 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUNIAA: A Unified Multi-modal Image Aesthetic Assessment Baseline and Benchmark
Apr 15, 2024
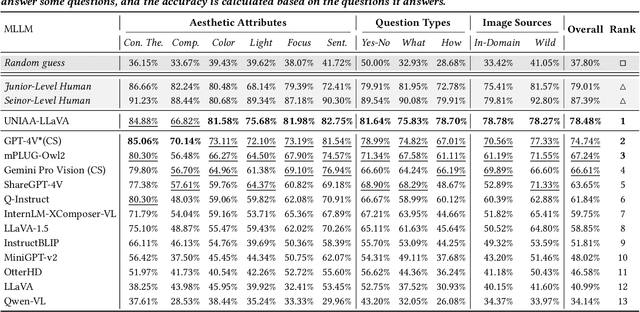
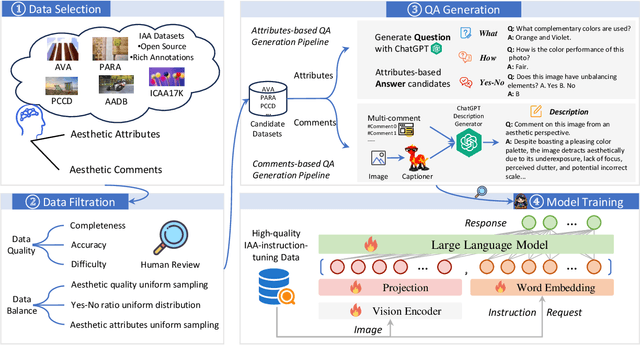
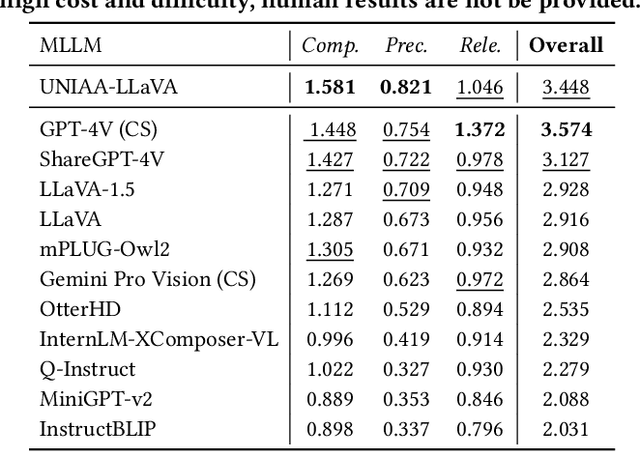
As an alternative to expensive expert evaluation, Image Aesthetic Assessment (IAA) stands out as a crucial task in computer vision. However, traditional IAA methods are typically constrained to a single data source or task, restricting the universality and broader application. In this work, to better align with human aesthetics, we propose a Unified Multi-modal Image Aesthetic Assessment (UNIAA) framework, including a Multi-modal Large Language Model (MLLM) named UNIAA-LLaVA and a comprehensive benchmark named UNIAA-Bench. We choose MLLMs with both visual perception and language ability for IAA and establish a low-cost paradigm for transforming the existing datasets into unified and high-quality visual instruction tuning data, from which the UNIAA-LLaVA is trained. To further evaluate the IAA capability of MLLMs, we construct the UNIAA-Bench, which consists of three aesthetic levels: Perception, Description, and Assessment. Extensive experiments validate the effectiveness and rationality of UNIAA. UNIAA-LLaVA achieves competitive performance on all levels of UNIAA-Bench, compared with existing MLLMs. Specifically, our model performs better than GPT-4V in aesthetic perception and even approaches the junior-level human. We find MLLMs have great potential in IAA, yet there remains plenty of room for further improvement. The UNIAA-LLaVA and UNIAA-Bench will be released.
RGCNN: Regularized Graph CNN for Point Cloud Segmentation
Jun 08, 2018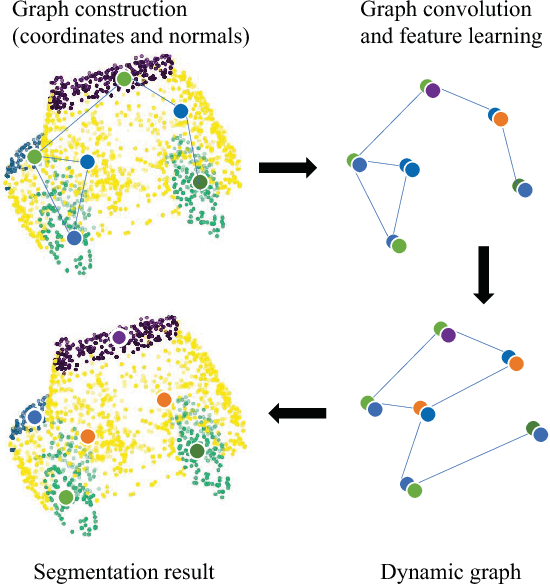

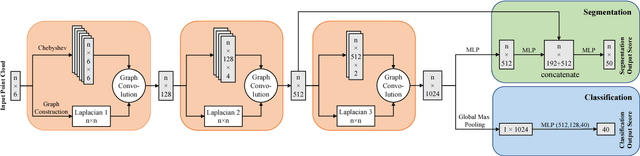
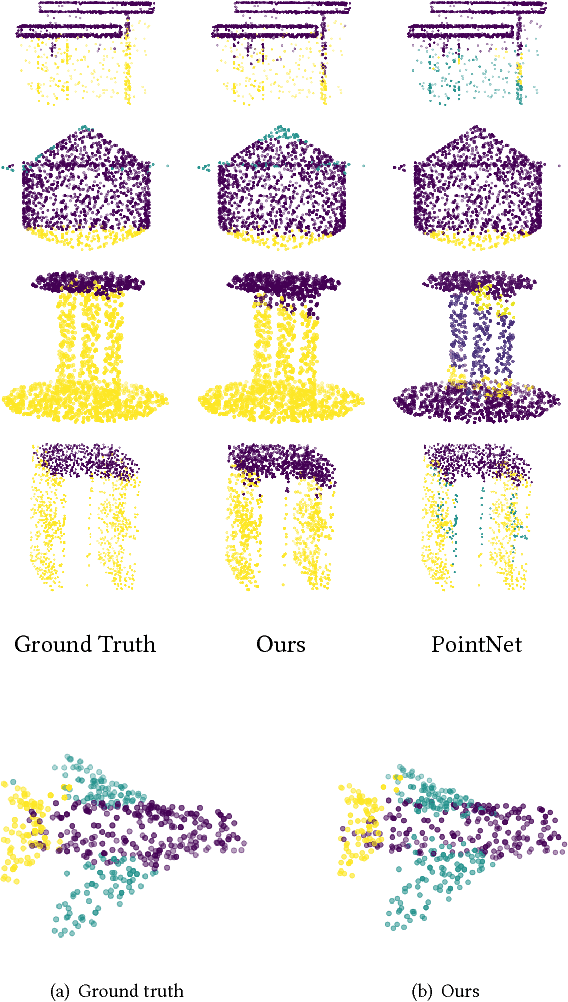
Point cloud, an efficient 3D object representation, has become popular with the development of depth sensing and 3D laser scanning techniques. It has attracted attention in various applications such as 3D tele-presence, navigation for unmanned vehicles and heritage reconstruction. The understanding of point clouds, such as point cloud segmentation, is crucial in exploiting the informative value of point clouds for such applications. Due to the irregularity of the data format, previous deep learning works often convert point clouds to regular 3D voxel grids or collections of images before feeding them into neural networks, which leads to voluminous data and quantization artifacts. In this paper, we instead propose a regularized graph convolutional neural network (RGCNN) that directly consumes point clouds. Leveraging on spectral graph theory, we treat features of points in a point cloud as signals on graph, and define the convolution over graph by Chebyshev polynomial approximation. In particular, we update the graph Laplacian matrix that describes the connectivity of features in each layer according to the corresponding learned features, which adaptively captures the structure of dynamic graphs. Further, we deploy a graph-signal smoothness prior in the loss function, thus regularizing the learning process. Experimental results on the ShapeNet part dataset show that the proposed approach significantly reduces the computational complexity while achieving competitive performance with the state of the art. Also, experiments show RGCNN is much more robust to both noise and point cloud density in comparison with other methods. We further apply RGCNN to point cloud classification and achieve competitive results on ModelNet40 dataset.
Joint Denoising / Compression of Image Contours via Shape Prior and Context Tree
Apr 30, 2017
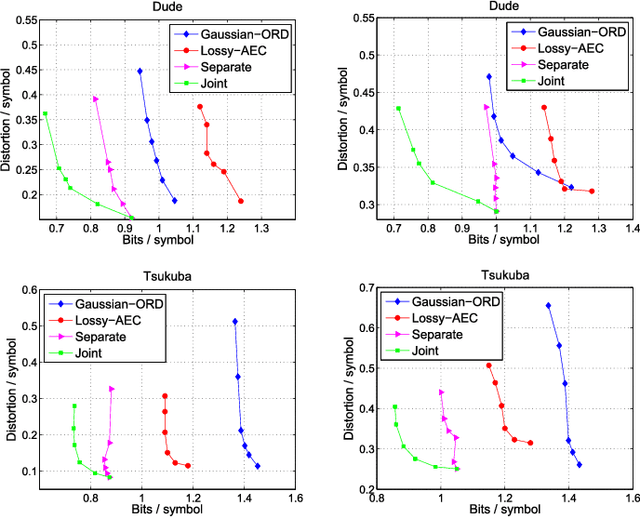
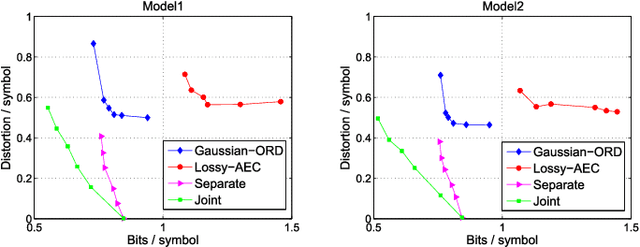
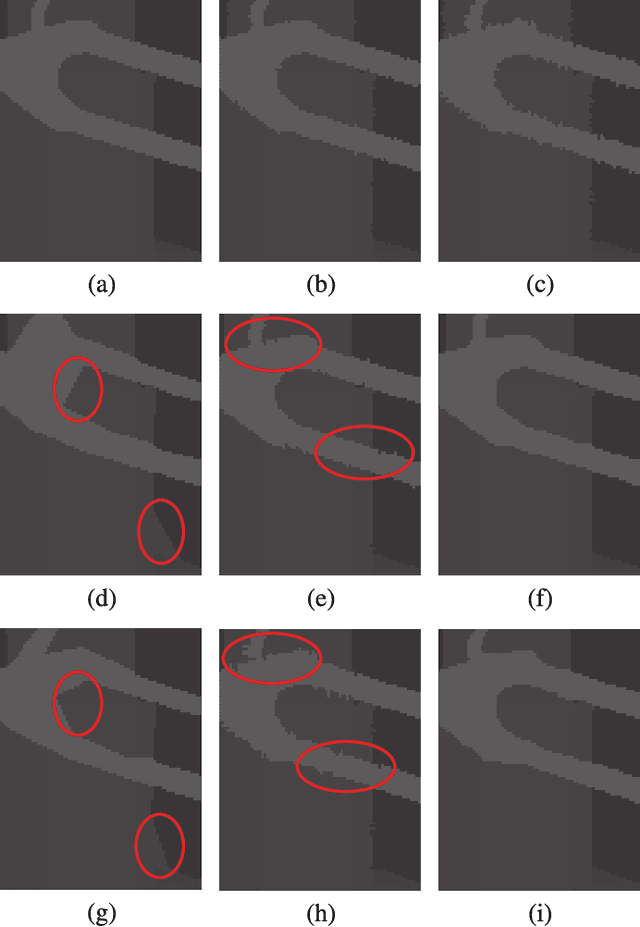
With the advent of depth sensing technologies, the extraction of object contours in images---a common and important pre-processing step for later higher-level computer vision tasks like object detection and human action recognition---has become easier. However, acquisition noise in captured depth images means that detected contours suffer from unavoidable errors. In this paper, we propose to jointly denoise and compress detected contours in an image for bandwidth-constrained transmission to a client, who can then carry out aforementioned application-specific tasks using the decoded contours as input. We first prove theoretically that in general a joint denoising / compression approach can outperform a separate two-stage approach that first denoises then encodes contours lossily. Adopting a joint approach, we first propose a burst error model that models typical errors encountered in an observed string y of directional edges. We then formulate a rate-constrained maximum a posteriori (MAP) problem that trades off the posterior probability p(x'|y) of an estimated string x' given y with its code rate R(x'). We design a dynamic programming (DP) algorithm that solves the posed problem optimally, and propose a compact context representation called total suffix tree (TST) that can reduce complexity of the algorithm dramatically. Experimental results show that our joint denoising / compression scheme outperformed a competing separate scheme in rate-distortion performance noticeably.