 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeodragon: Mobile Video Generation using Diffusion Transformer
Nov 08, 2025We introduce Neodragon, a text-to-video system capable of generating 2s (49 frames @24 fps) videos at the 640x1024 resolution directly on a Qualcomm Hexagon NPU in a record 6.7s (7 FPS). Differing from existing transformer-based offline text-to-video generation models, Neodragon is the first to have been specifically optimised for mobile hardware to achieve efficient and high-fidelity video synthesis. We achieve this through four key technical contributions: (1) Replacing the original large 4.762B T5xxl Text-Encoder with a much smaller 0.2B DT5 (DistilT5) with minimal quality loss, enabled through a novel Text-Encoder Distillation procedure. (2) Proposing an Asymmetric Decoder Distillation approach allowing us to replace the native codec-latent-VAE decoder with a more efficient one, without disturbing the generative latent-space of the generation pipeline. (3) Pruning of MMDiT blocks within the denoiser backbone based on their relative importance, with recovery of original performance through a two-stage distillation process. (4) Reducing the NFE (Neural Functional Evaluation) requirement of the denoiser by performing step distillation using DMD adapted for pyramidal flow-matching, thereby substantially accelerating video generation. When paired with an optimised SSD1B first-frame image generator and QuickSRNet for 2x super-resolution, our end-to-end Neodragon system becomes a highly parameter (4.945B full model), memory (3.5GB peak RAM usage), and runtime (6.7s E2E latency) efficient mobile-friendly model, while achieving a VBench total score of 81.61. By enabling low-cost, private, and on-device text-to-video synthesis, Neodragon democratizes AI-based video content creation, empowering creators to generate high-quality videos without reliance on cloud services. Code and model will be made publicly available at our website: https://qualcomm-ai-research.github.io/neodragon
MobileNVC: Real-time 1080p Neural Video Compression on a Mobile Device
Oct 02, 2023



Neural video codecs have recently become competitive with standard codecs such as HEVC in the low-delay setting. However, most neural codecs are large floating-point networks that use pixel-dense warping operations for temporal modeling, making them too computationally expensive for deployment on mobile devices. Recent work has demonstrated that running a neural decoder in real time on mobile is feasible, but shows this only for 720p RGB video, while the YUV420 format is more commonly used in production. This work presents the first neural video codec that decodes 1080p YUV420 video in real time on a mobile device. Our codec relies on two major contributions. First, we design an efficient codec that uses a block-based motion compensation algorithm available on the warping core of the mobile accelerator, and we show how to quantize this model to integer precision. Second, we implement a fast decoder pipeline that concurrently runs neural network components on the neural signal processor, parallel entropy coding on the mobile GPU, and warping on the warping core. Our codec outperforms the previous on-device codec by a large margin with up to 48 % BD-rate savings, while reducing the MAC count on the receiver side by 10x. We perform a careful ablation to demonstrate the effect of the introduced motion compensation scheme, and ablate the effect of model quantization.
Bag-of-Words vs. Sequence vs. Graph vs. Hierarchy for Single- and Multi-Label Text Classification
Apr 08, 2022
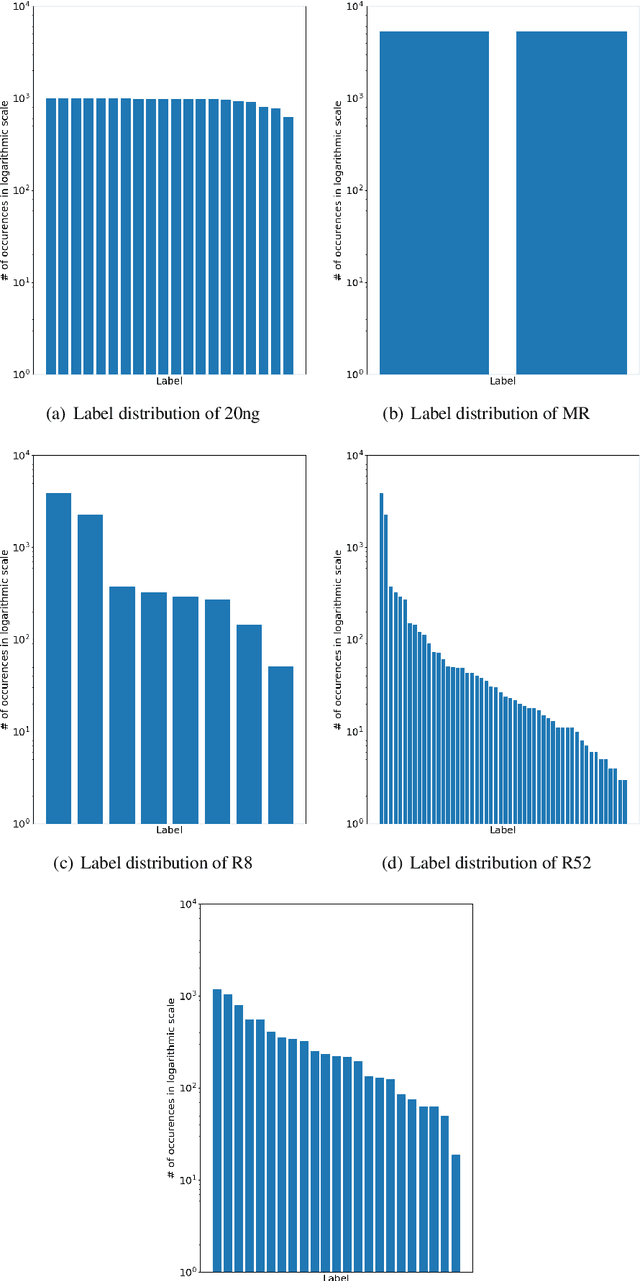
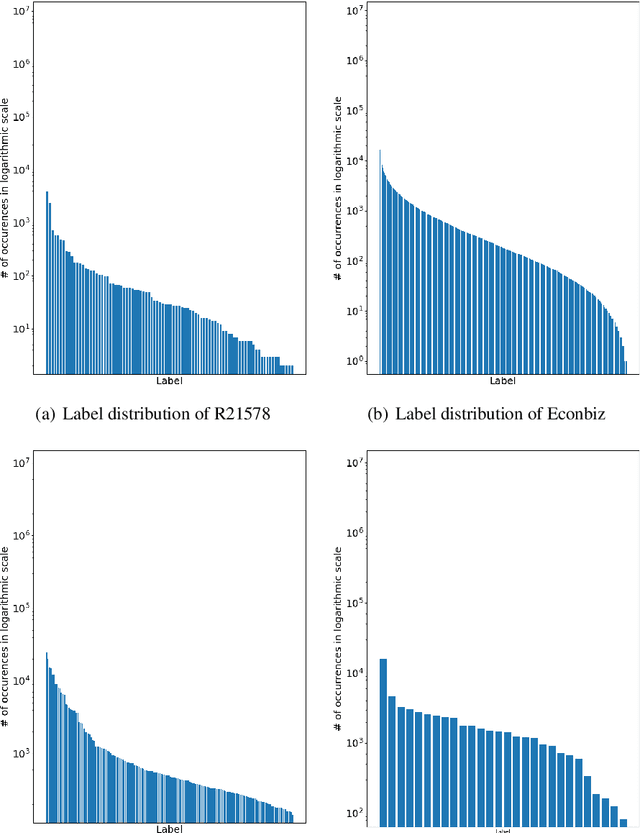
Graph neural networks have triggered a resurgence of graph-based text classification methods, defining today's state of the art. We show that a simple multi-layer perceptron (MLP) using a Bag of Words (BoW) outperforms the recent graph-based models TextGCN and HeteGCN in an inductive text classification setting and is comparable with HyperGAT in single-label classification. We also run our own experiments on multi-label classification, where the simple MLP outperforms the recent sequential-based gMLP and aMLP models. Moreover, we fine-tune a sequence-based BERT and a lightweight DistilBERT model, which both outperform all models on both single-label and multi-label settings in most datasets. These results question the importance of synthetic graphs used in modern text classifiers. In terms of parameters, DistilBERT is still twice as large as our BoW-based wide MLP, while graph-based models like TextGCN require setting up an $\mathcal{O}(N^2)$ graph, where $N$ is the vocabulary plus corpus size.