 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASHA: Assistive Teleoperation via Human-in-the-Loop Reinforcement Learning
Feb 05, 2022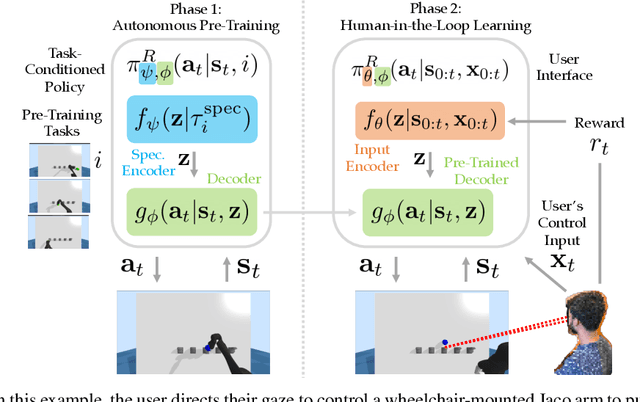
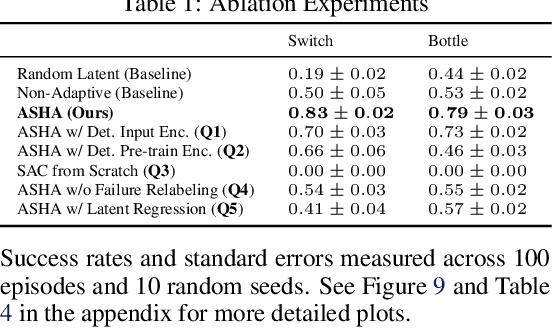
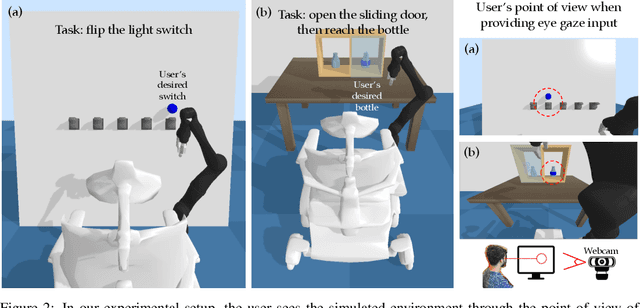
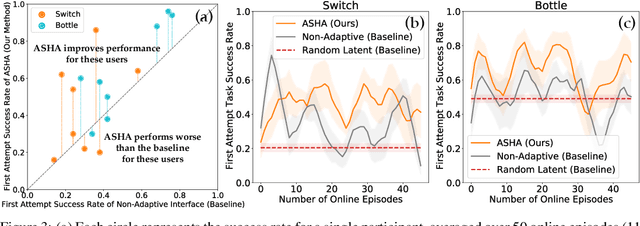
Building assistive interfaces for controlling robots through arbitrary, high-dimensional, noisy inputs (e.g., webcam images of eye gaze) can be challenging, especially when it involves inferring the user's desired action in the absence of a natural 'default' interface. Reinforcement learning from online user feedback on the system's performance presents a natural solution to this problem, and enables the interface to adapt to individual users. However, this approach tends to require a large amount of human-in-the-loop training data, especially when feedback is sparse. We propose a hierarchical solution that learns efficiently from sparse user feedback: we use offline pre-training to acquire a latent embedding space of useful, high-level robot behaviors, which, in turn, enables the system to focus on using online user feedback to learn a mapping from user inputs to desired high-level behaviors. The key insight is that access to a pre-trained policy enables the system to learn more from sparse rewards than a na\"ive RL algorithm: using the pre-trained policy, the system can make use of successful task executions to relabel, in hindsight, what the user actually meant to do during unsuccessful executions. We evaluate our method primarily through a user study with 12 participants who perform tasks in three simulated robotic manipulation domains using a webcam and their eye gaze: flipping light switches, opening a shelf door to reach objects inside, and rotating a valve. The results show that our method successfully learns to map 128-dimensional gaze features to 7-dimensional joint torques from sparse rewards in under 10 minutes of online training, and seamlessly helps users who employ different gaze strategies, while adapting to distributional shift in webcam inputs, tasks, and environments.
Reconstruction-Computation-Quantization (RCQ): A Paradigm for Low Bit Width LDPC Decoding
Nov 17, 2021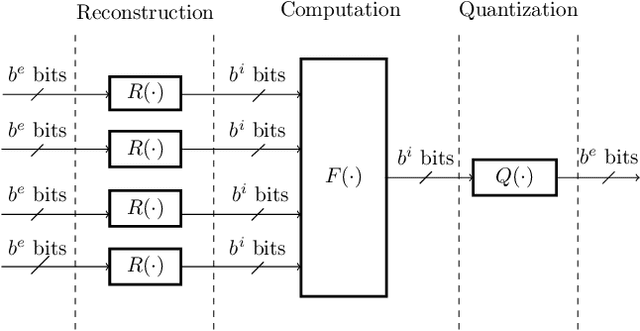
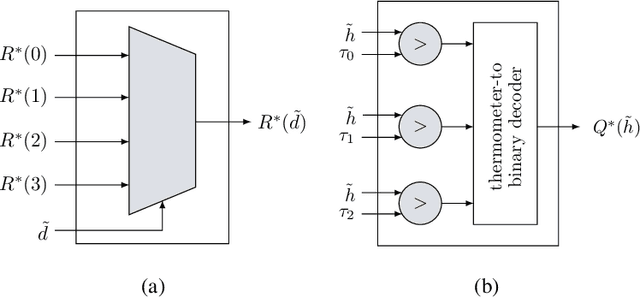
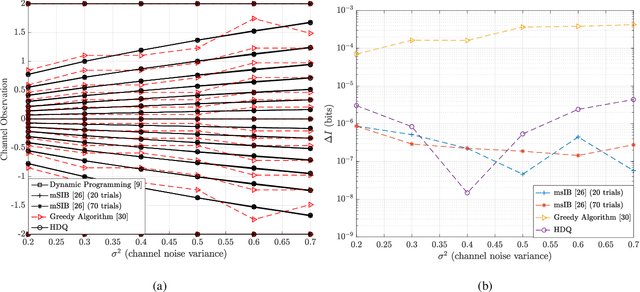
This paper uses the reconstruction-computation-quantization (RCQ) paradigm to decode low-density parity-check (LDPC) codes. RCQ facilitates dynamic non-uniform quantization to achieve good frame error rate (FER) performance with very low message precision. For message-passing according to a flooding schedule, the RCQ parameters are designed by discrete density evolution (DDE). Simulation results on an IEEE 802.11 LDPC code show that for 4-bit messages, a flooding MinSum RCQ decoder outperforms table-lookup approaches such as information bottleneck (IB) or Min-IB decoding, with significantly fewer parameters to be stored. Additionally, this paper introduces layer-specific RCQ (LS-RCQ), an extension of RCQ decoding for layered architectures. LS-RCQ uses layer-specific message representations to achieve the best possible FER performance. For LS-RCQ, this paper proposes using layered DDE featuring hierarchical dynamic quantization (HDQ) to design LS-RCQ parameters efficiently. Finally, this paper studies field-programmable gate array (FPGA) implementations of RCQ decoders. Simulation results for a (9472, 8192) quasi-cyclic (QC) LDPC code show that a layered MinSum RCQ decoder with 3-bit messages achieves more than a $10\%$ reduction in LUTs and routed nets and more than a $6\%$ decrease in register usage while maintaining comparable decoding performance, compared to a 5-bit offset MinSum decoder.
FPGA Implementations of Layered MinSum LDPC Decoders Using RCQ Message Passing
Apr 19, 2021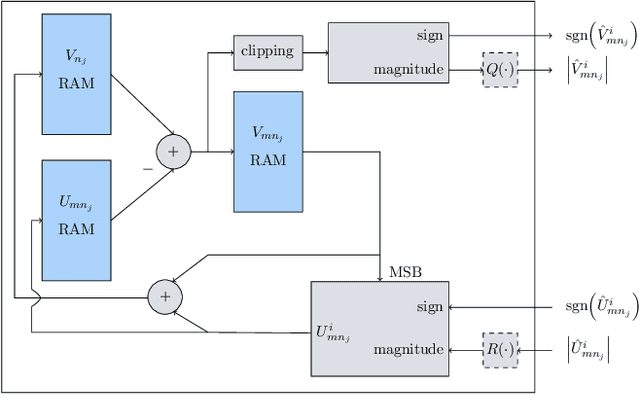
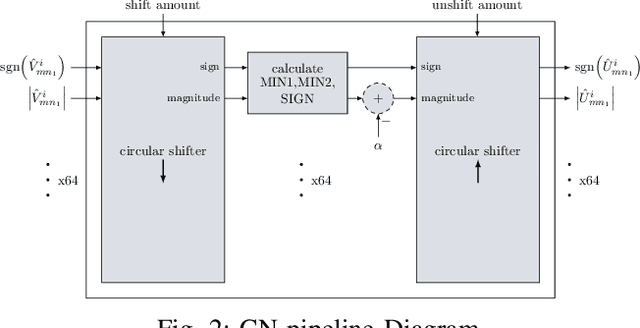
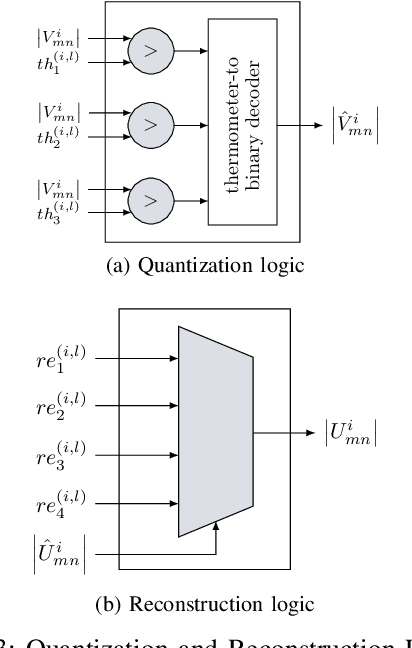
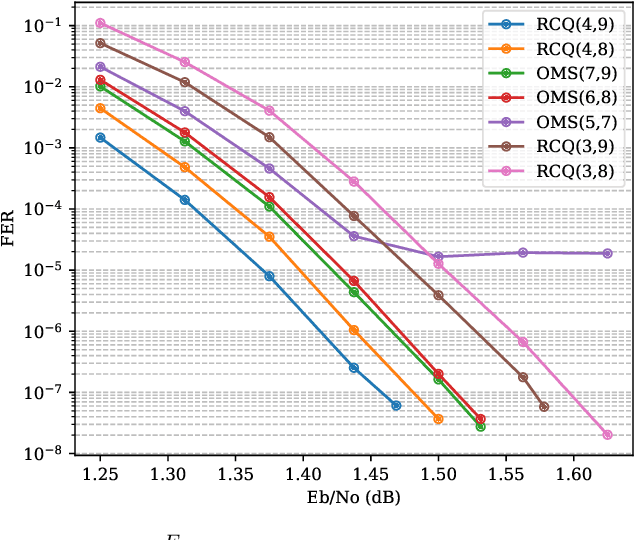
Non-uniform message quantization techniques such as reconstruction-computation-quantization (RCQ) improve error-correction performance and decrease hardware complexity of low-density parity-check (LDPC) decoders that use a flooding schedule. Layered MinSum RCQ (L-msRCQ) enables message quantization to be utilized for layered decoders and irregular LDPC codes. We investigate field-programmable gate array (FPGA) implementations of L-msRCQ decoders. Three design methods for message quantization are presented, which we name the Lookup, Broadcast, and Dribble methods. The decoding performance and hardware complexity of these schemes are compared to a layered offset MinSum (OMS) decoder. Simulation results on a (16384, 8192) protograph-based raptor-like (PBRL) LDPC code show that a 4-bit L-msRCQ decoder using the Broadcast method can achieve a 0.03 dB improvement in error-correction performance while using 12% fewer registers than the OMS decoder. A Broadcast-based 3-bit L-msRCQ decoder uses 15% fewer lookup tables, 18% fewer registers, and 13% fewer routed nets than the OMS decoder, but results in a 0.09 dB loss in performance.