 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUNIAA: A Unified Multi-modal Image Aesthetic Assessment Baseline and Benchmark
Paper and Code
Apr 15, 2024
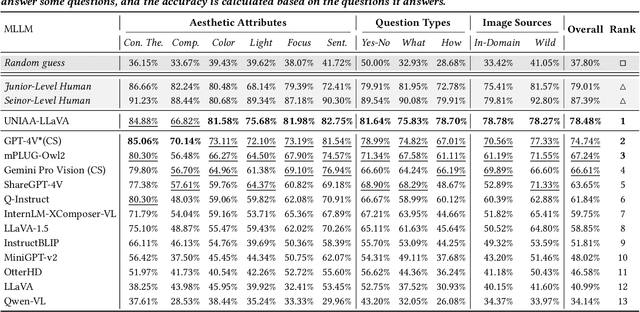
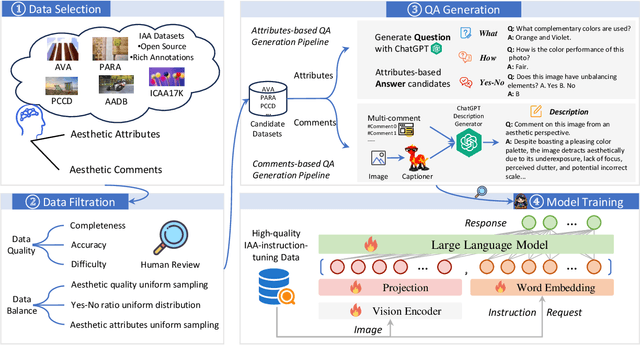
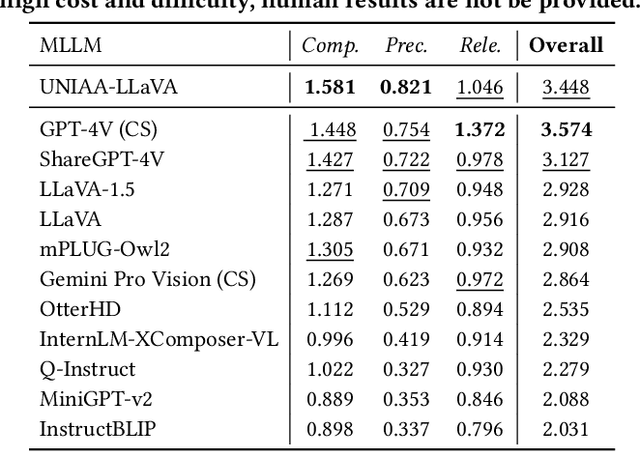
As an alternative to expensive expert evaluation, Image Aesthetic Assessment (IAA) stands out as a crucial task in computer vision. However, traditional IAA methods are typically constrained to a single data source or task, restricting the universality and broader application. In this work, to better align with human aesthetics, we propose a Unified Multi-modal Image Aesthetic Assessment (UNIAA) framework, including a Multi-modal Large Language Model (MLLM) named UNIAA-LLaVA and a comprehensive benchmark named UNIAA-Bench. We choose MLLMs with both visual perception and language ability for IAA and establish a low-cost paradigm for transforming the existing datasets into unified and high-quality visual instruction tuning data, from which the UNIAA-LLaVA is trained. To further evaluate the IAA capability of MLLMs, we construct the UNIAA-Bench, which consists of three aesthetic levels: Perception, Description, and Assessment. Extensive experiments validate the effectiveness and rationality of UNIAA. UNIAA-LLaVA achieves competitive performance on all levels of UNIAA-Bench, compared with existing MLLMs. Specifically, our model performs better than GPT-4V in aesthetic perception and even approaches the junior-level human. We find MLLMs have great potential in IAA, yet there remains plenty of room for further improvement. The UNIAA-LLaVA and UNIAA-Bench will be released.