 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVINO: A Unified Visual Generator with Interleaved OmniModal Context
Jan 05, 2026We present VINO, a unified visual generator that performs image and video generation and editing within a single framework. Instead of relying on task-specific models or independent modules for each modality, VINO uses a shared diffusion backbone that conditions on text, images and videos, enabling a broad range of visual creation and editing tasks under one model. Specifically, VINO couples a vision-language model (VLM) with a Multimodal Diffusion Transformer (MMDiT), where multimodal inputs are encoded as interleaved conditioning tokens, and then used to guide the diffusion process. This design supports multi-reference grounding, long-form instruction following, and coherent identity preservation across static and dynamic content, while avoiding modality-specific architectural components. To train such a unified system, we introduce a multi-stage training pipeline that progressively expands a video generation base model into a unified, multi-task generator capable of both image and video input and output. Across diverse generation and editing benchmarks, VINO demonstrates strong visual quality, faithful instruction following, improved reference and attribute preservation, and more controllable multi-identity edits. Our results highlight a practical path toward scalable unified visual generation, and the promise of interleaved, in-context computation as a foundation for general-purpose visual creation.
In-Context Audio Control of Video Diffusion Transformers
Dec 21, 2025Recent advancements in video generation have seen a shift towards unified, transformer-based foundation models that can handle multiple conditional inputs in-context. However, these models have primarily focused on modalities like text, images, and depth maps, while strictly time-synchronous signals like audio have been underexplored. This paper introduces In-Context Audio Control of video diffusion transformers (ICAC), a framework that investigates the integration of audio signals for speech-driven video generation within a unified full-attention architecture, akin to FullDiT. We systematically explore three distinct mechanisms for injecting audio conditions: standard cross-attention, 2D self-attention, and unified 3D self-attention. Our findings reveal that while 3D attention offers the highest potential for capturing spatio-temporal audio-visual correlations, it presents significant training challenges. To overcome this, we propose a Masked 3D Attention mechanism that constrains the attention pattern to enforce temporal alignment, enabling stable training and superior performance. Our experiments demonstrate that this approach achieves strong lip synchronization and video quality, conditioned on an audio stream and reference images.
Kling-Omni Technical Report
Dec 18, 2025



We present Kling-Omni, a generalist generative framework designed to synthesize high-fidelity videos directly from multimodal visual language inputs. Adopting an end-to-end perspective, Kling-Omni bridges the functional separation among diverse video generation, editing, and intelligent reasoning tasks, integrating them into a holistic system. Unlike disjointed pipeline approaches, Kling-Omni supports a diverse range of user inputs, including text instructions, reference images, and video contexts, processing them into a unified multimodal representation to deliver cinematic-quality and highly-intelligent video content creation. To support these capabilities, we constructed a comprehensive data system that serves as the foundation for multimodal video creation. The framework is further empowered by efficient large-scale pre-training strategies and infrastructure optimizations for inference. Comprehensive evaluations reveal that Kling-Omni demonstrates exceptional capabilities in in-context generation, reasoning-based editing, and multimodal instruction following. Moving beyond a content creation tool, we believe Kling-Omni is a pivotal advancement toward multimodal world simulators capable of perceiving, reasoning, generating and interacting with the dynamic and complex worlds.
FullDiT2: Efficient In-Context Conditioning for Video Diffusion Transformers
Jun 05, 2025


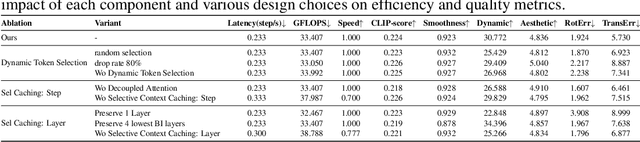
Fine-grained and efficient controllability on video diffusion transformers has raised increasing desires for the applicability. Recently, In-context Conditioning emerged as a powerful paradigm for unified conditional video generation, which enables diverse controls by concatenating varying context conditioning signals with noisy video latents into a long unified token sequence and jointly processing them via full-attention, e.g., FullDiT. Despite their effectiveness, these methods face quadratic computation overhead as task complexity increases, hindering practical deployment. In this paper, we study the efficiency bottleneck neglected in original in-context conditioning video generation framework. We begin with systematic analysis to identify two key sources of the computation inefficiencies: the inherent redundancy within context condition tokens and the computational redundancy in context-latent interactions throughout the diffusion process. Based on these insights, we propose FullDiT2, an efficient in-context conditioning framework for general controllability in both video generation and editing tasks, which innovates from two key perspectives. Firstly, to address the token redundancy, FullDiT2 leverages a dynamic token selection mechanism to adaptively identify important context tokens, reducing the sequence length for unified full-attention. Additionally, a selective context caching mechanism is devised to minimize redundant interactions between condition tokens and video latents. Extensive experiments on six diverse conditional video editing and generation tasks demonstrate that FullDiT2 achieves significant computation reduction and 2-3 times speedup in averaged time cost per diffusion step, with minimal degradation or even higher performance in video generation quality. The project page is at \href{https://fulldit2.github.io/}{https://fulldit2.github.io/}.
Any2Caption:Interpreting Any Condition to Caption for Controllable Video Generation
Mar 31, 2025



To address the bottleneck of accurate user intent interpretation within the current video generation community, we present Any2Caption, a novel framework for controllable video generation under any condition. The key idea is to decouple various condition interpretation steps from the video synthesis step. By leveraging modern multimodal large language models (MLLMs), Any2Caption interprets diverse inputs--text, images, videos, and specialized cues such as region, motion, and camera poses--into dense, structured captions that offer backbone video generators with better guidance. We also introduce Any2CapIns, a large-scale dataset with 337K instances and 407K conditions for any-condition-to-caption instruction tuning. Comprehensive evaluations demonstrate significant improvements of our system in controllability and video quality across various aspects of existing video generation models. Project Page: https://sqwu.top/Any2Cap/
SketchVideo: Sketch-based Video Generation and Editing
Mar 30, 2025



Video generation and editing conditioned on text prompts or images have undergone significant advancements. However, challenges remain in accurately controlling global layout and geometry details solely by texts, and supporting motion control and local modification through images. In this paper, we aim to achieve sketch-based spatial and motion control for video generation and support fine-grained editing of real or synthetic videos. Based on the DiT video generation model, we propose a memory-efficient control structure with sketch control blocks that predict residual features of skipped DiT blocks. Sketches are drawn on one or two keyframes (at arbitrary time points) for easy interaction. To propagate such temporally sparse sketch conditions across all frames, we propose an inter-frame attention mechanism to analyze the relationship between the keyframes and each video frame. For sketch-based video editing, we design an additional video insertion module that maintains consistency between the newly edited content and the original video's spatial feature and dynamic motion. During inference, we use latent fusion for the accurate preservation of unedited regions. Extensive experiments demonstrate that our SketchVideo achieves superior performance in controllable video generation and editing.
FullDiT: Multi-Task Video Generative Foundation Model with Full Attention
Mar 25, 2025Current video generative foundation models primarily focus on text-to-video tasks, providing limited control for fine-grained video content creation. Although adapter-based approaches (e.g., ControlNet) enable additional controls with minimal fine-tuning, they encounter challenges when integrating multiple conditions, including: branch conflicts between independently trained adapters, parameter redundancy leading to increased computational cost, and suboptimal performance compared to full fine-tuning. To address these challenges, we introduce FullDiT, a unified foundation model for video generation that seamlessly integrates multiple conditions via unified full-attention mechanisms. By fusing multi-task conditions into a unified sequence representation and leveraging the long-context learning ability of full self-attention to capture condition dynamics, FullDiT reduces parameter overhead, avoids conditions conflict, and shows scalability and emergent ability. We further introduce FullBench for multi-task video generation evaluation. Experiments demonstrate that FullDiT achieves state-of-the-art results, highlighting the efficacy of full-attention in complex multi-task video generation.
CoSurfGS:Collaborative 3D Surface Gaussian Splatting with Distributed Learning for Large Scene Reconstruction
Dec 23, 20243D Gaussian Splatting (3DGS) has demonstrated impressive performance in scene reconstruction. However, most existing GS-based surface reconstruction methods focus on 3D objects or limited scenes. Directly applying these methods to large-scale scene reconstruction will pose challenges such as high memory costs, excessive time consumption, and lack of geometric detail, which makes it difficult to implement in practical applications. To address these issues, we propose a multi-agent collaborative fast 3DGS surface reconstruction framework based on distributed learning for large-scale surface reconstruction. Specifically, we develop local model compression (LMC) and model aggregation schemes (MAS) to achieve high-quality surface representation of large scenes while reducing GPU memory consumption. Extensive experiments on Urban3d, MegaNeRF, and BlendedMVS demonstrate that our proposed method can achieve fast and scalable high-fidelity surface reconstruction and photorealistic rendering. Our project page is available at \url{https://gyy456.github.io/CoSurfGS}.
LLaVA-SLT: Visual Language Tuning for Sign Language Translation
Dec 21, 2024



In the realm of Sign Language Translation (SLT), reliance on costly gloss-annotated datasets has posed a significant barrier. Recent advancements in gloss-free SLT methods have shown promise, yet they often largely lag behind gloss-based approaches in terms of translation accuracy. To narrow this performance gap, we introduce LLaVA-SLT, a pioneering Large Multimodal Model (LMM) framework designed to leverage the power of Large Language Models (LLMs) through effectively learned visual language embeddings. Our model is trained through a trilogy. First, we propose linguistic continued pretraining. We scale up the LLM and adapt it to the sign language domain using an extensive corpus dataset, effectively enhancing its textual linguistic knowledge about sign language. Then, we adopt visual contrastive pretraining to align the visual encoder with a large-scale pretrained text encoder. We propose hierarchical visual encoder that learns a robust word-level intermediate representation that is compatible with LLM token embeddings. Finally, we propose visual language tuning. We freeze pretrained models and employ a lightweight trainable MLP connector. It efficiently maps the pretrained visual language embeddings into the LLM token embedding space, enabling downstream SLT task. Our comprehensive experiments demonstrate that LLaVA-SLT outperforms the state-of-the-art methods. By using extra annotation-free data, it even closes to the gloss-based accuracy.
Splatter-360: Generalizable 360$^{\circ}$ Gaussian Splatting for Wide-baseline Panoramic Images
Dec 09, 2024Wide-baseline panoramic images are frequently used in applications like VR and simulations to minimize capturing labor costs and storage needs. However, synthesizing novel views from these panoramic images in real time remains a significant challenge, especially due to panoramic imagery's high resolution and inherent distortions. Although existing 3D Gaussian splatting (3DGS) methods can produce photo-realistic views under narrow baselines, they often overfit the training views when dealing with wide-baseline panoramic images due to the difficulty in learning precise geometry from sparse 360$^{\circ}$ views. This paper presents \textit{Splatter-360}, a novel end-to-end generalizable 3DGS framework designed to handle wide-baseline panoramic images. Unlike previous approaches, \textit{Splatter-360} performs multi-view matching directly in the spherical domain by constructing a spherical cost volume through a spherical sweep algorithm, enhancing the network's depth perception and geometry estimation. Additionally, we introduce a 3D-aware bi-projection encoder to mitigate the distortions inherent in panoramic images and integrate cross-view attention to improve feature interactions across multiple viewpoints. This enables robust 3D-aware feature representations and real-time rendering capabilities. Experimental results on the HM3D~\cite{hm3d} and Replica~\cite{replica} demonstrate that \textit{Splatter-360} significantly outperforms state-of-the-art NeRF and 3DGS methods (e.g., PanoGRF, MVSplat, DepthSplat, and HiSplat) in both synthesis quality and generalization performance for wide-baseline panoramic images. Code and trained models are available at \url{https://3d-aigc.github.io/Splatter-360/}.