 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Statistical Co-occurrence: Unlocking Intrinsic Semantics for Tabular Data Clustering
Apr 13, 2026Deep Clustering (DC) has emerged as a powerful tool for tabular data analysis in real-world domains like finance and healthcare. However, most existing methods rely on data-level statistical co-occurrence to infer the latent metric space, often overlooking the intrinsic semantic knowledge encapsulated in feature names and values. As a result, semantically related concepts like `Flu' and `Cold' are often treated as symbolic tokens, causing conceptually related samples to be isolated. To bridge the gap between dataset-specific statistics and intrinsic semantic knowledge, this paper proposes Tabular-Augmented Contrastive Clustering (TagCC), a novel framework that anchors statistical tabular representations to open-world textual concepts. Specifically, TagCC utilizes Large Language Models (LLMs) to distill underlying data semantics into textual anchors via semantic-aware transformation. Through Contrastive Learning (CL), the framework enriches the statistical tabular representations with the open-world semantics encapsulated in these anchors. This CL framework is jointly optimized with a clustering objective, ensuring that the learned representations are both semantically coherent and clustering-friendly. Extensive experiments on benchmark datasets demonstrate that TagCC significantly outperforms its counterparts.
Hierarchical Multiscale Structure-Function Coupling for Brain Connectome Integration
Mar 21, 2026Integrating structural and functional connectomes remains challenging because their relationship is non-linear and organized over nested modular hierarchies. We propose a hierarchical multiscale structure-function coupling framework for connectome integration that jointly learns individualized modular organization and hierarchical coupling across structural connectivity (SC) and functional connectivity (FC). The framework includes: (i) Prototype-based Modular Pooling (PMPool), which learns modality-specific multiscale communities by selecting prototypical ROIs and optimizing a differentiable modularity-inspired objective; (ii) an Attention-based Hierarchical Coupling Module (AHCM) that models both within-hierarchy and cross-hierarchy SC-FC interactions to produce enriched hierarchical coupling representations; and (iii) a Coupling-guided Clustering loss (CgC-Loss) that regularizes SC and FC community assignments with coupling signals, allowing cross-modal interactions to shape community alignment across hierarchies. We evaluate the model's performance across four cohorts for predicting brain age, cognitive score, and disease classification. Our model consistently outperforms baselines and other state-of-the-art approaches across three tasks. Ablation and sensitivity analyses verify the contributions of key components. Finally, the visualizations of learned coupling reveal interpretable differences, suggesting that the framework captures biologically meaningful structure-function relationships.
FireBench: Evaluating Instruction Following in Enterprise and API-Driven LLM Applications
Mar 05, 2026Instruction following is critical for LLMs deployed in enterprise and API-driven settings, where strict adherence to output formats, content constraints, and procedural requirements is essential for enabling reliable LLM-assisted workflows. However, existing instruction following benchmarks predominantly evaluate natural language generation constraints that reflect the needs of chat assistants rather than enterprise users. To bridge this gap, we introduce FireBench, an LLM instruction following benchmark grounded in real-world enterprise and API usage patterns. FireBench evaluates six core capability dimensions across diverse applications including information extraction, customer support, and coding agents, comprising over 2,400 samples. We evaluate 11 LLMs and present key findings on their instruction following behavior in enterprise scenarios. We open-source FireBench at fire-bench.com to help users assess model suitability, support model developers in diagnosing performance, and invite community contributions.
LiveNewsBench: Evaluating LLM Web Search Capabilities with Freshly Curated News
Feb 14, 2026Large Language Models (LLMs) with agentic web search capabilities show strong potential for tasks requiring real-time information access and complex fact retrieval, yet evaluating such systems remains challenging. We introduce \bench, a rigorous and regularly updated benchmark designed to assess the agentic web search abilities of LLMs. \bench automatically generates fresh question-answer pairs from recent news articles, ensuring that questions require information beyond an LLM's training data and enabling clear separation between internal knowledge and search capability. The benchmark features intentionally difficult questions requiring multi-hop search queries, page visits, and reasoning, making it well-suited for evaluating agentic search behavior. Our automated data curation and question generation pipeline enables frequent benchmark updates and supports construction of a large-scale training dataset for agentic web search models, addressing the scarcity of such data in the research community. To ensure reliable evaluation, we include a subset of human-verified samples in the test set. We evaluate a broad range of systems using \bench, including commercial and open-weight LLMs as well as LLM-based web search APIs. The leaderboard, datasets, and code are publicly available at livenewsbench.com.
Forecasting Communication Derailments Through Conversation Generation
Apr 11, 2025


Forecasting communication derailment can be useful in real-world settings such as online content moderation, conflict resolution, and business negotiations. However, despite language models' success at identifying offensive speech present in conversations, they struggle to forecast future communication derailments. In contrast to prior work that predicts conversation outcomes solely based on the past conversation history, our approach samples multiple future conversation trajectories conditioned on existing conversation history using a fine-tuned LLM. It predicts the communication outcome based on the consensus of these trajectories. We also experimented with leveraging socio-linguistic attributes, which reflect turn-level conversation dynamics, as guidance when generating future conversations. Our method of future conversation trajectories surpasses state-of-the-art results on English communication derailment prediction benchmarks and demonstrates significant accuracy gains in ablation studies.
Deep Learning Waveform Modeling for Wideband Optical Fiber Channel Transmission: Challenges and Potential Solutions
Jan 14, 2025



Fast and accurate optical fiber communication simulation system are crucial for optimizing optical networks, developing digital signal processing algorithms, and performing end-to-end (E2E) optimization. Deep learning (DL) has emerged as a valuable tool to reduce the complexity of traditional waveform simulation methods, such as split-step Fourier method (SSFM). DL-based schemes have achieved high accuracy and low complexity fiber channel waveform modeling as its strong nonlinear fitting ability and high efficiency in parallel computation. However, DL-based schemes are mainly utilized in single-channel and few-channel wavelength division multiplexing (WDM) systems. The applicability of DL-based schemes in wideband WDM systems remains uncertain due to the lack of comparison under consistent standards and scenarios. In this paper, we propose a DSP-assisted accuracy evaluation method to evaluate the performance for DL-based schemes, from the aspects of waveform and quality of transmission (QoT) errors. We compare the performance of five various DL-based schemes and valid the effectiveness of DSP-assisted method in WDM systems. Results suggest that feature decoupled distributed (FDD) achieves the better accuracy, especially in large-channel and high-rate scenarios. Furthermore, we find that the accuracy of FDD still exhibit significant degradation with the number of WDM channels and transmission rates exceeds 15 and 100 GBaud, indicating challenges for wideband applications. We further analyze the reasons of performance degradation from the perspective of increased linearity and nonlinearity and discuss potential solutions including further decoupling scheme designs and improvement in DL models. Despite DL-based schemes remain challenges in wideband WDM systems, they have strong potential for high-accuracy and low-complexity optical fiber channel waveform modeling.
Asynchronous Federated Clustering with Unknown Number of Clusters
Dec 29, 2024



Federated Clustering (FC) is crucial to mining knowledge from unlabeled non-Independent Identically Distributed (non-IID) data provided by multiple clients while preserving their privacy. Most existing attempts learn cluster distributions at local clients, and then securely pass the desensitized information to the server for aggregation. However, some tricky but common FC problems are still relatively unexplored, including the heterogeneity in terms of clients' communication capacity and the unknown number of proper clusters $k^*$. To further bridge the gap between FC and real application scenarios, this paper first shows that the clients' communication asynchrony and unknown $k^*$ are complex coupling problems, and then proposes an Asynchronous Federated Cluster Learning (AFCL) method accordingly. It spreads the excessive number of seed points to the clients as a learning medium and coordinates them across the clients to form a consensus. To alleviate the distribution imbalance cumulated due to the unforeseen asynchronous uploading from the heterogeneous clients, we also design a balancing mechanism for seeds updating. As a result, the seeds gradually adapt to each other to reveal a proper number of clusters. Extensive experiments demonstrate the efficacy of AFCL.
SketchFill: Sketch-Guided Code Generation for Imputing Derived Missing Values
Dec 26, 2024



Missing value is a critical issue in data science, significantly impacting the reliability of analyses and predictions. Missing value imputation (MVI) is a longstanding problem because it highly relies on domain knowledge. Large language models (LLMs) have emerged as a promising tool for data cleaning, including MVI for tabular data, offering advanced capabilities for understanding and generating content. However, despite their promise, existing LLM techniques such as in-context learning and Chain-of-Thought (CoT) often fall short in guiding LLMs to perform complex reasoning for MVI, particularly when imputing derived missing values, which require mathematical formulas and data relationships across rows and columns. This gap underscores the need for further advancements in LLM methodologies to enhance their reasoning capabilities for more reliable imputation outcomes. To fill this gap, we propose SketchFill, a novel sketch-based method to guide LLMs in generating accurate formulas to impute missing numerical values. Our experimental results demonstrate that SketchFill significantly outperforms state-of-the-art methods, achieving 56.2% higher accuracy than CoT-based methods and 78.8% higher accuracy than MetaGPT. This sets a new standard for automated data cleaning and advances the field of MVI for numerical values.
Improve the Fitting Accuracy of Deep Learning for the Nonlinear Schrödinger Equation Using Linear Feature Decoupling Method
Nov 07, 2024We utilize the Feature Decoupling Distributed (FDD) method to enhance the capability of deep learning to fit the Nonlinear Schrodinger Equation (NLSE), significantly reducing the NLSE loss compared to non decoupling model.
Multi-modal Learnable Queries for Image Aesthetics Assessment
May 02, 2024
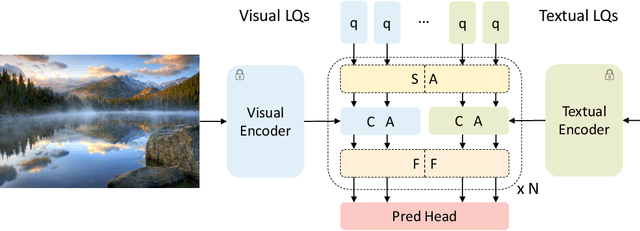
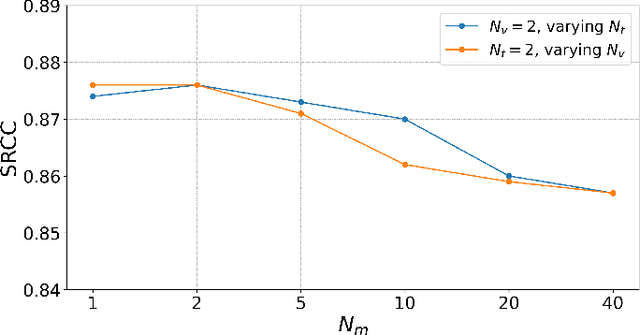
Image aesthetics assessment (IAA) is attracting wide interest with the prevalence of social media. The problem is challenging due to its subjective and ambiguous nature. Instead of directly extracting aesthetic features solely from the image, user comments associated with an image could potentially provide complementary knowledge that is useful for IAA. With existing large-scale pre-trained models demonstrating strong capabilities in extracting high-quality transferable visual and textual features, learnable queries are shown to be effective in extracting useful features from the pre-trained visual features. Therefore, in this paper, we propose MMLQ, which utilizes multi-modal learnable queries to extract aesthetics-related features from multi-modal pre-trained features. Extensive experimental results demonstrate that MMLQ achieves new state-of-the-art performance on multi-modal IAA, beating previous methods by 7.7% and 8.3% in terms of SRCC and PLCC, respectively.