 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUrban Neural Surface Reconstruction from Constrained Sparse Aerial Imagery with 3D SAR Fusion
Jan 29, 2026Neural surface reconstruction (NSR) has recently shown strong potential for urban 3D reconstruction from multi-view aerial imagery. However, existing NSR methods often suffer from geometric ambiguity and instability, particularly under sparse-view conditions. This issue is critical in large-scale urban remote sensing, where aerial image acquisition is limited by flight paths, terrain, and cost. To address this challenge, we present the first urban NSR framework that fuses 3D synthetic aperture radar (SAR) point clouds with aerial imagery for high-fidelity reconstruction under constrained, sparse-view settings. 3D SAR can efficiently capture large-scale geometry even from a single side-looking flight path, providing robust priors that complement photometric cues from images. Our framework integrates radar-derived spatial constraints into an SDF-based NSR backbone, guiding structure-aware ray selection and adaptive sampling for stable and efficient optimization. We also construct the first benchmark dataset with co-registered 3D SAR point clouds and aerial imagery, facilitating systematic evaluation of cross-modal 3D reconstruction. Extensive experiments show that incorporating 3D SAR markedly enhances reconstruction accuracy, completeness, and robustness compared with single-modality baselines under highly sparse and oblique-view conditions, highlighting a viable route toward scalable high-fidelity urban reconstruction with advanced airborne and spaceborne optical-SAR sensing.
EmbodiedOneVision: Interleaved Vision-Text-Action Pretraining for General Robot Control
Aug 28, 2025The human ability to seamlessly perform multimodal reasoning and physical interaction in the open world is a core goal for general-purpose embodied intelligent systems. Recent vision-language-action (VLA) models, which are co-trained on large-scale robot and visual-text data, have demonstrated notable progress in general robot control. However, they still fail to achieve human-level flexibility in interleaved reasoning and interaction. In this work, introduce EO-Robotics, consists of EO-1 model and EO-Data1.5M dataset. EO-1 is a unified embodied foundation model that achieves superior performance in multimodal embodied reasoning and robot control through interleaved vision-text-action pre-training. The development of EO-1 is based on two key pillars: (i) a unified architecture that processes multimodal inputs indiscriminately (image, text, video, and action), and (ii) a massive, high-quality multimodal embodied reasoning dataset, EO-Data1.5M, which contains over 1.5 million samples with emphasis on interleaved vision-text-action comprehension. EO-1 is trained through synergies between auto-regressive decoding and flow matching denoising on EO-Data1.5M, enabling seamless robot action generation and multimodal embodied reasoning. Extensive experiments demonstrate the effectiveness of interleaved vision-text-action learning for open-world understanding and generalization, validated through a variety of long-horizon, dexterous manipulation tasks across multiple embodiments. This paper details the architecture of EO-1, the data construction strategy of EO-Data1.5M, and the training methodology, offering valuable insights for developing advanced embodied foundation models.
StyleMe3D: Stylization with Disentangled Priors by Multiple Encoders on 3D Gaussians
Apr 21, 20253D Gaussian Splatting (3DGS) excels in photorealistic scene reconstruction but struggles with stylized scenarios (e.g., cartoons, games) due to fragmented textures, semantic misalignment, and limited adaptability to abstract aesthetics. We propose StyleMe3D, a holistic framework for 3D GS style transfer that integrates multi-modal style conditioning, multi-level semantic alignment, and perceptual quality enhancement. Our key insights include: (1) optimizing only RGB attributes preserves geometric integrity during stylization; (2) disentangling low-, medium-, and high-level semantics is critical for coherent style transfer; (3) scalability across isolated objects and complex scenes is essential for practical deployment. StyleMe3D introduces four novel components: Dynamic Style Score Distillation (DSSD), leveraging Stable Diffusion's latent space for semantic alignment; Contrastive Style Descriptor (CSD) for localized, content-aware texture transfer; Simultaneously Optimized Scale (SOS) to decouple style details and structural coherence; and 3D Gaussian Quality Assessment (3DG-QA), a differentiable aesthetic prior trained on human-rated data to suppress artifacts and enhance visual harmony. Evaluated on NeRF synthetic dataset (objects) and tandt db (scenes) datasets, StyleMe3D outperforms state-of-the-art methods in preserving geometric details (e.g., carvings on sculptures) and ensuring stylistic consistency across scenes (e.g., coherent lighting in landscapes), while maintaining real-time rendering. This work bridges photorealistic 3D GS and artistic stylization, unlocking applications in gaming, virtual worlds, and digital art.
Sparse Multi-baseline SAR Cross-modal 3D Reconstruction of Vehicle Targets
Jun 06, 2024



Multi-baseline SAR 3D imaging faces significant challenges due to data sparsity. In recent years, deep learning techniques have achieved notable success in enhancing the quality of sparse SAR 3D imaging. However, previous work typically rely on full-aperture high-resolution radar images to supervise the training of deep neural networks (DNNs), utilizing only single-modal information from radar data. Consequently, imaging performance is limited, and acquiring full-aperture data for multi-baseline SAR is costly and sometimes impractical in real-world applications. In this paper, we propose a Cross-Modal Reconstruction Network (CMR-Net), which integrates differentiable render and cross-modal supervision with optical images to reconstruct highly sparse multi-baseline SAR 3D images of vehicle targets into visually structured and high-resolution images. We meticulously designed the network architecture and training strategies to enhance network generalization capability. Remarkably, CMR-Net, trained solely on simulated data, demonstrates high-resolution reconstruction capabilities on both publicly available simulation datasets and real measured datasets, outperforming traditional sparse reconstruction algorithms based on compressed sensing and other learning-based methods. Additionally, using optical images as supervision provides a cost-effective way to build training datasets, reducing the difficulty of method dissemination. Our work showcases the broad prospects of deep learning in multi-baseline SAR 3D imaging and offers a novel path for researching radar imaging based on cross-modal learning theory.
OMG: Towards Open-vocabulary Motion Generation via Mixture of Controllers
Dec 18, 2023

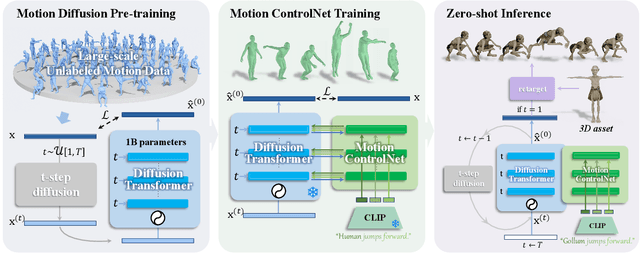
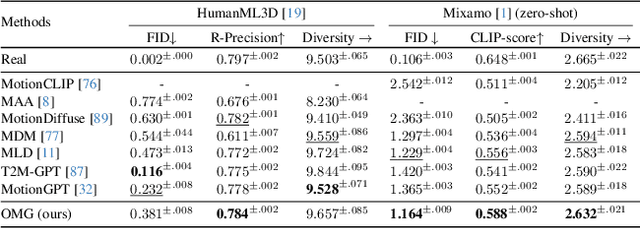
We have recently seen tremendous progress in realistic text-to-motion generation. Yet, the existing methods often fail or produce implausible motions with unseen text inputs, which limits the applications. In this paper, we present OMG, a novel framework, which enables compelling motion generation from zero-shot open-vocabulary text prompts. Our key idea is to carefully tailor the pretrain-then-finetune paradigm into the text-to-motion generation. At the pre-training stage, our model improves the generation ability by learning the rich out-of-domain inherent motion traits. To this end, we scale up a large unconditional diffusion model up to 1B parameters, so as to utilize the massive unlabeled motion data up to over 20M motion instances. At the subsequent fine-tuning stage, we introduce motion ControlNet, which incorporates text prompts as conditioning information, through a trainable copy of the pre-trained model and the proposed novel Mixture-of-Controllers (MoC) block. MoC block adaptively recognizes various ranges of the sub-motions with a cross-attention mechanism and processes them separately with the text-token-specific experts. Such a design effectively aligns the CLIP token embeddings of text prompts to various ranges of compact and expressive motion features. Extensive experiments demonstrate that our OMG achieves significant improvements over the state-of-the-art methods on zero-shot text-to-motion generation. Project page: https://tr3e.github.io/omg-page.