 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry-Aware Implicit Memory for Video World Models
Jun 01, 2026Video world models aim to simulate controllable visual environments, but long-horizon rollouts depend on what the model remembers after observations leave its native context window. Explicit memories retain frames or online 3D reconstructions, which can suffer from heuristic retrieval errors, redundant appearance storage, or reconstruction artifacts. Implicit memories compress history into a compact state, but existing designs are not explicitly constrained to encode cross-view scene geometry. We propose GIM-World, a geometry-aware implicit memory framework for video world models. A lightweight transformer encoder compresses variable-length history into fixed-size memory tokens, a camera-queryable geometry head distills 3D scene structure from a frozen foundation model into the memory during training, and an information-guided pruning rule keeps encoding cost bounded as history grows. The geometry teacher is discarded at inference, leaving a lightweight memory module. Experiments on MIND show that GIM-World better preserves long-horizon geometric and visual consistency than both explicit- and implicit-memory baselines.
UniCustom: Unified Visual Conditioning for Multi-Reference Image Generation
May 13, 2026Multi-reference image generation aims to synthesize images from textual instructions while faithfully preserving subject identities from multiple reference images. Existing VLM-enhanced diffusion models commonly rely on decoupled visual conditioning: semantic ViT features are processed by the VLM for instruction understanding, whereas appearance-rich VAE features are injected later into the diffusion backbone. Despite its intuitive design, this separation makes it difficult for the model to associate each semantically grounded subject with visual details from the correct reference image. As a result, the model may recognize which subject is being referred to, but fail to preserve its identity and fine-grained appearance, leading to attribute leakage and cross-reference confusion in complex multi-reference settings. To address this issue, we propose UniCustom, a unified visual conditioning framework that fuses ViT and VAE features before VLM encoding. This early fusion exposes the VLM to both semantic cues and appearance-rich details, enabling its hidden states to jointly encode the referred subject and corresponding visual appearance with only a lightweight linear fusion layer. To learn such unified representations, we adopt a two-stage training strategy: reconstruction-oriented pretraining that preserves reference-specific appearance details in the fused hidden states, followed by supervised finetuning on single- and multi-reference generation tasks. We further introduce a slot-wise binding regularization that encourages each image slot to preserve low-level details of its corresponding reference, thereby reducing cross-reference entanglement. Experiments on two multi-reference generation benchmarks demonstrate that UniCustom consistently improves subject consistency, instruction following, and compositional fidelity over strong baselines.
Kling-Omni Technical Report
Dec 18, 2025



We present Kling-Omni, a generalist generative framework designed to synthesize high-fidelity videos directly from multimodal visual language inputs. Adopting an end-to-end perspective, Kling-Omni bridges the functional separation among diverse video generation, editing, and intelligent reasoning tasks, integrating them into a holistic system. Unlike disjointed pipeline approaches, Kling-Omni supports a diverse range of user inputs, including text instructions, reference images, and video contexts, processing them into a unified multimodal representation to deliver cinematic-quality and highly-intelligent video content creation. To support these capabilities, we constructed a comprehensive data system that serves as the foundation for multimodal video creation. The framework is further empowered by efficient large-scale pre-training strategies and infrastructure optimizations for inference. Comprehensive evaluations reveal that Kling-Omni demonstrates exceptional capabilities in in-context generation, reasoning-based editing, and multimodal instruction following. Moving beyond a content creation tool, we believe Kling-Omni is a pivotal advancement toward multimodal world simulators capable of perceiving, reasoning, generating and interacting with the dynamic and complex worlds.
FullDiT2: Efficient In-Context Conditioning for Video Diffusion Transformers
Jun 05, 2025


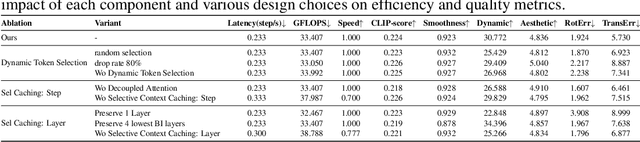
Fine-grained and efficient controllability on video diffusion transformers has raised increasing desires for the applicability. Recently, In-context Conditioning emerged as a powerful paradigm for unified conditional video generation, which enables diverse controls by concatenating varying context conditioning signals with noisy video latents into a long unified token sequence and jointly processing them via full-attention, e.g., FullDiT. Despite their effectiveness, these methods face quadratic computation overhead as task complexity increases, hindering practical deployment. In this paper, we study the efficiency bottleneck neglected in original in-context conditioning video generation framework. We begin with systematic analysis to identify two key sources of the computation inefficiencies: the inherent redundancy within context condition tokens and the computational redundancy in context-latent interactions throughout the diffusion process. Based on these insights, we propose FullDiT2, an efficient in-context conditioning framework for general controllability in both video generation and editing tasks, which innovates from two key perspectives. Firstly, to address the token redundancy, FullDiT2 leverages a dynamic token selection mechanism to adaptively identify important context tokens, reducing the sequence length for unified full-attention. Additionally, a selective context caching mechanism is devised to minimize redundant interactions between condition tokens and video latents. Extensive experiments on six diverse conditional video editing and generation tasks demonstrate that FullDiT2 achieves significant computation reduction and 2-3 times speedup in averaged time cost per diffusion step, with minimal degradation or even higher performance in video generation quality. The project page is at \href{https://fulldit2.github.io/}{https://fulldit2.github.io/}.
UNIC: Unified In-Context Video Editing
Jun 04, 2025

Recent advances in text-to-video generation have sparked interest in generative video editing tasks. Previous methods often rely on task-specific architectures (e.g., additional adapter modules) or dedicated customizations (e.g., DDIM inversion), which limit the integration of versatile editing conditions and the unification of various editing tasks. In this paper, we introduce UNified In-Context Video Editing (UNIC), a simple yet effective framework that unifies diverse video editing tasks within a single model in an in-context manner. To achieve this unification, we represent the inputs of various video editing tasks as three types of tokens: the source video tokens, the noisy video latent, and the multi-modal conditioning tokens that vary according to the specific editing task. Based on this formulation, our key insight is to integrate these three types into a single consecutive token sequence and jointly model them using the native attention operations of DiT, thereby eliminating the need for task-specific adapter designs. Nevertheless, direct task unification under this framework is challenging, leading to severe token collisions and task confusion due to the varying video lengths and diverse condition modalities across tasks. To address these, we introduce task-aware RoPE to facilitate consistent temporal positional encoding, and condition bias that enables the model to clearly differentiate different editing tasks. This allows our approach to adaptively perform different video editing tasks by referring the source video and varying condition tokens "in context", and support flexible task composition. To validate our method, we construct a unified video editing benchmark containing six representative video editing tasks. Results demonstrate that our unified approach achieves superior performance on each task and exhibits emergent task composition abilities.
Ultrasound-Guided Robotic Blood Drawing and In Vivo Studies on Submillimetre Vessels of Rats
Apr 04, 2025Billions of vascular access procedures are performed annually worldwide, serving as a crucial first step in various clinical diagnostic and therapeutic procedures. For pediatric or elderly individuals, whose vessels are small in size (typically 2 to 3 mm in diameter for adults and less than 1 mm in children), vascular access can be highly challenging. This study presents an image-guided robotic system aimed at enhancing the accuracy of difficult vascular access procedures. The system integrates a 6-DoF robotic arm with a 3-DoF end-effector, ensuring precise navigation and needle insertion. Multi-modal imaging and sensing technologies have been utilized to endow the medical robot with precision and safety, while ultrasound imaging guidance is specifically evaluated in this study. To evaluate in vivo vascular access in submillimeter vessels, we conducted ultrasound-guided robotic blood drawing on the tail veins (with a diameter of 0.7 plus or minus 0.2 mm) of 40 rats. The results demonstrate that the system achieved a first-attempt success rate of 95 percent. The high first-attempt success rate in intravenous vascular access, even with small blood vessels, demonstrates the system's effectiveness in performing these procedures. This capability reduces the risk of failed attempts, minimizes patient discomfort, and enhances clinical efficiency.
HumanAesExpert: Advancing a Multi-Modality Foundation Model for Human Image Aesthetic Assessment
Mar 31, 2025



Image Aesthetic Assessment (IAA) is a long-standing and challenging research task. However, its subset, Human Image Aesthetic Assessment (HIAA), has been scarcely explored, even though HIAA is widely used in social media, AI workflows, and related domains. To bridge this research gap, our work pioneers a holistic implementation framework tailored for HIAA. Specifically, we introduce HumanBeauty, the first dataset purpose-built for HIAA, which comprises 108k high-quality human images with manual annotations. To achieve comprehensive and fine-grained HIAA, 50K human images are manually collected through a rigorous curation process and annotated leveraging our trailblazing 12-dimensional aesthetic standard, while the remaining 58K with overall aesthetic labels are systematically filtered from public datasets. Based on the HumanBeauty database, we propose HumanAesExpert, a powerful Vision Language Model for aesthetic evaluation of human images. We innovatively design an Expert head to incorporate human knowledge of aesthetic sub-dimensions while jointly utilizing the Language Modeling (LM) and Regression head. This approach empowers our model to achieve superior proficiency in both overall and fine-grained HIAA. Furthermore, we introduce a MetaVoter, which aggregates scores from all three heads, to effectively balance the capabilities of each head, thereby realizing improved assessment precision. Extensive experiments demonstrate that our HumanAesExpert models deliver significantly better performance in HIAA than other state-of-the-art models. Our datasets, models, and codes are publicly released to advance the HIAA community. Project webpage: https://humanaesexpert.github.io/HumanAesExpert/
FullDiT: Multi-Task Video Generative Foundation Model with Full Attention
Mar 25, 2025Current video generative foundation models primarily focus on text-to-video tasks, providing limited control for fine-grained video content creation. Although adapter-based approaches (e.g., ControlNet) enable additional controls with minimal fine-tuning, they encounter challenges when integrating multiple conditions, including: branch conflicts between independently trained adapters, parameter redundancy leading to increased computational cost, and suboptimal performance compared to full fine-tuning. To address these challenges, we introduce FullDiT, a unified foundation model for video generation that seamlessly integrates multiple conditions via unified full-attention mechanisms. By fusing multi-task conditions into a unified sequence representation and leveraging the long-context learning ability of full self-attention to capture condition dynamics, FullDiT reduces parameter overhead, avoids conditions conflict, and shows scalability and emergent ability. We further introduce FullBench for multi-task video generation evaluation. Experiments demonstrate that FullDiT achieves state-of-the-art results, highlighting the efficacy of full-attention in complex multi-task video generation.
Improving Video Generation with Human Feedback
Jan 23, 2025



Video generation has achieved significant advances through rectified flow techniques, but issues like unsmooth motion and misalignment between videos and prompts persist. In this work, we develop a systematic pipeline that harnesses human feedback to mitigate these problems and refine the video generation model. Specifically, we begin by constructing a large-scale human preference dataset focused on modern video generation models, incorporating pairwise annotations across multi-dimensions. We then introduce VideoReward, a multi-dimensional video reward model, and examine how annotations and various design choices impact its rewarding efficacy. From a unified reinforcement learning perspective aimed at maximizing reward with KL regularization, we introduce three alignment algorithms for flow-based models by extending those from diffusion models. These include two training-time strategies: direct preference optimization for flow (Flow-DPO) and reward weighted regression for flow (Flow-RWR), and an inference-time technique, Flow-NRG, which applies reward guidance directly to noisy videos. Experimental results indicate that VideoReward significantly outperforms existing reward models, and Flow-DPO demonstrates superior performance compared to both Flow-RWR and standard supervised fine-tuning methods. Additionally, Flow-NRG lets users assign custom weights to multiple objectives during inference, meeting personalized video quality needs. Project page: https://gongyeliu.github.io/videoalign.
ConceptMaster: Multi-Concept Video Customization on Diffusion Transformer Models Without Test-Time Tuning
Jan 08, 2025



Text-to-video generation has made remarkable advancements through diffusion models. However, Multi-Concept Video Customization (MCVC) remains a significant challenge. We identify two key challenges in this task: 1) the identity decoupling problem, where directly adopting existing customization methods inevitably mix attributes when handling multiple concepts simultaneously, and 2) the scarcity of high-quality video-entity pairs, which is crucial for training such a model that represents and decouples various concepts well. To address these challenges, we introduce ConceptMaster, an innovative framework that effectively tackles the critical issues of identity decoupling while maintaining concept fidelity in customized videos. Specifically, we introduce a novel strategy of learning decoupled multi-concept embeddings that are injected into the diffusion models in a standalone manner, which effectively guarantees the quality of customized videos with multiple identities, even for highly similar visual concepts. To further overcome the scarcity of high-quality MCVC data, we carefully establish a data construction pipeline, which enables systematic collection of precise multi-concept video-entity data across diverse concepts. A comprehensive benchmark is designed to validate the effectiveness of our model from three critical dimensions: concept fidelity, identity decoupling ability, and video generation quality across six different concept composition scenarios. Extensive experiments demonstrate that our ConceptMaster significantly outperforms previous approaches for this task, paving the way for generating personalized and semantically accurate videos across multiple concepts.