 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransforming Radiance Field with Lipschitz Network for Photorealistic 3D Scene Stylization
Mar 23, 2023



Recent advances in 3D scene representation and novel view synthesis have witnessed the rise of Neural Radiance Fields (NeRFs). Nevertheless, it is not trivial to exploit NeRF for the photorealistic 3D scene stylization task, which aims to generate visually consistent and photorealistic stylized scenes from novel views. Simply coupling NeRF with photorealistic style transfer (PST) will result in cross-view inconsistency and degradation of stylized view syntheses. Through a thorough analysis, we demonstrate that this non-trivial task can be simplified in a new light: When transforming the appearance representation of a pre-trained NeRF with Lipschitz mapping, the consistency and photorealism across source views will be seamlessly encoded into the syntheses. That motivates us to build a concise and flexible learning framework namely LipRF, which upgrades arbitrary 2D PST methods with Lipschitz mapping tailored for the 3D scene. Technically, LipRF first pre-trains a radiance field to reconstruct the 3D scene, and then emulates the style on each view by 2D PST as the prior to learn a Lipschitz network to stylize the pre-trained appearance. In view of that Lipschitz condition highly impacts the expressivity of the neural network, we devise an adaptive regularization to balance the reconstruction and stylization. A gradual gradient aggregation strategy is further introduced to optimize LipRF in a cost-efficient manner. We conduct extensive experiments to show the high quality and robust performance of LipRF on both photorealistic 3D stylization and object appearance editing.
Generalized One-shot Domain Adaption of Generative Adversarial Networks
Sep 08, 2022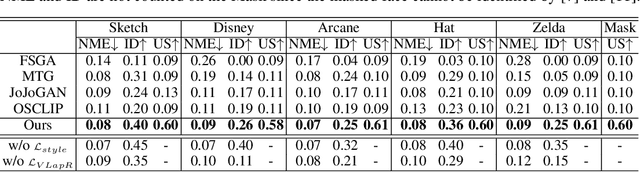
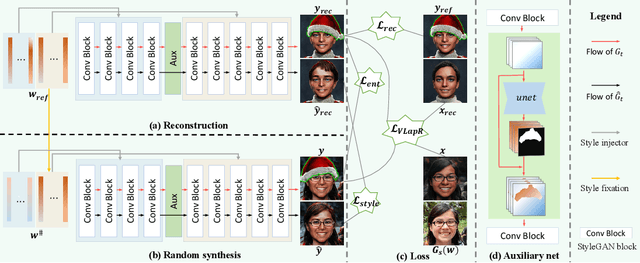

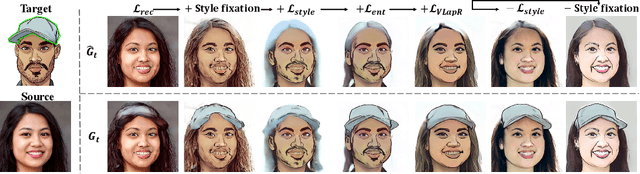
The adaption of Generative Adversarial Network (GAN) aims to transfer a pre-trained GAN to a given domain with limited training data. In this paper, we focus on the one-shot case, which is more challenging and rarely explored in previous works. We consider that the adaptation from source domain to target domain can be decoupled into two parts: the transfer of global style like texture and color, and the emergence of new entities that do not belong to the source domain. While previous works mainly focus on the style transfer, we propose a novel and concise framework\footnote{\url{https://github.com/thevoidname/Generalized-One-shot-GAN-Adaption}} to address the \textit{generalized one-shot adaption} task for both style and entity transfer, in which a reference image and its binary entity mask are provided. Our core objective is to constrain the gap between the internal distributions of the reference and syntheses by sliced Wasserstein distance. To better achieve it, style fixation is used at first to roughly obtain the exemplary style, and an auxiliary network is introduced to the original generator to disentangle entity and style transfer. Besides, to realize cross-domain correspondence, we propose the variational Laplacian regularization to constrain the smoothness of the adapted generator. Both quantitative and qualitative experiments demonstrate the effectiveness of our method in various scenarios.
PetsGAN: Rethinking Priors for Single Image Generation
Mar 03, 2022
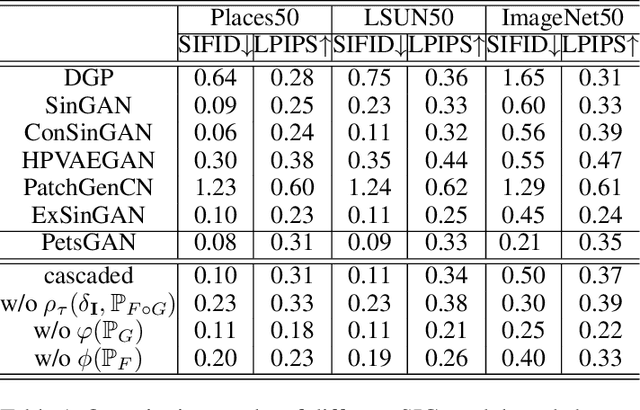

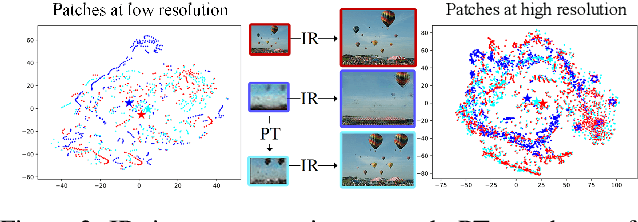
Single image generation (SIG), described as generating diverse samples that have similar visual content with the given single image, is first introduced by SinGAN which builds a pyramid of GANs to progressively learn the internal patch distribution of the single image. It also shows great potentials in a wide range of image manipulation tasks. However, the paradigm of SinGAN has limitations in terms of generation quality and training time. Firstly, due to the lack of high-level information, SinGAN cannot handle the object images well as it does on the scene and texture images. Secondly, the separate progressive training scheme is time-consuming and easy to cause artifact accumulation. To tackle these problems, in this paper, we dig into the SIG problem and improve SinGAN by fully-utilization of internal and external priors. The main contributions of this paper include: 1) We introduce to SIG a regularized latent variable model. To the best of our knowledge, it is the first time to give a clear formulation and optimization goal of SIG, and all the existing methods for SIG can be regarded as special cases of this model. 2) We design a novel Prior-based end-to-end training GAN (PetsGAN) to overcome the problems of SinGAN. Our method gets rid of the time-consuming progressive training scheme and can be trained end-to-end. 3) We construct abundant qualitative and quantitative experiments to show the superiority of our method on both generated image quality, diversity, and the training speed. Moreover, we apply our method to other image manipulation tasks (e.g., style transfer, harmonization), and the results further prove the effectiveness and efficiency of our method.
FasterPose: A Faster Simple Baseline for Human Pose Estimation
Jul 07, 2021
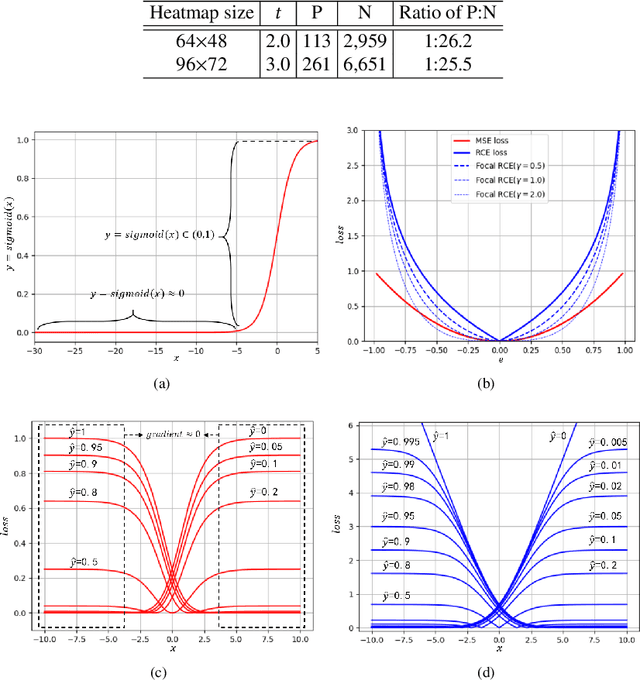
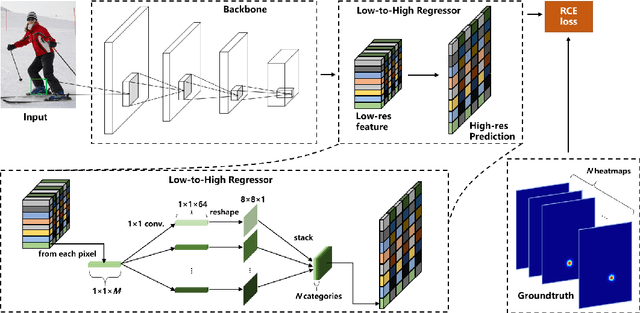

The performance of human pose estimation depends on the spatial accuracy of keypoint localization. Most existing methods pursue the spatial accuracy through learning the high-resolution (HR) representation from input images. By the experimental analysis, we find that the HR representation leads to a sharp increase of computational cost, while the accuracy improvement remains marginal compared with the low-resolution (LR) representation. In this paper, we propose a design paradigm for cost-effective network with LR representation for efficient pose estimation, named FasterPose. Whereas the LR design largely shrinks the model complexity, yet how to effectively train the network with respect to the spatial accuracy is a concomitant challenge. We study the training behavior of FasterPose, and formulate a novel regressive cross-entropy (RCE) loss function for accelerating the convergence and promoting the accuracy. The RCE loss generalizes the ordinary cross-entropy loss from the binary supervision to a continuous range, thus the training of pose estimation network is able to benefit from the sigmoid function. By doing so, the output heatmap can be inferred from the LR features without loss of spatial accuracy, while the computational cost and model size has been significantly reduced. Compared with the previously dominant network of pose estimation, our method reduces 58% of the FLOPs and simultaneously gains 1.3% improvement of accuracy. Extensive experiments show that FasterPose yields promising results on the common benchmarks, i.e., COCO and MPII, consistently validating the effectiveness and efficiency for practical utilization, especially the low-latency and low-energy-budget applications in the non-GPU scenarios.
Towards NIR-VIS Masked Face Recognition
Apr 14, 2021
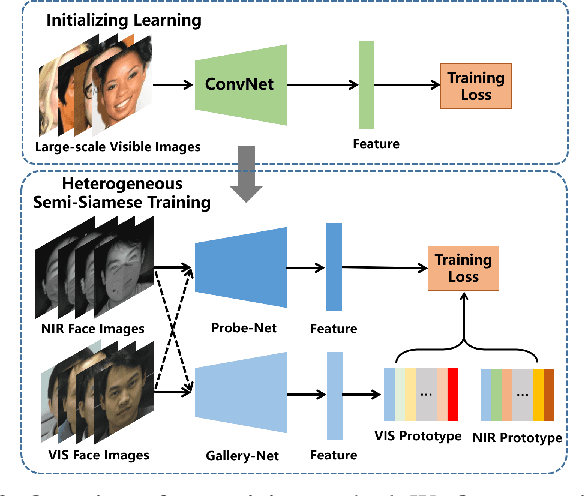
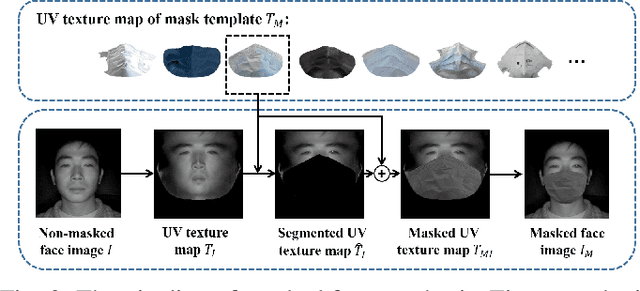
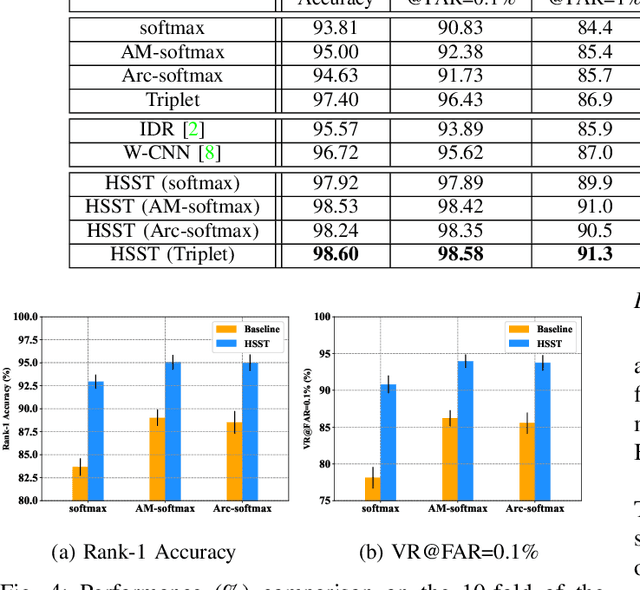
Near-infrared to visible (NIR-VIS) face recognition is the most common case in heterogeneous face recognition, which aims to match a pair of face images captured from two different modalities. Existing deep learning based methods have made remarkable progress in NIR-VIS face recognition, while it encounters certain newly-emerged difficulties during the pandemic of COVID-19, since people are supposed to wear facial masks to cut off the spread of the virus. We define this task as NIR-VIS masked face recognition, and find it problematic with the masked face in the NIR probe image. First, the lack of masked face data is a challenging issue for the network training. Second, most of the facial parts (cheeks, mouth, nose etc.) are fully occluded by the mask, which leads to a large amount of loss of information. Third, the domain gap still exists in the remaining facial parts. In such scenario, the existing methods suffer from significant performance degradation caused by the above issues. In this paper, we aim to address the challenge of NIR-VIS masked face recognition from the perspectives of training data and training method. Specifically, we propose a novel heterogeneous training method to maximize the mutual information shared by the face representation of two domains with the help of semi-siamese networks. In addition, a 3D face reconstruction based approach is employed to synthesize masked face from the existing NIR image. Resorting to these practices, our solution provides the domain-invariant face representation which is also robust to the mask occlusion. Extensive experiments on three NIR-VIS face datasets demonstrate the effectiveness and cross-dataset-generalization capacity of our method.
Adaptive Graph Representation Learning and Reasoning for Face Parsing
Jan 18, 2021
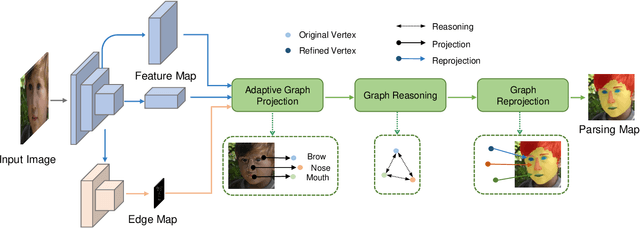

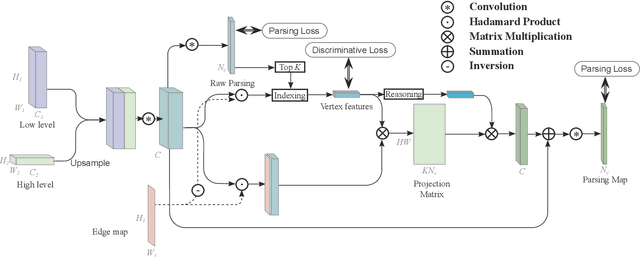
Face parsing infers a pixel-wise label to each facial component, which has drawn much attention recently. Previous methods have shown their success in face parsing, which however overlook the correlation among facial components. As a matter of fact, the component-wise relationship is a critical clue in discriminating ambiguous pixels in facial area. To address this issue, we propose adaptive graph representation learning and reasoning over facial components, aiming to learn representative vertices that describe each component, exploit the component-wise relationship and thereby produce accurate parsing results against ambiguity. In particular, we devise an adaptive and differentiable graph abstraction method to represent the components on a graph via pixel-to-vertex projection under the initial condition of a predicted parsing map, where pixel features within a certain facial region are aggregated onto a vertex. Further, we explicitly incorporate the image edge as a prior in the model, which helps to discriminate edge and non-edge pixels during the projection, thus leading to refined parsing results along the edges. Then, our model learns and reasons over the relations among components by propagating information across vertices on the graph. Finally, the refined vertex features are projected back to pixel grids for the prediction of the final parsing map. To train our model, we propose a discriminative loss to penalize small distances between vertices in the feature space, which leads to distinct vertices with strong semantics. Experimental results show the superior performance of the proposed model on multiple face parsing datasets, along with the validation on the human parsing task to demonstrate the generalizability of our model.
FaceX-Zoo: A PyTorch Toolbox for Face Recognition
Jan 13, 2021
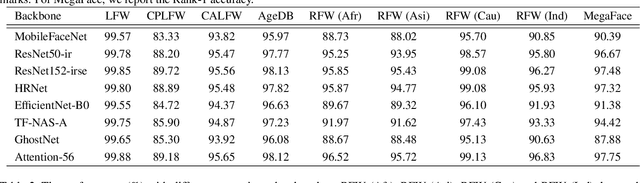
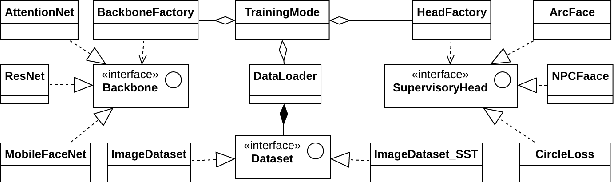
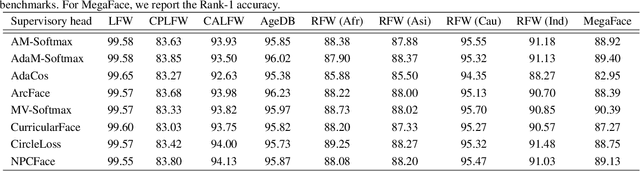
Deep learning based face recognition has achieved significant progress in recent years. Yet, the practical model production and further research of deep face recognition are in great need of corresponding public support. For example, the production of face representation network desires a modular training scheme to consider the proper choice from various candidates of state-of-the-art backbone and training supervision subject to the real-world face recognition demand; for performance analysis and comparison, the standard and automatic evaluation with a bunch of models on multiple benchmarks will be a desired tool as well; besides, a public groundwork is welcomed for deploying the face recognition in the shape of holistic pipeline. Furthermore, there are some newly-emerged challenges, such as the masked face recognition caused by the recent world-wide COVID-19 pandemic, which draws increasing attention in practical applications. A feasible and elegant solution is to build an easy-to-use unified framework to meet the above demands. To this end, we introduce a novel open-source framework, named FaceX-Zoo, which is oriented to the research-development community of face recognition. Resorting to the highly modular and scalable design, FaceX-Zoo provides a training module with various supervisory heads and backbones towards state-of-the-art face recognition, as well as a standardized evaluation module which enables to evaluate the models in most of the popular benchmarks just by editing a simple configuration. Also, a simple yet fully functional face SDK is provided for the validation and primary application of the trained models. Rather than including as many as possible of the prior techniques, we enable FaceX-Zoo to easily upgrade and extend along with the development of face related domains. The source code and models are available at https://github.com/JDAI-CV/FaceX-Zoo.
Edge-aware Graph Representation Learning and Reasoning for Face Parsing
Jul 22, 2020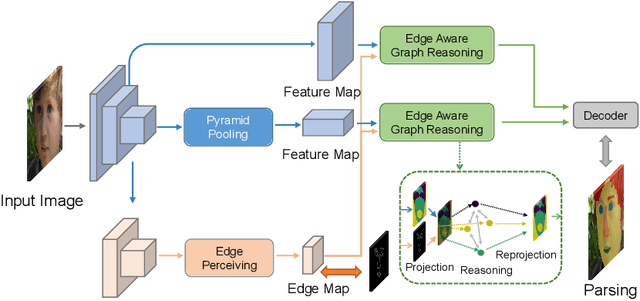
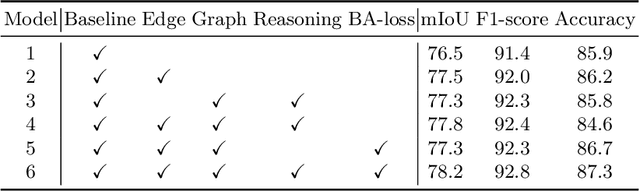


Face parsing infers a pixel-wise label to each facial component, which has drawn much attention recently. Previous methods have shown their efficiency in face parsing, which however overlook the correlation among different face regions. The correlation is a critical clue about the facial appearance, pose, expression etc., and should be taken into account for face parsing. To this end, we propose to model and reason the region-wise relations by learning graph representations, and leverage the edge information between regions for optimized abstraction. Specifically, we encode a facial image onto a global graph representation where a collection of pixels ("regions") with similar features are projected to each vertex. Our model learns and reasons over relations between the regions by propagating information across vertices on the graph. Furthermore, we incorporate the edge information to aggregate the pixel-wise features onto vertices, which emphasizes on the features around edges for fine segmentation along edges. The finally learned graph representation is projected back to pixel grids for parsing. Experiments demonstrate that our model outperforms state-of-the-art methods on the widely used Helen dataset, and also exhibits the superior performance on the large-scale CelebAMask-HQ and LaPa dataset. The code is available at https://github.com/tegusi/EAGRNet.
A High-Efficiency Framework for Constructing Large-Scale Face Parsing Benchmark
May 13, 2019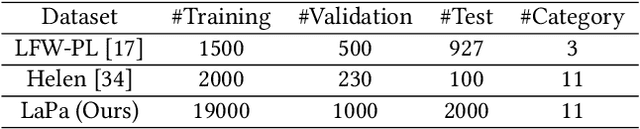



Face parsing, which is to assign a semantic label to each pixel in face images, has recently attracted increasing interest due to its huge application potentials. Although many face related fields (e.g., face recognition and face detection) have been well studied for many years, the existing datasets for face parsing are still severely limited in terms of the scale and quality, e.g., the widely used Helen dataset only contains 2,330 images. This is mainly because pixel-level annotation is a high cost and time-consuming work, especially for the facial parts without clear boundaries. The lack of accurate annotated datasets becomes a major obstacle in the progress of face parsing task. It is a feasible way to utilize dense facial landmarks to guide the parsing annotation. However, annotating dense landmarks on human face encounters the same issues as the parsing annotation. To overcome the above problems, in this paper, we develop a high-efficiency framework for face parsing annotation, which considerably simplifies and speeds up the parsing annotation by two consecutive modules. Benefit from the proposed framework, we construct a new Dense Landmark Guided Face Parsing (LaPa) benchmark. It consists of 22,000 face images with large variations in expression, pose, occlusion, etc. Each image is provided with accurate annotation of a 11-category pixel-level label map along with coordinates of 106-point landmarks. To the best of our knowledge, it is currently the largest public dataset for face parsing. To make full use of our LaPa dataset with abundant face shape and boundary priors, we propose a simple yet effective Boundary-Sensitive Parsing Network (BSPNet). Our network is taken as a baseline model on the proposed LaPa dataset, and meanwhile, it achieves the state-of-the-art performance on the Helen dataset without resorting to extra face alignment.
Grand Challenge of 106-Point Facial Landmark Localization
May 09, 2019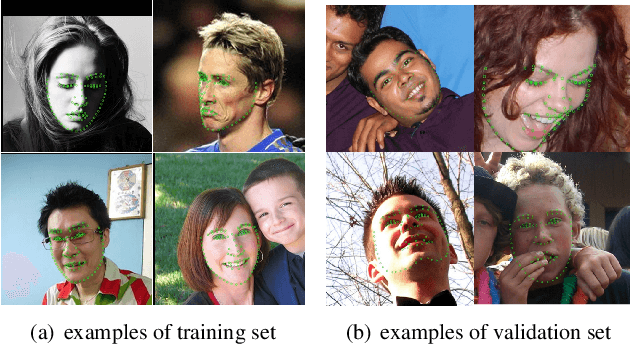
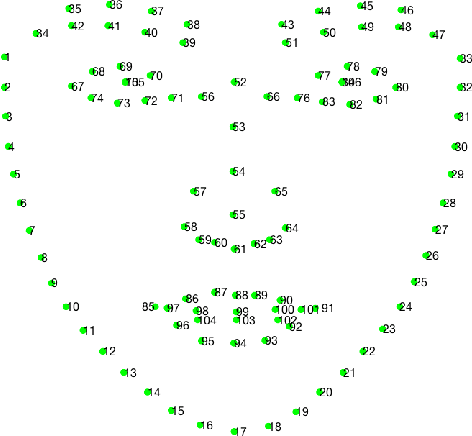

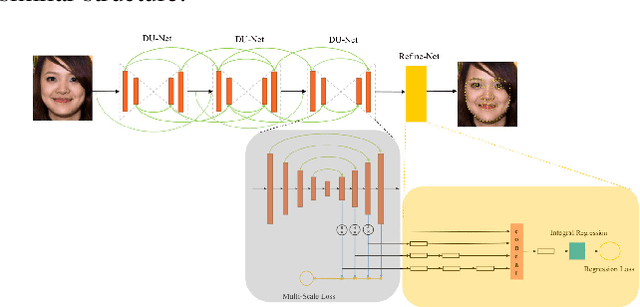
Facial landmark localization is a very crucial step in numerous face related applications, such as face recognition, facial pose estimation, face image synthesis, etc. However, previous competitions on facial landmark localization (i.e., the 300-W, 300-VW and Menpo challenges) aim to predict 68-point landmarks, which are incompetent to depict the structure of facial components. In order to overcome this problem, we construct a challenging dataset, named JD-landmark. Each image is manually annotated with 106-point landmarks. This dataset covers large variations on pose and expression, which brings a lot of difficulties to predict accurate landmarks. We hold a 106-point facial landmark localization competition1 on this dataset in conjunction with IEEE International Conference on Multimedia and Expo (ICME) 2019. The purpose of this competition is to discover effective and robust facial landmark localization approaches.