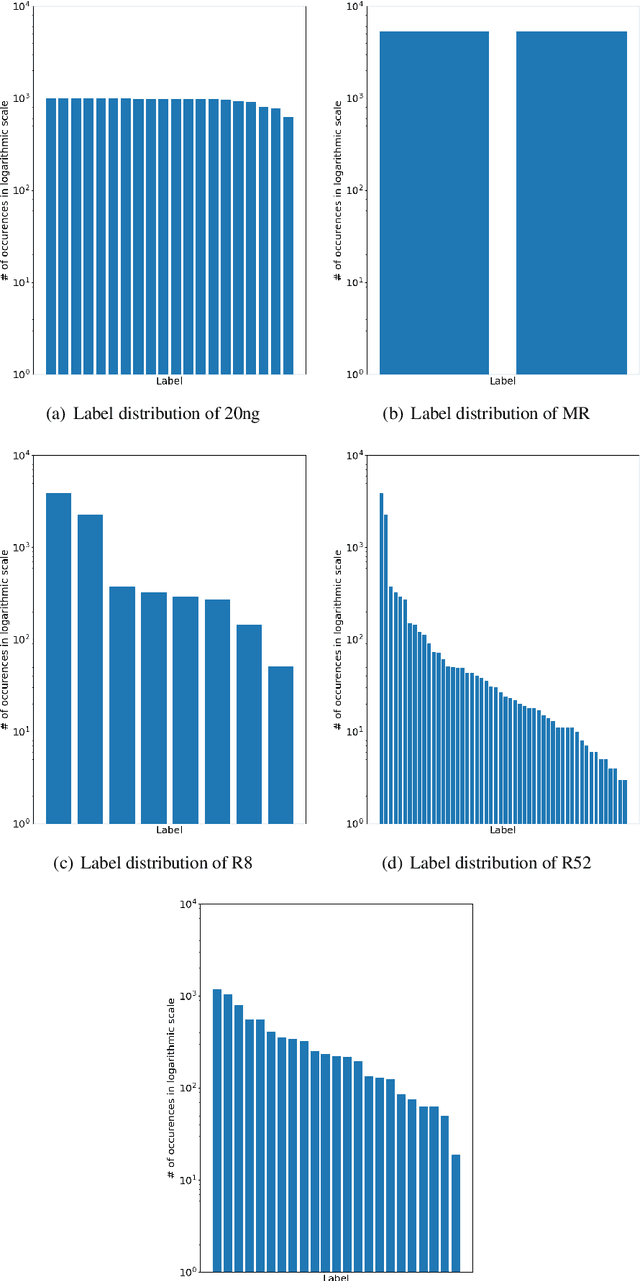
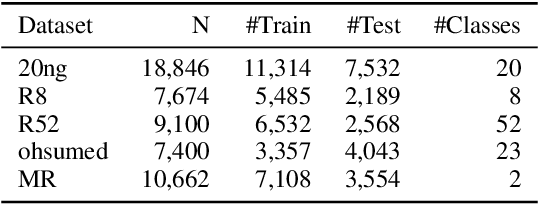
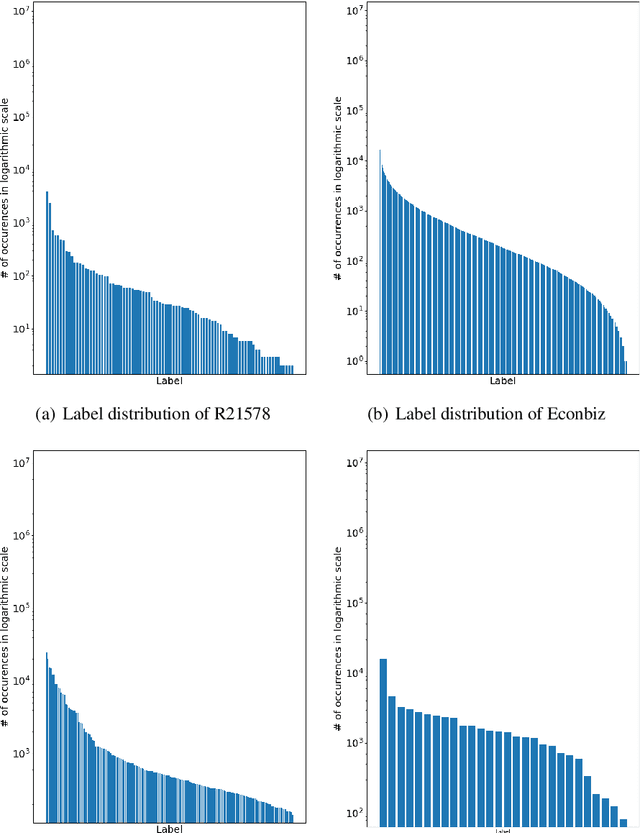
Graph neural networks have triggered a resurgence of graph-based text classification methods, defining today's state of the art. We show that a simple multi-layer perceptron (MLP) using a Bag of Words (BoW) outperforms the recent graph-based models TextGCN and HeteGCN in an inductive text classification setting and is comparable with HyperGAT in single-label classification. We also run our own experiments on multi-label classification, where the simple MLP outperforms the recent sequential-based gMLP and aMLP models. Moreover, we fine-tune a sequence-based BERT and a lightweight DistilBERT model, which both outperform all models on both single-label and multi-label settings in most datasets. These results question the importance of synthetic graphs used in modern text classifiers. In terms of parameters, DistilBERT is still twice as large as our BoW-based wide MLP, while graph-based models like TextGCN require setting up an $\mathcal{O}(N^2)$ graph, where $N$ is the vocabulary plus corpus size.