 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry-Guided Reinforcement Learning for Multi-view Consistent 3D Scene Editing
Mar 03, 2026Leveraging the priors of 2D diffusion models for 3D editing has emerged as a promising paradigm. However, maintaining multi-view consistency in edited results remains challenging, and the extreme scarcity of 3D-consistent editing paired data renders supervised fine-tuning (SFT), the most effective training strategy for editing tasks, infeasible. In this paper, we observe that, while generating multi-view consistent 3D content is highly challenging, verifying 3D consistency is tractable, naturally positioning reinforcement learning (RL) as a feasible solution. Motivated by this, we propose \textbf{RL3DEdit}, a single-pass framework driven by RL optimization with novel rewards derived from the 3D foundation model, VGGT. Specifically, we leverage VGGT's robust priors learned from massive real-world data, feed the edited images, and utilize the output confidence maps and pose estimation errors as reward signals, effectively anchoring the 2D editing priors onto a 3D-consistent manifold via RL. Extensive experiments demonstrate that RL3DEdit achieves stable multi-view consistency and outperforms state-of-the-art methods in editing quality with high efficiency. To promote the development of 3D editing, we will release the code and model.
VLM-Guided Group Preference Alignment for Diffusion-based Human Mesh Recovery
Feb 22, 2026Human mesh recovery (HMR) from a single RGB image is inherently ambiguous, as multiple 3D poses can correspond to the same 2D observation. Recent diffusion-based methods tackle this by generating various hypotheses, but often sacrifice accuracy. They yield predictions that are either physically implausible or drift from the input image, especially under occlusion or in cluttered, in-the-wild scenes. To address this, we introduce a dual-memory augmented HMR critique agent with self-reflection to produce context-aware quality scores for predicted meshes. These scores distill fine-grained cues about 3D human motion structure, physical feasibility, and alignment with the input image. We use these scores to build a group-wise HMR preference dataset. Leveraging this dataset, we propose a group preference alignment framework for finetuning diffusion-based HMR models. This process injects the rich preference signals into the model, guiding it to generate more physically plausible and image-consistent human meshes. Extensive experiments demonstrate that our method achieves superior performance compared to state-of-the-art approaches.
MVAnimate: Enhancing Character Animation with Multi-View Optimization
Feb 09, 2026The demand for realistic and versatile character animation has surged, driven by its wide-ranging applications in various domains. However, the animation generation algorithms modeling human pose with 2D or 3D structures all face various problems, including low-quality output content and training data deficiency, preventing the related algorithms from generating high-quality animation videos. Therefore, we introduce MVAnimate, a novel framework that synthesizes both 2D and 3D information of dynamic figures based on multi-view prior information, to enhance the generated video quality. Our approach leverages multi-view prior information to produce temporally consistent and spatially coherent animation outputs, demonstrating improvements over existing animation methods. Our MVAnimate also optimizes the multi-view videos of the target character, enhancing the video quality from different views. Experimental results on diverse datasets highlight the robustness of our method in handling various motion patterns and appearances.
Scalable Adaptation of 3D Geometric Foundation Models via Weak Supervision from Internet Video
Feb 08, 2026Geometric foundation models show promise in 3D reconstruction, yet their progress is severely constrained by the scarcity of diverse, large-scale 3D annotations. While Internet videos offer virtually unlimited raw data, utilizing them as a scaling source for geometric learning is challenging due to the absence of ground-truth geometry and the presence of observational noise. To address this, we propose SAGE, a framework for Scalable Adaptation of GEometric foundation models from raw video streams. SAGE leverages a hierarchical mining pipeline to transform videos into training trajectories and hybrid supervision: (1) Informative training trajectory selection; (2) Sparse Geometric Anchoring via SfM point clouds for global structural guidance; and (3) Dense Differentiable Consistency via 3D Gaussian rendering for multi-view constraints. To prevent catastrophic forgetting, we introduce a regularization strategy using anchor data. Extensive experiments show that SAGE significantly enhances zero-shot generalization, reducing Chamfer Distance by 20-42% on unseen benchmarks (7Scenes, TUM-RGBD, Matterport3D) compared to state-of-the-art baselines. To our knowledge, SAGE pioneers the adaptation of geometric foundation models via Internet video, establishing a scalable paradigm for general-purpose 3D learning.
Bridging Your Imagination with Audio-Video Generation via a Unified Director
Dec 29, 2025Existing AI-driven video creation systems typically treat script drafting and key-shot design as two disjoint tasks: the former relies on large language models, while the latter depends on image generation models. We argue that these two tasks should be unified within a single framework, as logical reasoning and imaginative thinking are both fundamental qualities of a film director. In this work, we propose UniMAGE, a unified director model that bridges user prompts with well-structured scripts, thereby empowering non-experts to produce long-context, multi-shot films by leveraging existing audio-video generation models. To achieve this, we employ the Mixture-of-Transformers architecture that unifies text and image generation. To further enhance narrative logic and keyframe consistency, we introduce a ``first interleaving, then disentangling'' training paradigm. Specifically, we first perform Interleaved Concept Learning, which utilizes interleaved text-image data to foster the model's deeper understanding and imaginative interpretation of scripts. We then conduct Disentangled Expert Learning, which decouples script writing from keyframe generation, enabling greater flexibility and creativity in storytelling. Extensive experiments demonstrate that UniMAGE achieves state-of-the-art performance among open-source models, generating logically coherent video scripts and visually consistent keyframe images.
ViSA: 3D-Aware Video Shading for Real-Time Upper-Body Avatar Creation
Dec 09, 2025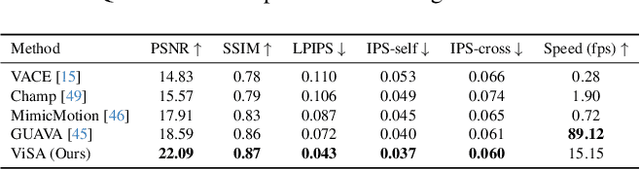
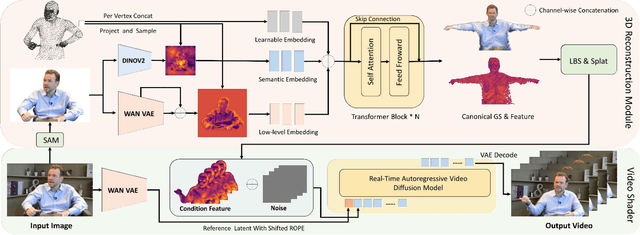
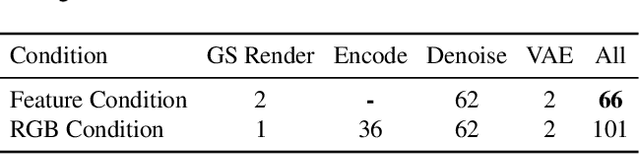
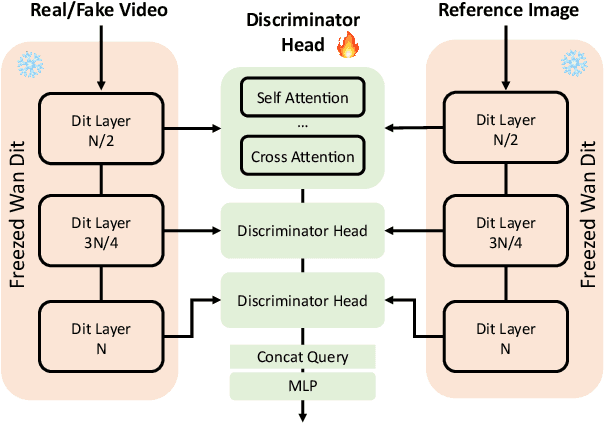
Generating high-fidelity upper-body 3D avatars from one-shot input image remains a significant challenge. Current 3D avatar generation methods, which rely on large reconstruction models, are fast and capable of producing stable body structures, but they often suffer from artifacts such as blurry textures and stiff, unnatural motion. In contrast, generative video models show promising performance by synthesizing photorealistic and dynamic results, but they frequently struggle with unstable behavior, including body structural errors and identity drift. To address these limitations, we propose a novel approach that combines the strengths of both paradigms. Our framework employs a 3D reconstruction model to provide robust structural and appearance priors, which in turn guides a real-time autoregressive video diffusion model for rendering. This process enables the model to synthesize high-frequency, photorealistic details and fluid dynamics in real time, effectively reducing texture blur and motion stiffness while preventing the structural inconsistencies common in video generation methods. By uniting the geometric stability of 3D reconstruction with the generative capabilities of video models, our method produces high-fidelity digital avatars with realistic appearance and dynamic, temporally coherent motion. Experiments demonstrate that our approach significantly reduces artifacts and achieves substantial improvements in visual quality over leading methods, providing a robust and efficient solution for real-time applications such as gaming and virtual reality. Project page: https://lhyfst.github.io/visa
Weakly and Self-Supervised Class-Agnostic Motion Prediction for Autonomous Driving
Sep 16, 2025Understanding motion in dynamic environments is critical for autonomous driving, thereby motivating research on class-agnostic motion prediction. In this work, we investigate weakly and self-supervised class-agnostic motion prediction from LiDAR point clouds. Outdoor scenes typically consist of mobile foregrounds and static backgrounds, allowing motion understanding to be associated with scene parsing. Based on this observation, we propose a novel weakly supervised paradigm that replaces motion annotations with fully or partially annotated (1%, 0.1%) foreground/background masks for supervision. To this end, we develop a weakly supervised approach utilizing foreground/background cues to guide the self-supervised learning of motion prediction models. Since foreground motion generally occurs in non-ground regions, non-ground/ground masks can serve as an alternative to foreground/background masks, further reducing annotation effort. Leveraging non-ground/ground cues, we propose two additional approaches: a weakly supervised method requiring fewer (0.01%) foreground/background annotations, and a self-supervised method without annotations. Furthermore, we design a Robust Consistency-aware Chamfer Distance loss that incorporates multi-frame information and robust penalty functions to suppress outliers in self-supervised learning. Experiments show that our weakly and self-supervised models outperform existing self-supervised counterparts, and our weakly supervised models even rival some supervised ones. This demonstrates that our approaches effectively balance annotation effort and performance.
Integrating SAM Supervision for 3D Weakly Supervised Point Cloud Segmentation
Aug 27, 2025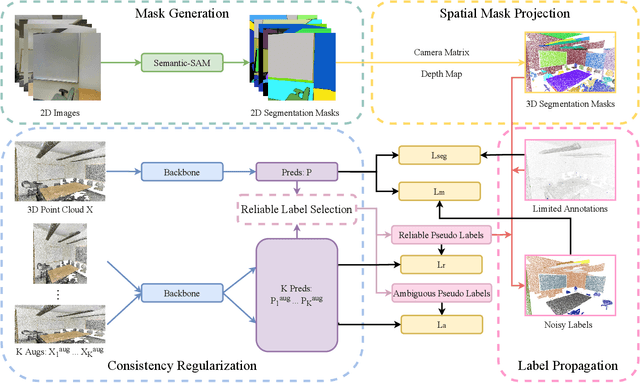
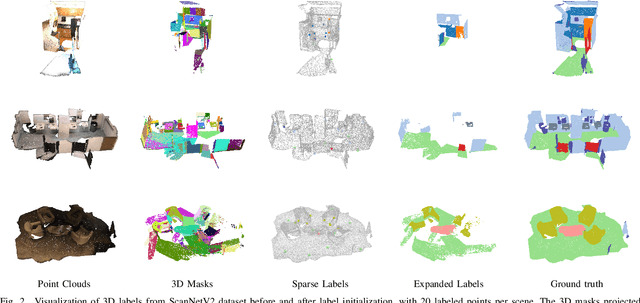


Current methods for 3D semantic segmentation propose training models with limited annotations to address the difficulty of annotating large, irregular, and unordered 3D point cloud data. They usually focus on the 3D domain only, without leveraging the complementary nature of 2D and 3D data. Besides, some methods extend original labels or generate pseudo labels to guide the training, but they often fail to fully use these labels or address the noise within them. Meanwhile, the emergence of comprehensive and adaptable foundation models has offered effective solutions for segmenting 2D data. Leveraging this advancement, we present a novel approach that maximizes the utility of sparsely available 3D annotations by incorporating segmentation masks generated by 2D foundation models. We further propagate the 2D segmentation masks into the 3D space by establishing geometric correspondences between 3D scenes and 2D views. We extend the highly sparse annotations to encompass the areas delineated by 3D masks, thereby substantially augmenting the pool of available labels. Furthermore, we apply confidence- and uncertainty-based consistency regularization on augmentations of the 3D point cloud and select the reliable pseudo labels, which are further spread on the 3D masks to generate more labels. This innovative strategy bridges the gap between limited 3D annotations and the powerful capabilities of 2D foundation models, ultimately improving the performance of 3D weakly supervised segmentation.
Puppeteer: Rig and Animate Your 3D Models
Aug 14, 2025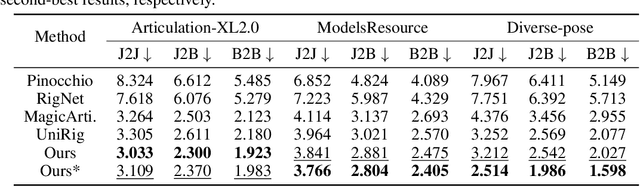

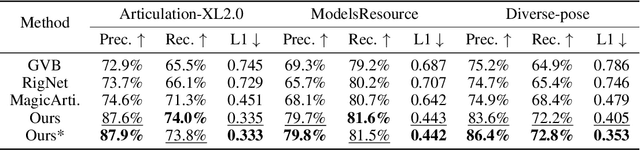

Modern interactive applications increasingly demand dynamic 3D content, yet the transformation of static 3D models into animated assets constitutes a significant bottleneck in content creation pipelines. While recent advances in generative AI have revolutionized static 3D model creation, rigging and animation continue to depend heavily on expert intervention. We present Puppeteer, a comprehensive framework that addresses both automatic rigging and animation for diverse 3D objects. Our system first predicts plausible skeletal structures via an auto-regressive transformer that introduces a joint-based tokenization strategy for compact representation and a hierarchical ordering methodology with stochastic perturbation that enhances bidirectional learning capabilities. It then infers skinning weights via an attention-based architecture incorporating topology-aware joint attention that explicitly encodes inter-joint relationships based on skeletal graph distances. Finally, we complement these rigging advances with a differentiable optimization-based animation pipeline that generates stable, high-fidelity animations while being computationally more efficient than existing approaches. Extensive evaluations across multiple benchmarks demonstrate that our method significantly outperforms state-of-the-art techniques in both skeletal prediction accuracy and skinning quality. The system robustly processes diverse 3D content, ranging from professionally designed game assets to AI-generated shapes, producing temporally coherent animations that eliminate the jittering issues common in existing methods.
Ultra3D: Efficient and High-Fidelity 3D Generation with Part Attention
Jul 23, 2025



Recent advances in sparse voxel representations have significantly improved the quality of 3D content generation, enabling high-resolution modeling with fine-grained geometry. However, existing frameworks suffer from severe computational inefficiencies due to the quadratic complexity of attention mechanisms in their two-stage diffusion pipelines. In this work, we propose Ultra3D, an efficient 3D generation framework that significantly accelerates sparse voxel modeling without compromising quality. Our method leverages the compact VecSet representation to efficiently generate a coarse object layout in the first stage, reducing token count and accelerating voxel coordinate prediction. To refine per-voxel latent features in the second stage, we introduce Part Attention, a geometry-aware localized attention mechanism that restricts attention computation within semantically consistent part regions. This design preserves structural continuity while avoiding unnecessary global attention, achieving up to 6.7x speed-up in latent generation. To support this mechanism, we construct a scalable part annotation pipeline that converts raw meshes into part-labeled sparse voxels. Extensive experiments demonstrate that Ultra3D supports high-resolution 3D generation at 1024 resolution and achieves state-of-the-art performance in both visual fidelity and user preference.