 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Capture of Animatable 3D Human from Monocular Video
Aug 18, 2022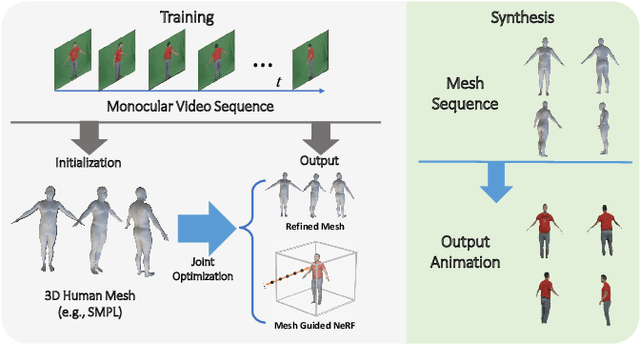
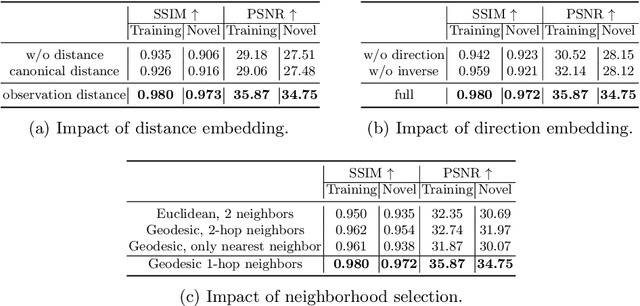
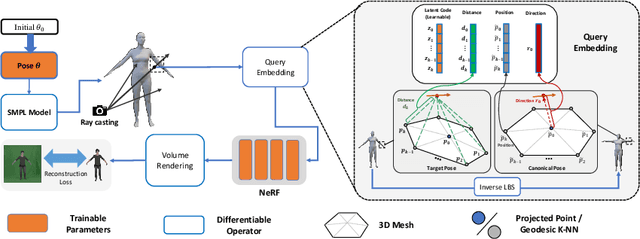
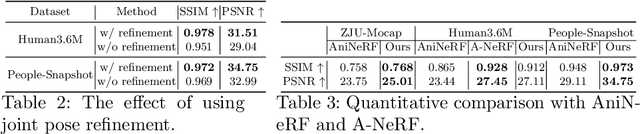
We present a novel paradigm of building an animatable 3D human representation from a monocular video input, such that it can be rendered in any unseen poses and views. Our method is based on a dynamic Neural Radiance Field (NeRF) rigged by a mesh-based parametric 3D human model serving as a geometry proxy. Previous methods usually rely on multi-view videos or accurate 3D geometry information as additional inputs; besides, most methods suffer from degraded quality when generalized to unseen poses. We identify that the key to generalization is a good input embedding for querying dynamic NeRF: A good input embedding should define an injective mapping in the full volumetric space, guided by surface mesh deformation under pose variation. Based on this observation, we propose to embed the input query with its relationship to local surface regions spanned by a set of geodesic nearest neighbors on mesh vertices. By including both position and relative distance information, our embedding defines a distance-preserved deformation mapping and generalizes well to unseen poses. To reduce the dependency on additional inputs, we first initialize per-frame 3D meshes using off-the-shelf tools and then propose a pipeline to jointly optimize NeRF and refine the initial mesh. Extensive experiments show our method can synthesize plausible human rendering results under unseen poses and views.
Adaptive Graph Representation Learning and Reasoning for Face Parsing
Jan 18, 2021
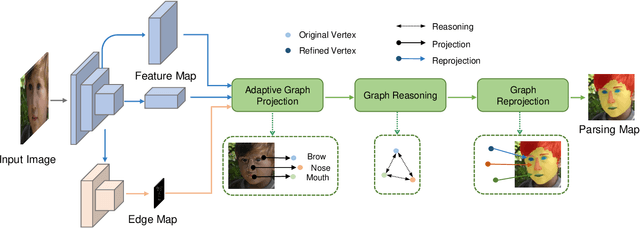

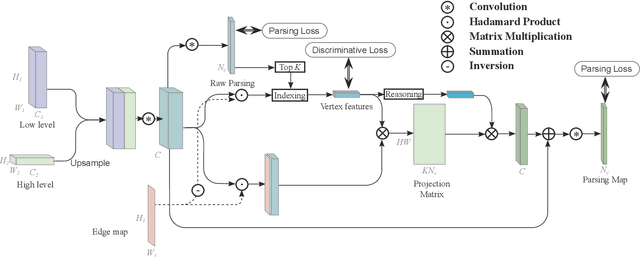
Face parsing infers a pixel-wise label to each facial component, which has drawn much attention recently. Previous methods have shown their success in face parsing, which however overlook the correlation among facial components. As a matter of fact, the component-wise relationship is a critical clue in discriminating ambiguous pixels in facial area. To address this issue, we propose adaptive graph representation learning and reasoning over facial components, aiming to learn representative vertices that describe each component, exploit the component-wise relationship and thereby produce accurate parsing results against ambiguity. In particular, we devise an adaptive and differentiable graph abstraction method to represent the components on a graph via pixel-to-vertex projection under the initial condition of a predicted parsing map, where pixel features within a certain facial region are aggregated onto a vertex. Further, we explicitly incorporate the image edge as a prior in the model, which helps to discriminate edge and non-edge pixels during the projection, thus leading to refined parsing results along the edges. Then, our model learns and reasons over the relations among components by propagating information across vertices on the graph. Finally, the refined vertex features are projected back to pixel grids for the prediction of the final parsing map. To train our model, we propose a discriminative loss to penalize small distances between vertices in the feature space, which leads to distinct vertices with strong semantics. Experimental results show the superior performance of the proposed model on multiple face parsing datasets, along with the validation on the human parsing task to demonstrate the generalizability of our model.
Edge-aware Graph Representation Learning and Reasoning for Face Parsing
Jul 22, 2020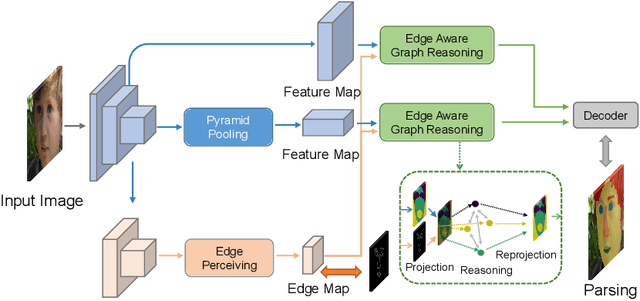
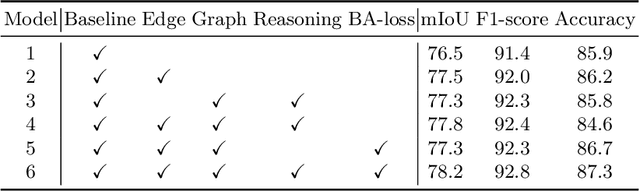


Face parsing infers a pixel-wise label to each facial component, which has drawn much attention recently. Previous methods have shown their efficiency in face parsing, which however overlook the correlation among different face regions. The correlation is a critical clue about the facial appearance, pose, expression etc., and should be taken into account for face parsing. To this end, we propose to model and reason the region-wise relations by learning graph representations, and leverage the edge information between regions for optimized abstraction. Specifically, we encode a facial image onto a global graph representation where a collection of pixels ("regions") with similar features are projected to each vertex. Our model learns and reasons over relations between the regions by propagating information across vertices on the graph. Furthermore, we incorporate the edge information to aggregate the pixel-wise features onto vertices, which emphasizes on the features around edges for fine segmentation along edges. The finally learned graph representation is projected back to pixel grids for parsing. Experiments demonstrate that our model outperforms state-of-the-art methods on the widely used Helen dataset, and also exhibits the superior performance on the large-scale CelebAMask-HQ and LaPa dataset. The code is available at https://github.com/tegusi/EAGRNet.
Exploring Hypergraph Representation on Face Anti-spoofing Beyond 2D Attacks
Dec 13, 2018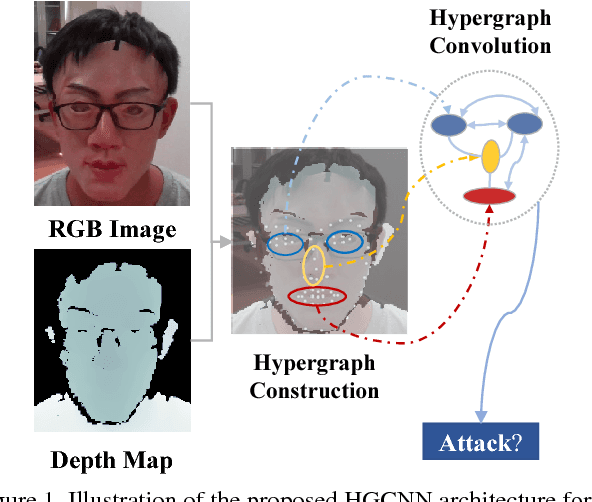

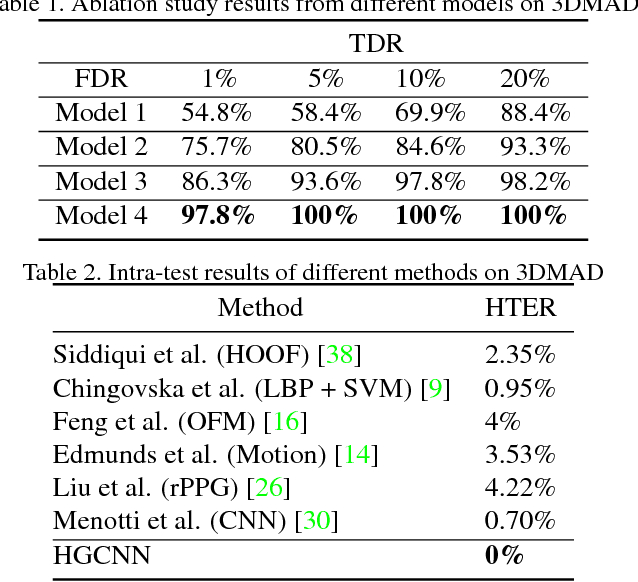
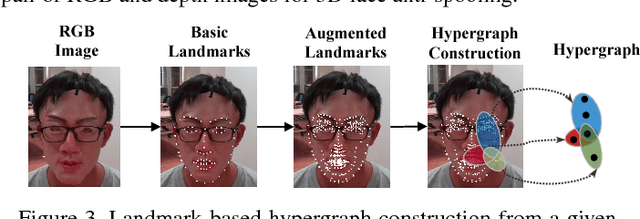
Face anti-spoofing plays a crucial role in protecting face recognition systems from various attacks. Previous model-based and deep learning approaches achieve satisfactory performance for 2D face spoofs, but remain limited for more advanced 3D attacks such as vivid masks. In this paper, we address 3D face anti-spoofing via the proposed Hypergraph Convolutional Neural Networks (HGCNN). Firstly, we construct a computation-efficient and posture-invariant face representation with only a few key points on hypergraphs. The hypergraph representation is then fed into the designed HGCNN with hypergraph convolution for feature extraction, while the depth auxiliary is also exploited for 3D mask anti-spoofing. Further, we build a 3D face attack database with color, depth and infrared light information to overcome the deficiency of 3D face anti-spoofing data. Experiments show that our method achieves the state-of-the-art performance over widely used 3D and 2D databases as well as the proposed one under various tests.
RGCNN: Regularized Graph CNN for Point Cloud Segmentation
Jun 08, 2018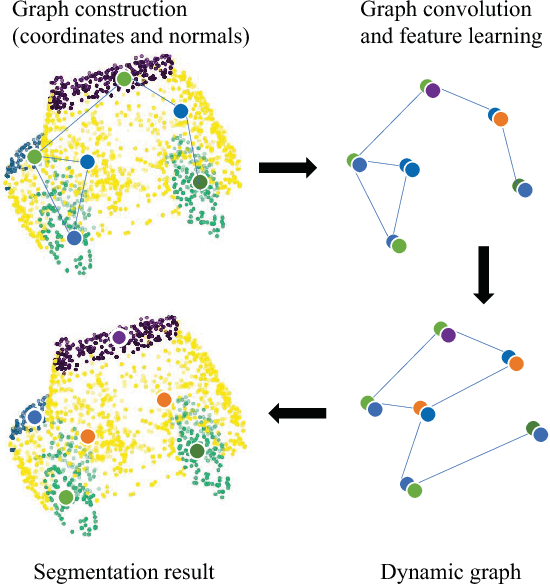

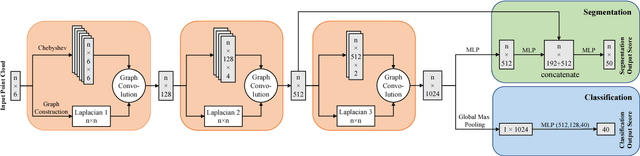
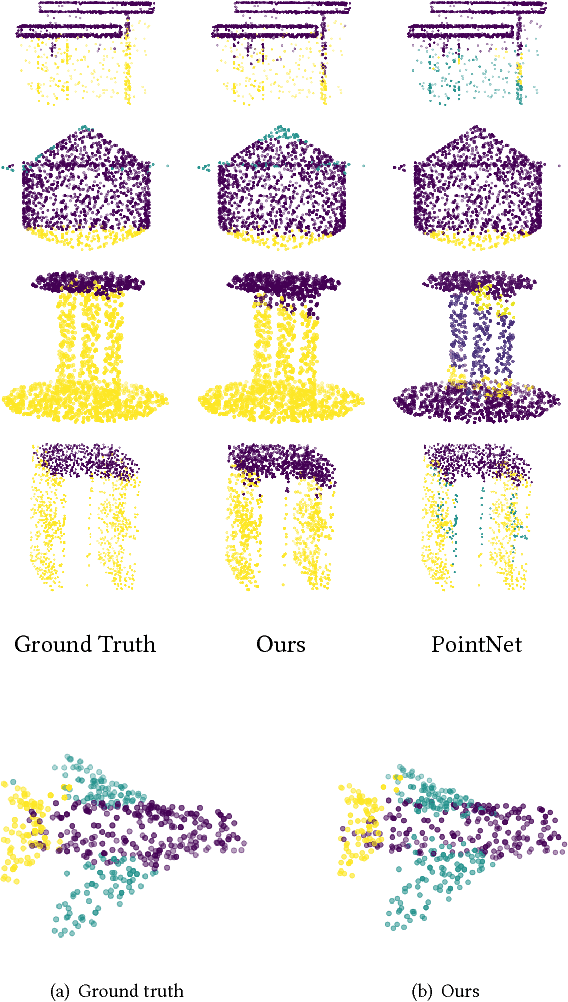
Point cloud, an efficient 3D object representation, has become popular with the development of depth sensing and 3D laser scanning techniques. It has attracted attention in various applications such as 3D tele-presence, navigation for unmanned vehicles and heritage reconstruction. The understanding of point clouds, such as point cloud segmentation, is crucial in exploiting the informative value of point clouds for such applications. Due to the irregularity of the data format, previous deep learning works often convert point clouds to regular 3D voxel grids or collections of images before feeding them into neural networks, which leads to voluminous data and quantization artifacts. In this paper, we instead propose a regularized graph convolutional neural network (RGCNN) that directly consumes point clouds. Leveraging on spectral graph theory, we treat features of points in a point cloud as signals on graph, and define the convolution over graph by Chebyshev polynomial approximation. In particular, we update the graph Laplacian matrix that describes the connectivity of features in each layer according to the corresponding learned features, which adaptively captures the structure of dynamic graphs. Further, we deploy a graph-signal smoothness prior in the loss function, thus regularizing the learning process. Experimental results on the ShapeNet part dataset show that the proposed approach significantly reduces the computational complexity while achieving competitive performance with the state of the art. Also, experiments show RGCNN is much more robust to both noise and point cloud density in comparison with other methods. We further apply RGCNN to point cloud classification and achieve competitive results on ModelNet40 dataset.