 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Graph Representation Learning and Reasoning for Face Parsing
Paper and Code
Jan 18, 2021
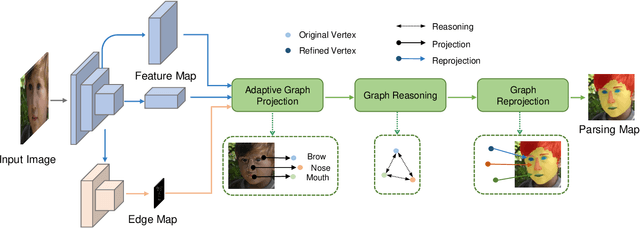

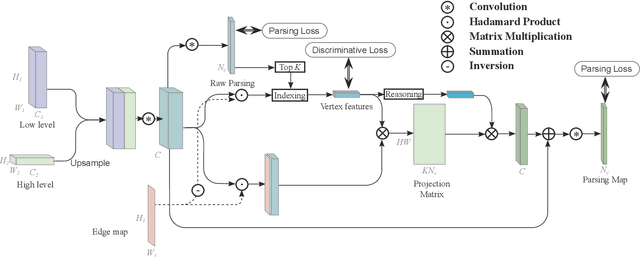
Face parsing infers a pixel-wise label to each facial component, which has drawn much attention recently. Previous methods have shown their success in face parsing, which however overlook the correlation among facial components. As a matter of fact, the component-wise relationship is a critical clue in discriminating ambiguous pixels in facial area. To address this issue, we propose adaptive graph representation learning and reasoning over facial components, aiming to learn representative vertices that describe each component, exploit the component-wise relationship and thereby produce accurate parsing results against ambiguity. In particular, we devise an adaptive and differentiable graph abstraction method to represent the components on a graph via pixel-to-vertex projection under the initial condition of a predicted parsing map, where pixel features within a certain facial region are aggregated onto a vertex. Further, we explicitly incorporate the image edge as a prior in the model, which helps to discriminate edge and non-edge pixels during the projection, thus leading to refined parsing results along the edges. Then, our model learns and reasons over the relations among components by propagating information across vertices on the graph. Finally, the refined vertex features are projected back to pixel grids for the prediction of the final parsing map. To train our model, we propose a discriminative loss to penalize small distances between vertices in the feature space, which leads to distinct vertices with strong semantics. Experimental results show the superior performance of the proposed model on multiple face parsing datasets, along with the validation on the human parsing task to demonstrate the generalizability of our model.