 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTacoDepth: Towards Efficient Radar-Camera Depth Estimation with One-stage Fusion
Apr 16, 2025



Radar-Camera depth estimation aims to predict dense and accurate metric depth by fusing input images and Radar data. Model efficiency is crucial for this task in pursuit of real-time processing on autonomous vehicles and robotic platforms. However, due to the sparsity of Radar returns, the prevailing methods adopt multi-stage frameworks with intermediate quasi-dense depth, which are time-consuming and not robust. To address these challenges, we propose TacoDepth, an efficient and accurate Radar-Camera depth estimation model with one-stage fusion. Specifically, the graph-based Radar structure extractor and the pyramid-based Radar fusion module are designed to capture and integrate the graph structures of Radar point clouds, delivering superior model efficiency and robustness without relying on the intermediate depth results. Moreover, TacoDepth can be flexible for different inference modes, providing a better balance of speed and accuracy. Extensive experiments are conducted to demonstrate the efficacy of our method. Compared with the previous state-of-the-art approach, TacoDepth improves depth accuracy and processing speed by 12.8% and 91.8%. Our work provides a new perspective on efficient Radar-Camera depth estimation.
Semi-synthesis: A fast way to produce effective datasets for stereo matching
Jan 26, 2021
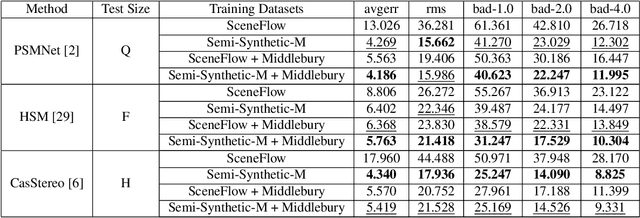

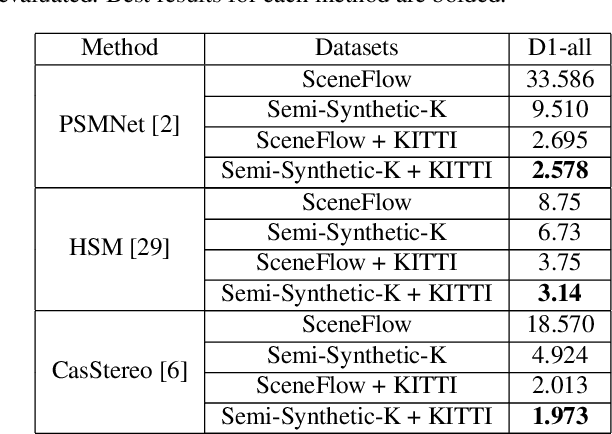
Stereo matching is an important problem in computer vision which has drawn tremendous research attention for decades. Recent years, data-driven methods with convolutional neural networks (CNNs) are continuously pushing stereo matching to new heights. However, data-driven methods require large amount of training data, which is not an easy task for real stereo data due to the annotation difficulties of per-pixel ground-truth disparity. Though synthetic dataset is proposed to fill the gaps of large data demand, the fine-tuning on real dataset is still needed due to the domain variances between synthetic data and real data. In this paper, we found that in synthetic datasets, close-to-real-scene texture rendering is a key factor to boost up stereo matching performance, while close-to-real-scene 3D modeling is less important. We then propose semi-synthetic, an effective and fast way to synthesize large amount of data with close-to-real-scene texture to minimize the gap between synthetic data and real data. Extensive experiments demonstrate that models trained with our proposed semi-synthetic datasets achieve significantly better performance than with general synthetic datasets, especially on real data benchmarks with limited training data. With further fine-tuning on the real dataset, we also achieve SOTA performance on Middlebury and competitive results on KITTI and ETH3D datasets.