 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow Light Image Enhancement Challenge at NTIRE 2026
Apr 19, 2026This paper presents a comprehensive review of the NTIRE 2026 Low Light Image Enhancement Challenge, highlighting the proposed solutions and final results. The objective of this challenge is to identify effective networks capable of producing clearer and visually compelling images in diverse and challenging conditions by learning representative visual cues with the purpose of restoring information loss due to low-contrast and noisy images. A total of 195 participants registered for the first track and 153 for the second track of the competition, and 22 teams ultimately submitted valid entries. This paper thoroughly evaluates the state-of-the-art advances in (joint denoising and) low-light image enhancement, showcasing the significant progress in the field, while leveraging samples of our novel dataset.
The Fourth Challenge on Image Super-Resolution ($\times$4) at NTIRE 2026: Benchmark Results and Method Overview
Apr 16, 2026This paper presents the NTIRE 2026 image super-resolution ($\times$4) challenge, one of the associated competitions of the NTIRE 2026 Workshop at CVPR 2026. The challenge aims to reconstruct high-resolution (HR) images from low-resolution (LR) inputs generated through bicubic downsampling with a $\times$4 scaling factor. The objective is to develop effective super-resolution solutions and analyze recent advances in the field. To reflect the evolving objectives of image super-resolution, the challenge includes two tracks: (1) a restoration track, which emphasizes pixel-wise fidelity and ranks submissions based on PSNR; and (2) a perceptual track, which focuses on visual realism and evaluates results using a perceptual score. A total of 194 participants registered for the challenge, with 31 teams submitting valid entries. This report summarizes the challenge design, datasets, evaluation protocol, main results, and methods of participating teams. The challenge provides a unified benchmark and offers insights into current progress and future directions in image super-resolution.
GEditBench v2: A Human-Aligned Benchmark for General Image Editing
Mar 30, 2026Recent advances in image editing have enabled models to handle complex instructions with impressive realism. However, existing evaluation frameworks lag behind: current benchmarks suffer from narrow task coverage, while standard metrics fail to adequately capture visual consistency, i.e., the preservation of identity, structure and semantic coherence between edited and original images. To address these limitations, we introduce GEditBench v2, a comprehensive benchmark with 1,200 real-world user queries spanning 23 tasks, including a dedicated open-set category for unconstrained, out-of-distribution editing instructions beyond predefined tasks. Furthermore, we propose PVC-Judge, an open-source pairwise assessment model for visual consistency, trained via two novel region-decoupled preference data synthesis pipelines. Besides, we construct VCReward-Bench using expert-annotated preference pairs to assess the alignment of PVC-Judge with human judgments on visual consistency evaluation. Experiments show that our PVC-Judge achieves state-of-the-art evaluation performance among open-source models and even surpasses GPT-5.1 on average. Finally, by benchmarking 16 frontier editing models, we show that GEditBench v2 enables more human-aligned evaluation, revealing critical limitations of current models, and providing a reliable foundation for advancing precise image editing.
RealRestorer: Towards Generalizable Real-World Image Restoration with Large-Scale Image Editing Models
Mar 26, 2026Image restoration under real-world degradations is critical for downstream tasks such as autonomous driving and object detection. However, existing restoration models are often limited by the scale and distribution of their training data, resulting in poor generalization to real-world scenarios. Recently, large-scale image editing models have shown strong generalization ability in restoration tasks, especially for closed-source models like Nano Banana Pro, which can restore images while preserving consistency. Nevertheless, achieving such performance with those large universal models requires substantial data and computational costs. To address this issue, we construct a large-scale dataset covering nine common real-world degradation types and train a state-of-the-art open-source model to narrow the gap with closed-source alternatives. Furthermore, we introduce RealIR-Bench, which contains 464 real-world degraded images and tailored evaluation metrics focusing on degradation removal and consistency preservation. Extensive experiments demonstrate our model ranks first among open-source methods, achieving state-of-the-art performance.
OmniLottie: Generating Vector Animations via Parameterized Lottie Tokens
Mar 02, 2026OmniLottie is a versatile framework that generates high quality vector animations from multi-modal instructions. For flexible motion and visual content control, we focus on Lottie, a light weight JSON formatting for both shapes and animation behaviors representation. However, the raw Lottie JSON files contain extensive invariant structural metadata and formatting tokens, posing significant challenges for learning vector animation generation. Therefore, we introduce a well designed Lottie tokenizer that transforms JSON files into structured sequences of commands and parameters representing shapes, animation functions and control parameters. Such tokenizer enables us to build OmniLottie upon pretrained vision language models to follow multi-modal interleaved instructions and generate high quality vector animations. To further advance research in vector animation generation, we curate MMLottie-2M, a large scale dataset of professionally designed vector animations paired with textual and visual annotations. With extensive experiments, we validate that OmniLottie can produce vivid and semantically aligned vector animations that adhere closely to multi modal human instructions.
WithAnyone: Towards Controllable and ID Consistent Image Generation
Oct 16, 2025Identity-consistent generation has become an important focus in text-to-image research, with recent models achieving notable success in producing images aligned with a reference identity. Yet, the scarcity of large-scale paired datasets containing multiple images of the same individual forces most approaches to adopt reconstruction-based training. This reliance often leads to a failure mode we term copy-paste, where the model directly replicates the reference face rather than preserving identity across natural variations in pose, expression, or lighting. Such over-similarity undermines controllability and limits the expressive power of generation. To address these limitations, we (1) construct a large-scale paired dataset MultiID-2M, tailored for multi-person scenarios, providing diverse references for each identity; (2) introduce a benchmark that quantifies both copy-paste artifacts and the trade-off between identity fidelity and variation; and (3) propose a novel training paradigm with a contrastive identity loss that leverages paired data to balance fidelity with diversity. These contributions culminate in WithAnyone, a diffusion-based model that effectively mitigates copy-paste while preserving high identity similarity. Extensive qualitative and quantitative experiments demonstrate that WithAnyone significantly reduces copy-paste artifacts, improves controllability over pose and expression, and maintains strong perceptual quality. User studies further validate that our method achieves high identity fidelity while enabling expressive controllable generation.
SC-Captioner: Improving Image Captioning with Self-Correction by Reinforcement Learning
Aug 08, 2025We propose SC-Captioner, a reinforcement learning framework that enables the self-correcting capability of image caption models. Our crucial technique lies in the design of the reward function to incentivize accurate caption corrections. Specifically, the predicted and reference captions are decomposed into object, attribute, and relation sets using scene-graph parsing algorithms. We calculate the set difference between sets of initial and self-corrected captions to identify added and removed elements. These elements are matched against the reference sets to calculate correctness bonuses for accurate refinements and mistake punishments for wrong additions and removals, thereby forming the final reward. For image caption quality assessment, we propose a set of metrics refined from CAPTURE that alleviate its incomplete precision evaluation and inefficient relation matching problems. Furthermore, we collect a fine-grained annotated image caption dataset, RefinedCaps, consisting of 6.5K diverse images from COCO dataset. Experiments show that applying SC-Captioner on large visual-language models can generate better image captions across various scenarios, significantly outperforming the direct preference optimization training strategy.
OneIG-Bench: Omni-dimensional Nuanced Evaluation for Image Generation
Jun 09, 2025Text-to-image (T2I) models have garnered significant attention for generating high-quality images aligned with text prompts. However, rapid T2I model advancements reveal limitations in early benchmarks, lacking comprehensive evaluations, for example, the evaluation on reasoning, text rendering and style. Notably, recent state-of-the-art models, with their rich knowledge modeling capabilities, show promising results on the image generation problems requiring strong reasoning ability, yet existing evaluation systems have not adequately addressed this frontier. To systematically address these gaps, we introduce OneIG-Bench, a meticulously designed comprehensive benchmark framework for fine-grained evaluation of T2I models across multiple dimensions, including prompt-image alignment, text rendering precision, reasoning-generated content, stylization, and diversity. By structuring the evaluation, this benchmark enables in-depth analysis of model performance, helping researchers and practitioners pinpoint strengths and bottlenecks in the full pipeline of image generation. Specifically, OneIG-Bench enables flexible evaluation by allowing users to focus on a particular evaluation subset. Instead of generating images for the entire set of prompts, users can generate images only for the prompts associated with the selected dimension and complete the corresponding evaluation accordingly. Our codebase and dataset are now publicly available to facilitate reproducible evaluation studies and cross-model comparisons within the T2I research community.
DreamDance: Animating Character Art via Inpainting Stable Gaussian Worlds
May 30, 2025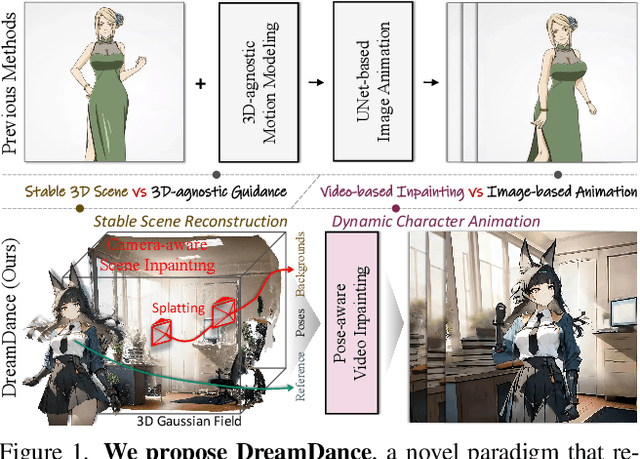

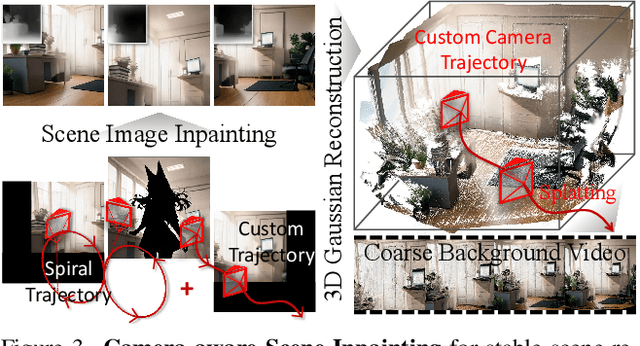
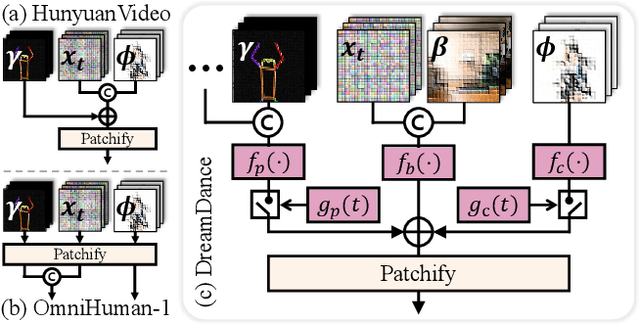
This paper presents DreamDance, a novel character art animation framework capable of producing stable, consistent character and scene motion conditioned on precise camera trajectories. To achieve this, we re-formulate the animation task as two inpainting-based steps: Camera-aware Scene Inpainting and Pose-aware Video Inpainting. The first step leverages a pre-trained image inpainting model to generate multi-view scene images from the reference art and optimizes a stable large-scale Gaussian field, which enables coarse background video rendering with camera trajectories. However, the rendered video is rough and only conveys scene motion. To resolve this, the second step trains a pose-aware video inpainting model that injects the dynamic character into the scene video while enhancing background quality. Specifically, this model is a DiT-based video generation model with a gating strategy that adaptively integrates the character's appearance and pose information into the base background video. Through extensive experiments, we demonstrate the effectiveness and generalizability of DreamDance, producing high-quality and consistent character animations with remarkable camera dynamics.
ViStoryBench: Comprehensive Benchmark Suite for Story Visualization
May 30, 2025Story visualization, which aims to generate a sequence of visually coherent images aligning with a given narrative and reference images, has seen significant progress with recent advancements in generative models. To further enhance the performance of story visualization frameworks in real-world scenarios, we introduce a comprehensive evaluation benchmark, ViStoryBench. We collect a diverse dataset encompassing various story types and artistic styles, ensuring models are evaluated across multiple dimensions such as different plots (e.g., comedy, horror) and visual aesthetics (e.g., anime, 3D renderings). ViStoryBench is carefully curated to balance narrative structures and visual elements, featuring stories with single and multiple protagonists to test models' ability to maintain character consistency. Additionally, it includes complex plots and intricate world-building to challenge models in generating accurate visuals. To ensure comprehensive comparisons, our benchmark incorporates a wide range of evaluation metrics assessing critical aspects. This structured and multifaceted framework enables researchers to thoroughly identify both the strengths and weaknesses of different models, fostering targeted improvements.