 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLDPC Decoding with Degree-Specific Neural Message Weights and RCQ Decoding
Oct 24, 2023Recently, neural networks have improved MinSum message-passing decoders for low-density parity-check (LDPC) codes by multiplying or adding weights to the messages, where the weights are determined by a neural network. The neural network complexity to determine distinct weights for each edge is high, often limiting the application to relatively short LDPC codes. Furthermore, storing separate weights for every edge and every iteration can be a burden for hardware implementations. To reduce neural network complexity and storage requirements, this paper proposes a family of weight-sharing schemes that use the same weight for edges that have the same check node degree and/or variable node degree. Our simulation results show that node-degree-based weight-sharing can deliver the same performance requiring distinct weights for each node. This paper also combines these degree-specific neural weights with a reconstruction-computation-quantization (RCQ) decoder to produce a weighted RCQ (W-RCQ) decoder. The W-RCQ decoder with node-degree-based weight sharing has a reduced hardware requirement compared with the original RCQ decoder. As an additional contribution, this paper identifies and resolves a gradient explosion issue that can arise when training neural LDPC decoders.
Reconstruction-Computation-Quantization (RCQ): A Paradigm for Low Bit Width LDPC Decoding
Nov 17, 2021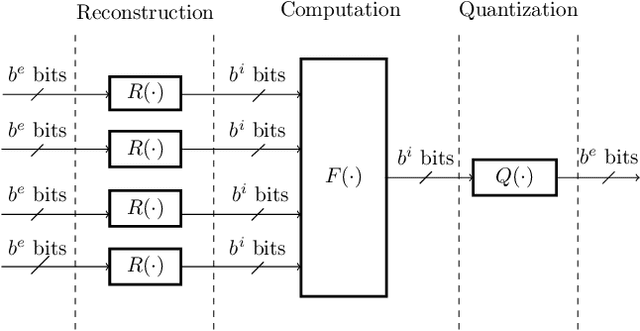
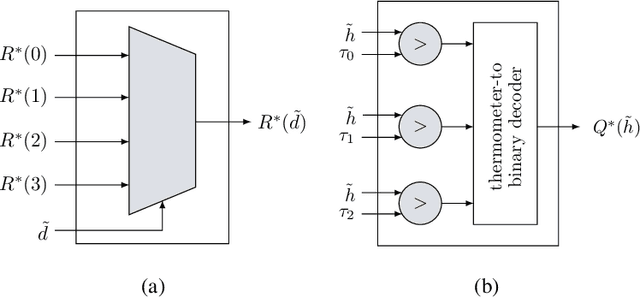
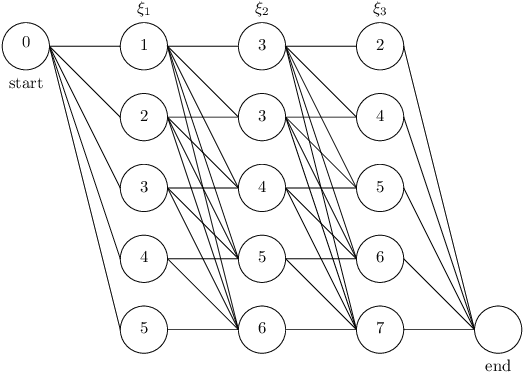
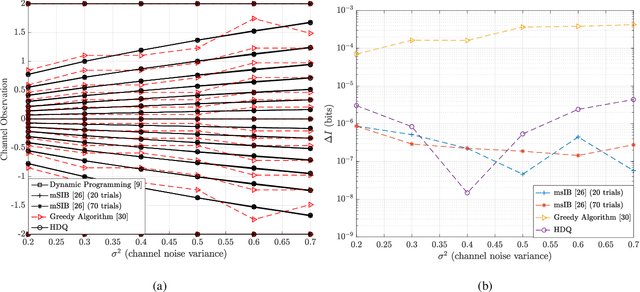
This paper uses the reconstruction-computation-quantization (RCQ) paradigm to decode low-density parity-check (LDPC) codes. RCQ facilitates dynamic non-uniform quantization to achieve good frame error rate (FER) performance with very low message precision. For message-passing according to a flooding schedule, the RCQ parameters are designed by discrete density evolution (DDE). Simulation results on an IEEE 802.11 LDPC code show that for 4-bit messages, a flooding MinSum RCQ decoder outperforms table-lookup approaches such as information bottleneck (IB) or Min-IB decoding, with significantly fewer parameters to be stored. Additionally, this paper introduces layer-specific RCQ (LS-RCQ), an extension of RCQ decoding for layered architectures. LS-RCQ uses layer-specific message representations to achieve the best possible FER performance. For LS-RCQ, this paper proposes using layered DDE featuring hierarchical dynamic quantization (HDQ) to design LS-RCQ parameters efficiently. Finally, this paper studies field-programmable gate array (FPGA) implementations of RCQ decoders. Simulation results for a (9472, 8192) quasi-cyclic (QC) LDPC code show that a layered MinSum RCQ decoder with 3-bit messages achieves more than a $10\%$ reduction in LUTs and routed nets and more than a $6\%$ decrease in register usage while maintaining comparable decoding performance, compared to a 5-bit offset MinSum decoder.
Achieving Short-Blocklength RCU bound via CRC List Decoding of TCM with Probabilistic Shaping
Nov 16, 2021


This paper applies probabilistic amplitude shaping (PAS) to a cyclic redundancy check (CRC) aided trellis coded modulation (TCM) to achieve the short-blocklength random coding union (RCU) bound. In the transmitter, the equally likely message bits are first encoded by distribution matcher to generate amplitude symbols with the desired distribution. The binary representations of the distribution matcher outputs are then encoded by a CRC. Finally, the CRC-encoded bits are encoded and modulated by Ungerboeck's TCM scheme, which consists of a $\frac{k_0}{k_0+1}$ systematic tail-biting convolutional code and a mapping function that maps coded bits to channel signals with capacity-achieving distribution. This paper proves that, for the proposed transmitter, the CRC bits have uniform distribution and that the channel signals have symmetric distribution. In the receiver, the serial list Viterbi decoding (S-LVD) is used to estimate the information bits. Simulation results show that, for the proposed CRC-TCM-PAS system with 87 input bits and 65-67 8-AM coded output symbols, the decoding performance under additive white Gaussian noise channel achieves the RCU bound with properly designed CRC and convolutional codes.
FasterPose: A Faster Simple Baseline for Human Pose Estimation
Jul 07, 2021
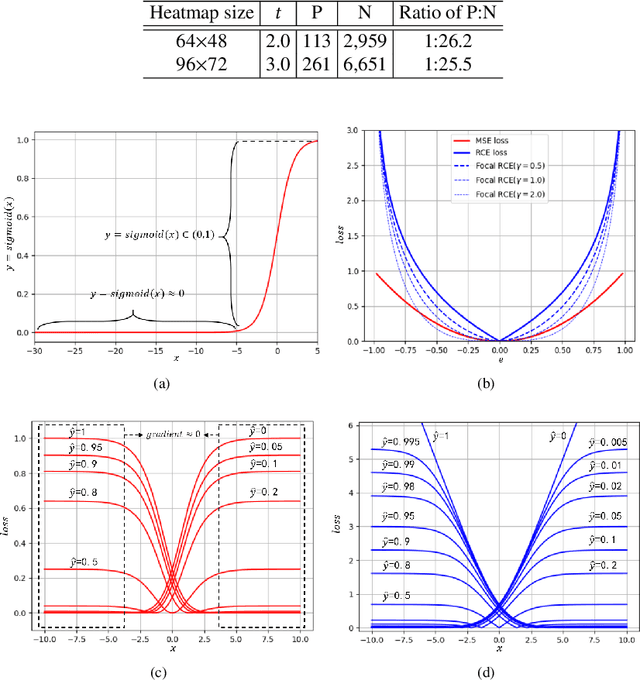
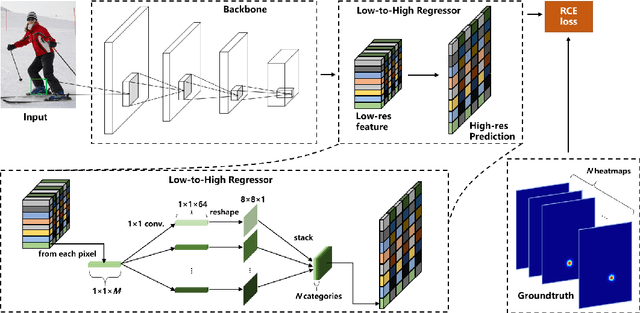

The performance of human pose estimation depends on the spatial accuracy of keypoint localization. Most existing methods pursue the spatial accuracy through learning the high-resolution (HR) representation from input images. By the experimental analysis, we find that the HR representation leads to a sharp increase of computational cost, while the accuracy improvement remains marginal compared with the low-resolution (LR) representation. In this paper, we propose a design paradigm for cost-effective network with LR representation for efficient pose estimation, named FasterPose. Whereas the LR design largely shrinks the model complexity, yet how to effectively train the network with respect to the spatial accuracy is a concomitant challenge. We study the training behavior of FasterPose, and formulate a novel regressive cross-entropy (RCE) loss function for accelerating the convergence and promoting the accuracy. The RCE loss generalizes the ordinary cross-entropy loss from the binary supervision to a continuous range, thus the training of pose estimation network is able to benefit from the sigmoid function. By doing so, the output heatmap can be inferred from the LR features without loss of spatial accuracy, while the computational cost and model size has been significantly reduced. Compared with the previously dominant network of pose estimation, our method reduces 58% of the FLOPs and simultaneously gains 1.3% improvement of accuracy. Extensive experiments show that FasterPose yields promising results on the common benchmarks, i.e., COCO and MPII, consistently validating the effectiveness and efficiency for practical utilization, especially the low-latency and low-energy-budget applications in the non-GPU scenarios.
FPGA Implementations of Layered MinSum LDPC Decoders Using RCQ Message Passing
Apr 19, 2021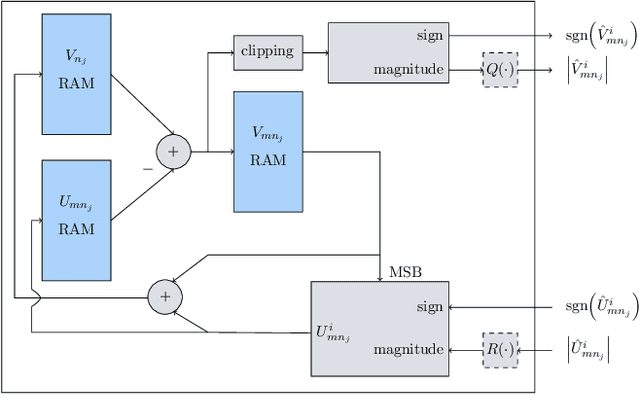
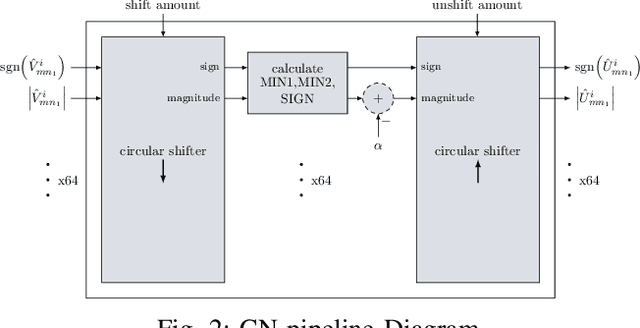
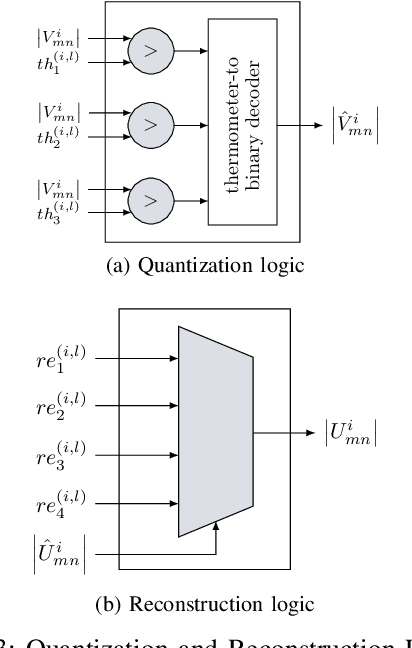
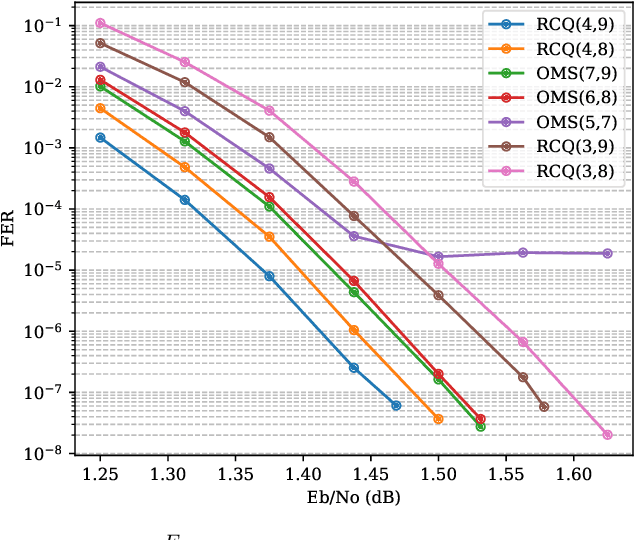
Non-uniform message quantization techniques such as reconstruction-computation-quantization (RCQ) improve error-correction performance and decrease hardware complexity of low-density parity-check (LDPC) decoders that use a flooding schedule. Layered MinSum RCQ (L-msRCQ) enables message quantization to be utilized for layered decoders and irregular LDPC codes. We investigate field-programmable gate array (FPGA) implementations of L-msRCQ decoders. Three design methods for message quantization are presented, which we name the Lookup, Broadcast, and Dribble methods. The decoding performance and hardware complexity of these schemes are compared to a layered offset MinSum (OMS) decoder. Simulation results on a (16384, 8192) protograph-based raptor-like (PBRL) LDPC code show that a 4-bit L-msRCQ decoder using the Broadcast method can achieve a 0.03 dB improvement in error-correction performance while using 12% fewer registers than the OMS decoder. A Broadcast-based 3-bit L-msRCQ decoder uses 15% fewer lookup tables, 18% fewer registers, and 13% fewer routed nets than the OMS decoder, but results in a 0.09 dB loss in performance.
Products-10K: A Large-scale Product Recognition Dataset
Aug 24, 2020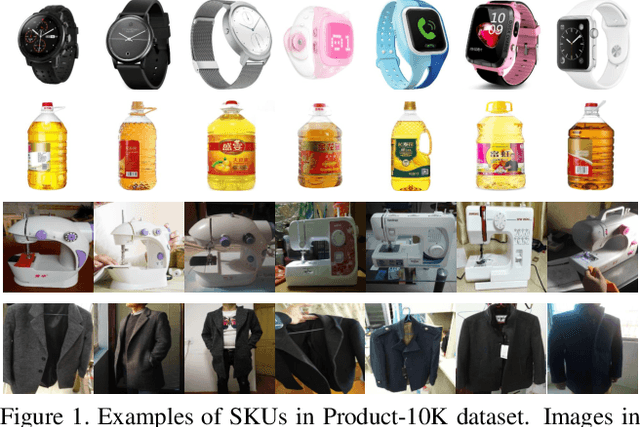


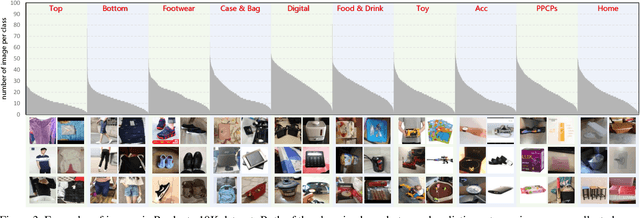
With the rapid development of electronic commerce, the way of shopping has experienced a revolutionary evolution. To fully meet customers' massive and diverse online shopping needs with quick response, the retailing AI system needs to automatically recognize products from images and videos at the stock-keeping unit (SKU) level with high accuracy. However, product recognition is still a challenging task, since many of SKU-level products are fine-grained and visually similar by a rough glimpse. Although there are already some products benchmarks available, these datasets are either too small (limited number of products) or noisy-labeled (lack of human labeling). In this paper, we construct a human-labeled product image dataset named "Products-10K", which contains 10,000 fine-grained SKU-level products frequently bought by online customers in JD.com. Based on our new database, we also introduced several useful tips and tricks for fine-grained product recognition. The products-10K dataset is available via https://products-10k.github.io/.