 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLaVA-SLT: Visual Language Tuning for Sign Language Translation
Dec 21, 2024



In the realm of Sign Language Translation (SLT), reliance on costly gloss-annotated datasets has posed a significant barrier. Recent advancements in gloss-free SLT methods have shown promise, yet they often largely lag behind gloss-based approaches in terms of translation accuracy. To narrow this performance gap, we introduce LLaVA-SLT, a pioneering Large Multimodal Model (LMM) framework designed to leverage the power of Large Language Models (LLMs) through effectively learned visual language embeddings. Our model is trained through a trilogy. First, we propose linguistic continued pretraining. We scale up the LLM and adapt it to the sign language domain using an extensive corpus dataset, effectively enhancing its textual linguistic knowledge about sign language. Then, we adopt visual contrastive pretraining to align the visual encoder with a large-scale pretrained text encoder. We propose hierarchical visual encoder that learns a robust word-level intermediate representation that is compatible with LLM token embeddings. Finally, we propose visual language tuning. We freeze pretrained models and employ a lightweight trainable MLP connector. It efficiently maps the pretrained visual language embeddings into the LLM token embedding space, enabling downstream SLT task. Our comprehensive experiments demonstrate that LLaVA-SLT outperforms the state-of-the-art methods. By using extra annotation-free data, it even closes to the gloss-based accuracy.
OMG: Towards Open-vocabulary Motion Generation via Mixture of Controllers
Dec 18, 2023

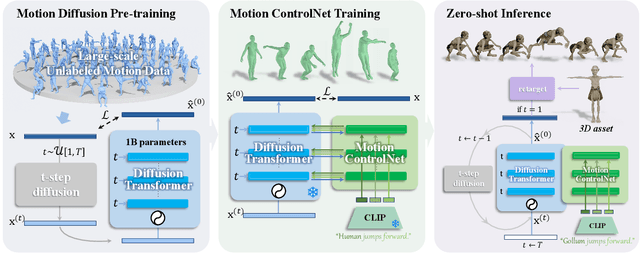
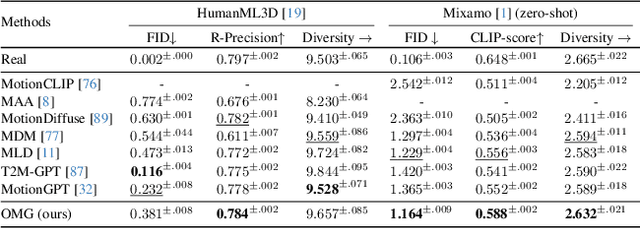
We have recently seen tremendous progress in realistic text-to-motion generation. Yet, the existing methods often fail or produce implausible motions with unseen text inputs, which limits the applications. In this paper, we present OMG, a novel framework, which enables compelling motion generation from zero-shot open-vocabulary text prompts. Our key idea is to carefully tailor the pretrain-then-finetune paradigm into the text-to-motion generation. At the pre-training stage, our model improves the generation ability by learning the rich out-of-domain inherent motion traits. To this end, we scale up a large unconditional diffusion model up to 1B parameters, so as to utilize the massive unlabeled motion data up to over 20M motion instances. At the subsequent fine-tuning stage, we introduce motion ControlNet, which incorporates text prompts as conditioning information, through a trainable copy of the pre-trained model and the proposed novel Mixture-of-Controllers (MoC) block. MoC block adaptively recognizes various ranges of the sub-motions with a cross-attention mechanism and processes them separately with the text-token-specific experts. Such a design effectively aligns the CLIP token embeddings of text prompts to various ranges of compact and expressive motion features. Extensive experiments demonstrate that our OMG achieves significant improvements over the state-of-the-art methods on zero-shot text-to-motion generation. Project page: https://tr3e.github.io/omg-page.