 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixture of Cache-Conditional Experts for Efficient Mobile Device Inference
Nov 27, 2024



Mixture of Experts (MoE) LLMs have recently gained attention for their ability to enhance performance by selectively engaging specialized subnetworks or "experts" for each input. However, deploying MoEs on memory-constrained devices remains challenging, particularly when generating tokens sequentially with a batch size of one, as opposed to typical high-throughput settings involving long sequences or large batches. In this work, we optimize MoE on memory-constrained devices where only a subset of expert weights fit in DRAM. We introduce a novel cache-aware routing strategy that leverages expert reuse during token generation to improve cache locality. We evaluate our approach on language modeling, MMLU, and GSM8K benchmarks and present on-device results demonstrating 2$\times$ speedups on mobile devices, offering a flexible, training-free solution to extend MoE's applicability across real-world applications.
MobileNVC: Real-time 1080p Neural Video Compression on a Mobile Device
Oct 02, 2023



Neural video codecs have recently become competitive with standard codecs such as HEVC in the low-delay setting. However, most neural codecs are large floating-point networks that use pixel-dense warping operations for temporal modeling, making them too computationally expensive for deployment on mobile devices. Recent work has demonstrated that running a neural decoder in real time on mobile is feasible, but shows this only for 720p RGB video, while the YUV420 format is more commonly used in production. This work presents the first neural video codec that decodes 1080p YUV420 video in real time on a mobile device. Our codec relies on two major contributions. First, we design an efficient codec that uses a block-based motion compensation algorithm available on the warping core of the mobile accelerator, and we show how to quantize this model to integer precision. Second, we implement a fast decoder pipeline that concurrently runs neural network components on the neural signal processor, parallel entropy coding on the mobile GPU, and warping on the warping core. Our codec outperforms the previous on-device codec by a large margin with up to 48 % BD-rate savings, while reducing the MAC count on the receiver side by 10x. We perform a careful ablation to demonstrate the effect of the introduced motion compensation scheme, and ablate the effect of model quantization.
Implicit Neural Video Compression
Dec 21, 2021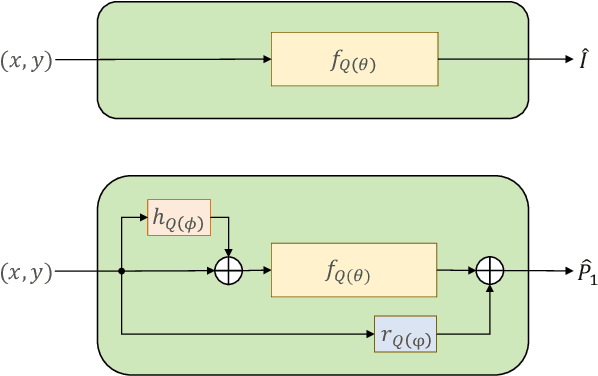
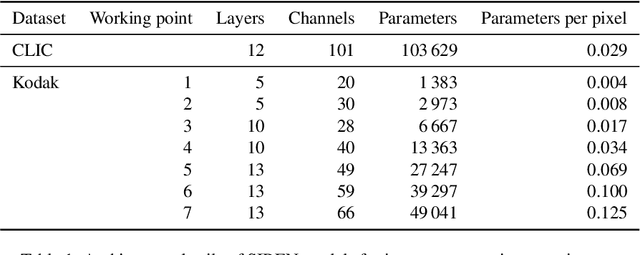

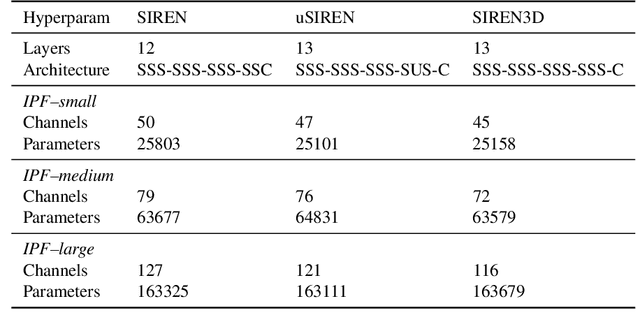
We propose a method to compress full-resolution video sequences with implicit neural representations. Each frame is represented as a neural network that maps coordinate positions to pixel values. We use a separate implicit network to modulate the coordinate inputs, which enables efficient motion compensation between frames. Together with a small residual network, this allows us to efficiently compress P-frames relative to the previous frame. We further lower the bitrate by storing the network weights with learned integer quantization. Our method, which we call implicit pixel flow (IPF), offers several simplifications over established neural video codecs: it does not require the receiver to have access to a pretrained neural network, does not use expensive interpolation-based warping operations, and does not require a separate training dataset. We demonstrate the feasibility of neural implicit compression on image and video data.
Instance-Adaptive Video Compression: Improving Neural Codecs by Training on the Test Set
Nov 19, 2021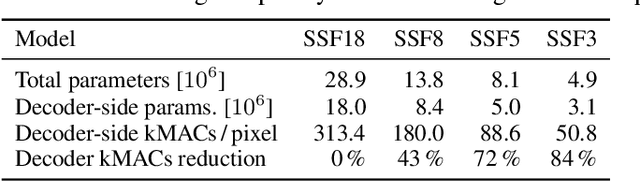
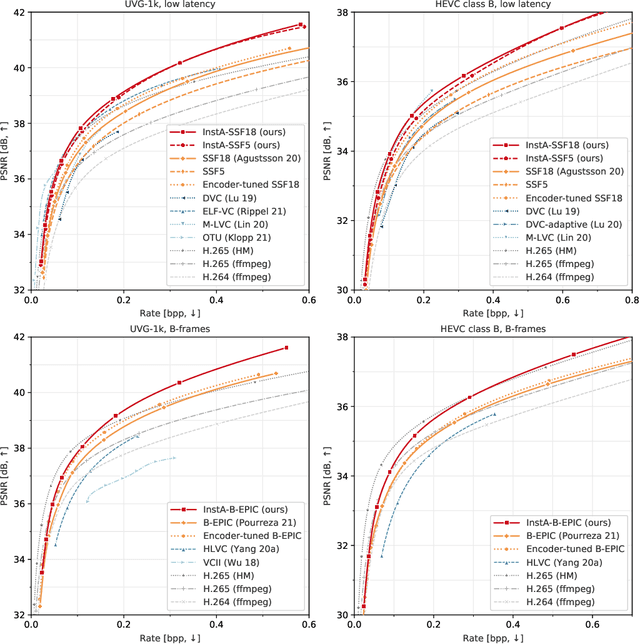
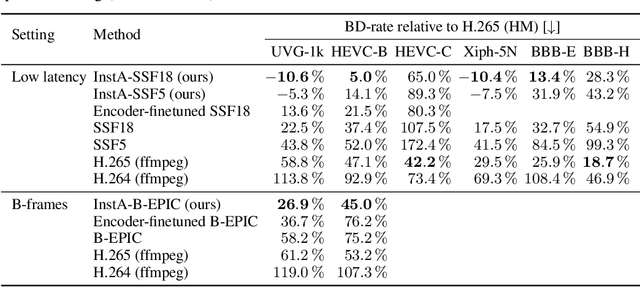
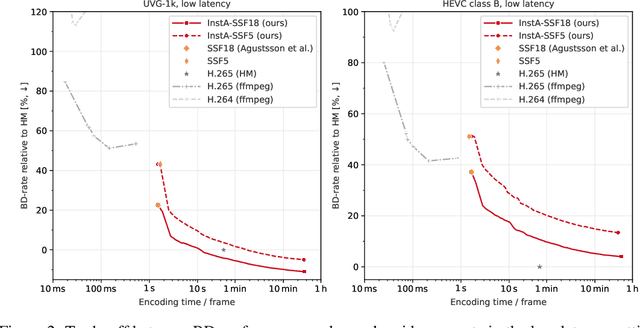
We introduce a video compression algorithm based on instance-adaptive learning. On each video sequence to be transmitted, we finetune a pretrained compression model. The optimal parameters are transmitted to the receiver along with the latent code. By entropy-coding the parameter updates under a suitable mixture model prior, we ensure that the network parameters can be encoded efficiently. This instance-adaptive compression algorithm is agnostic about the choice of base model and has the potential to improve any neural video codec. On UVG, HEVC, and Xiph datasets, our codec improves the performance of a low-latency scale-space flow model by between 21% and 26% BD-rate savings, and that of a state-of-the-art B-frame model by 17 to 20% BD-rate savings. We also demonstrate that instance-adaptive finetuning improves the robustness to domain shift. Finally, our approach reduces the capacity requirements on compression models. We show that it enables a state-of-the-art performance even after reducing the network size by 72%.
Overfitting for Fun and Profit: Instance-Adaptive Data Compression
Jan 21, 2021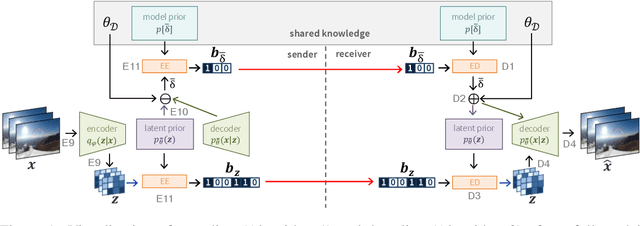


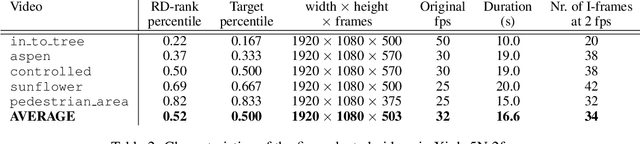
Neural data compression has been shown to outperform classical methods in terms of $RD$ performance, with results still improving rapidly. At a high level, neural compression is based on an autoencoder that tries to reconstruct the input instance from a (quantized) latent representation, coupled with a prior that is used to losslessly compress these latents. Due to limitations on model capacity and imperfect optimization and generalization, such models will suboptimally compress test data in general. However, one of the great strengths of learned compression is that if the test-time data distribution is known and relatively low-entropy (e.g. a camera watching a static scene, a dash cam in an autonomous car, etc.), the model can easily be finetuned or adapted to this distribution, leading to improved $RD$ performance. In this paper we take this concept to the extreme, adapting the full model to a single video, and sending model updates (quantized and compressed using a parameter-space prior) along with the latent representation. Unlike previous work, we finetune not only the encoder/latents but the entire model, and - during finetuning - take into account both the effect of model quantization and the additional costs incurred by sending the model updates. We evaluate an image compression model on I-frames (sampled at 2 fps) from videos of the Xiph dataset, and demonstrate that full-model adaptation improves $RD$ performance by ~1 dB, with respect to encoder-only finetuning.
Lossy Compression with Distortion Constrained Optimization
May 08, 2020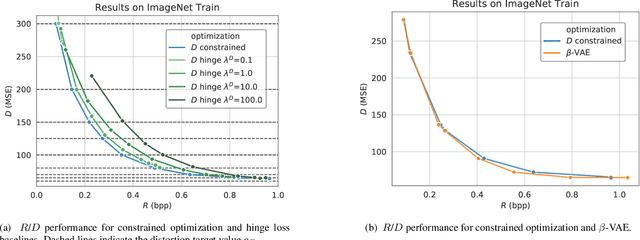
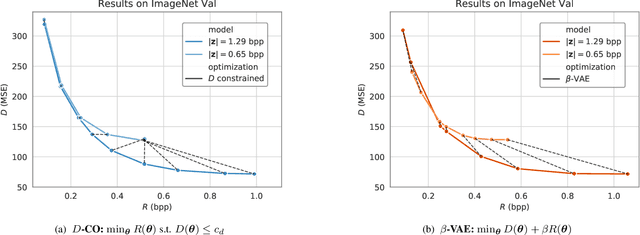
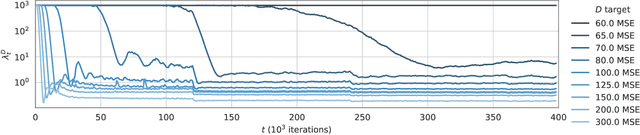
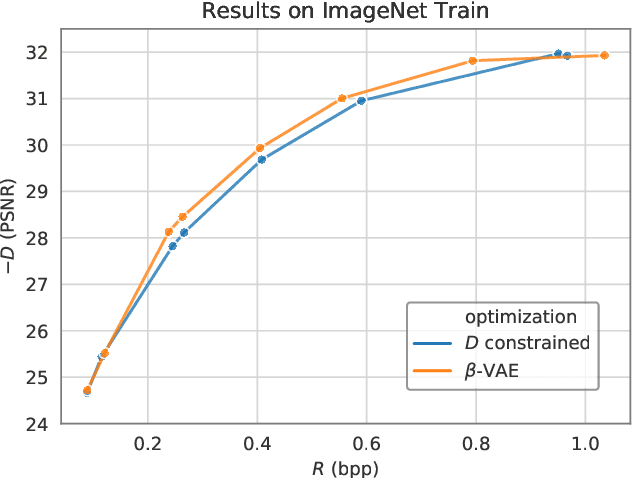
When training end-to-end learned models for lossy compression, one has to balance the rate and distortion losses. This is typically done by manually setting a tradeoff parameter $\beta$, an approach called $\beta$-VAE. Using this approach it is difficult to target a specific rate or distortion value, because the result can be very sensitive to $\beta$, and the appropriate value for $\beta$ depends on the model and problem setup. As a result, model comparison requires extensive per-model $\beta$-tuning, and producing a whole rate-distortion curve (by varying $\beta$) for each model to be compared. We argue that the constrained optimization method of Rezende and Viola, 2018 is a lot more appropriate for training lossy compression models because it allows us to obtain the best possible rate subject to a distortion constraint. This enables pointwise model comparisons, by training two models with the same distortion target and comparing their rate. We show that the method does manage to satisfy the constraint on a realistic image compression task, outperforms a constrained optimization method based on a hinge-loss, and is more practical to use for model selection than a $\beta$-VAE.
Video Compression With Rate-Distortion Autoencoders
Aug 14, 2019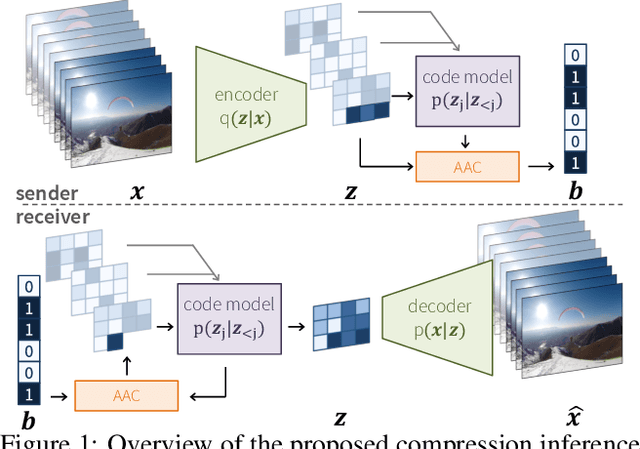
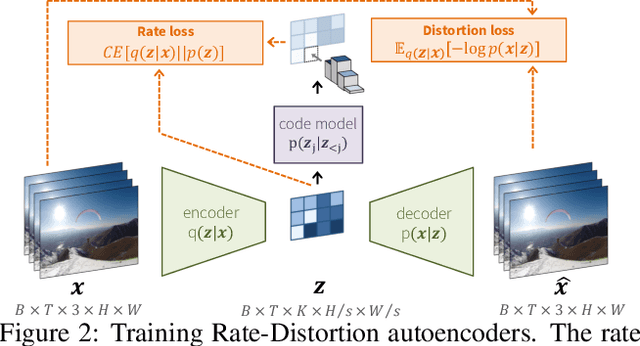
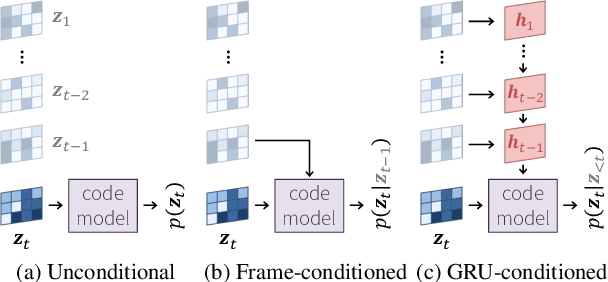

In this paper we present a a deep generative model for lossy video compression. We employ a model that consists of a 3D autoencoder with a discrete latent space and an autoregressive prior used for entropy coding. Both autoencoder and prior are trained jointly to minimize a rate-distortion loss, which is closely related to the ELBO used in variational autoencoders. Despite its simplicity, we find that our method outperforms the state-of-the-art learned video compression networks based on motion compensation or interpolation. We systematically evaluate various design choices, such as the use of frame-based or spatio-temporal autoencoders, and the type of autoregressive prior. In addition, we present three extensions of the basic method that demonstrate the benefits over classical approaches to compression. First, we introduce semantic compression, where the model is trained to allocate more bits to objects of interest. Second, we study adaptive compression, where the model is adapted to a domain with limited variability, e.g., videos taken from an autonomous car, to achieve superior compression on that domain. Finally, we introduce multimodal compression, where we demonstrate the effectiveness of our model in joint compression of multiple modalities captured by non-standard imaging sensors, such as quad cameras. We believe that this opens up novel video compression applications, which have not been feasible with classical codecs.