 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLDPC Decoding with Degree-Specific Neural Message Weights and RCQ Decoding
Oct 24, 2023Recently, neural networks have improved MinSum message-passing decoders for low-density parity-check (LDPC) codes by multiplying or adding weights to the messages, where the weights are determined by a neural network. The neural network complexity to determine distinct weights for each edge is high, often limiting the application to relatively short LDPC codes. Furthermore, storing separate weights for every edge and every iteration can be a burden for hardware implementations. To reduce neural network complexity and storage requirements, this paper proposes a family of weight-sharing schemes that use the same weight for edges that have the same check node degree and/or variable node degree. Our simulation results show that node-degree-based weight-sharing can deliver the same performance requiring distinct weights for each node. This paper also combines these degree-specific neural weights with a reconstruction-computation-quantization (RCQ) decoder to produce a weighted RCQ (W-RCQ) decoder. The W-RCQ decoder with node-degree-based weight sharing has a reduced hardware requirement compared with the original RCQ decoder. As an additional contribution, this paper identifies and resolves a gradient explosion issue that can arise when training neural LDPC decoders.
Reconstruction-Computation-Quantization (RCQ): A Paradigm for Low Bit Width LDPC Decoding
Nov 17, 2021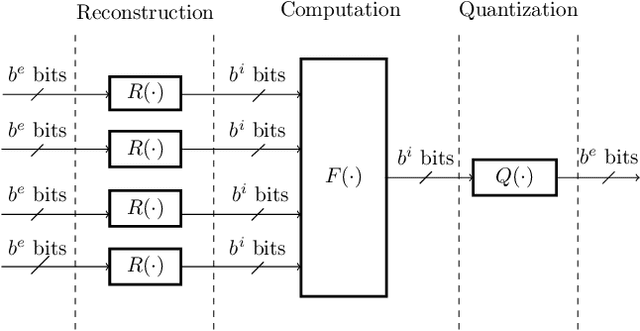
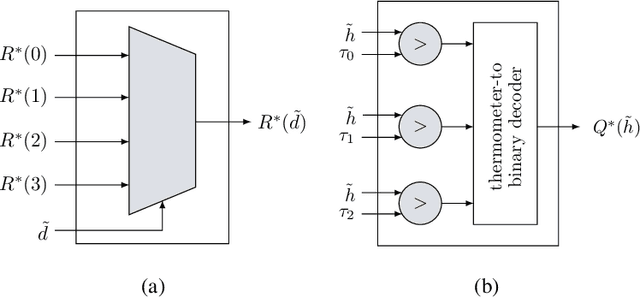
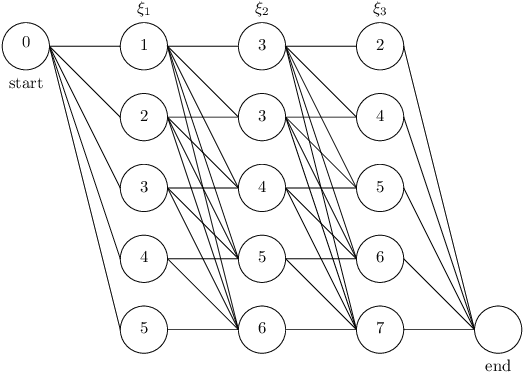
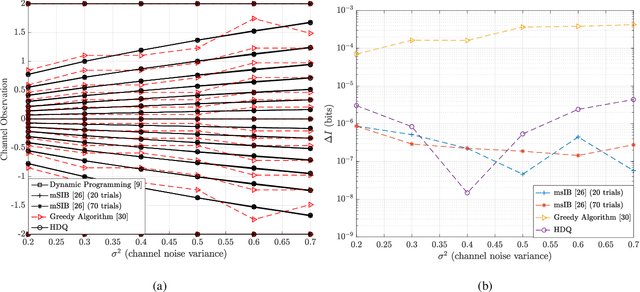
This paper uses the reconstruction-computation-quantization (RCQ) paradigm to decode low-density parity-check (LDPC) codes. RCQ facilitates dynamic non-uniform quantization to achieve good frame error rate (FER) performance with very low message precision. For message-passing according to a flooding schedule, the RCQ parameters are designed by discrete density evolution (DDE). Simulation results on an IEEE 802.11 LDPC code show that for 4-bit messages, a flooding MinSum RCQ decoder outperforms table-lookup approaches such as information bottleneck (IB) or Min-IB decoding, with significantly fewer parameters to be stored. Additionally, this paper introduces layer-specific RCQ (LS-RCQ), an extension of RCQ decoding for layered architectures. LS-RCQ uses layer-specific message representations to achieve the best possible FER performance. For LS-RCQ, this paper proposes using layered DDE featuring hierarchical dynamic quantization (HDQ) to design LS-RCQ parameters efficiently. Finally, this paper studies field-programmable gate array (FPGA) implementations of RCQ decoders. Simulation results for a (9472, 8192) quasi-cyclic (QC) LDPC code show that a layered MinSum RCQ decoder with 3-bit messages achieves more than a $10\%$ reduction in LUTs and routed nets and more than a $6\%$ decrease in register usage while maintaining comparable decoding performance, compared to a 5-bit offset MinSum decoder.
BEANNA: A Binary-Enabled Architecture for Neural Network Acceleration
Aug 04, 2021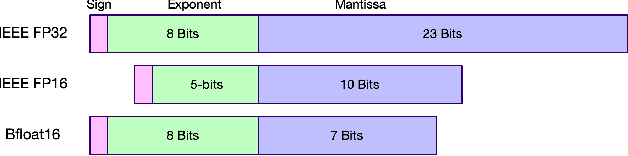
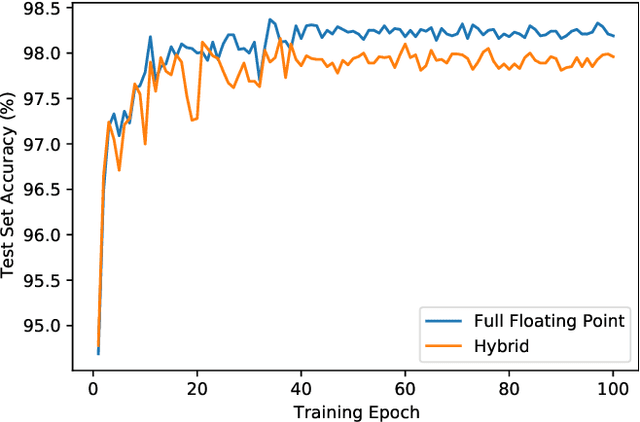
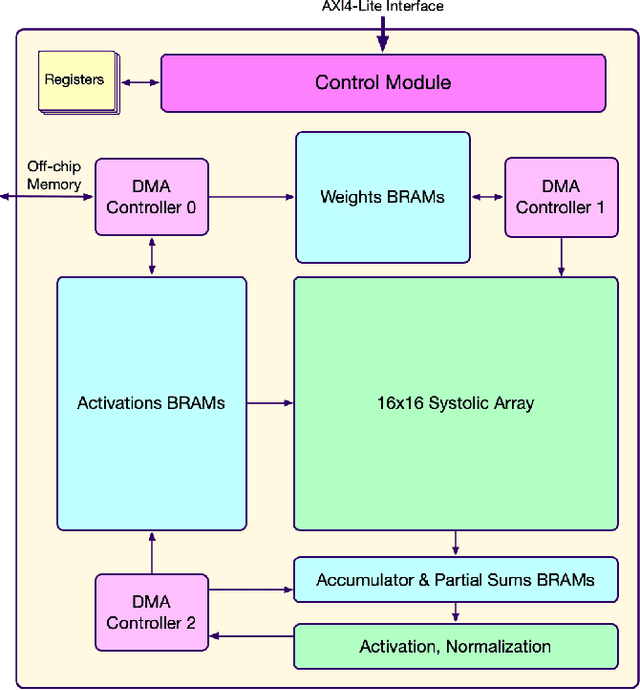
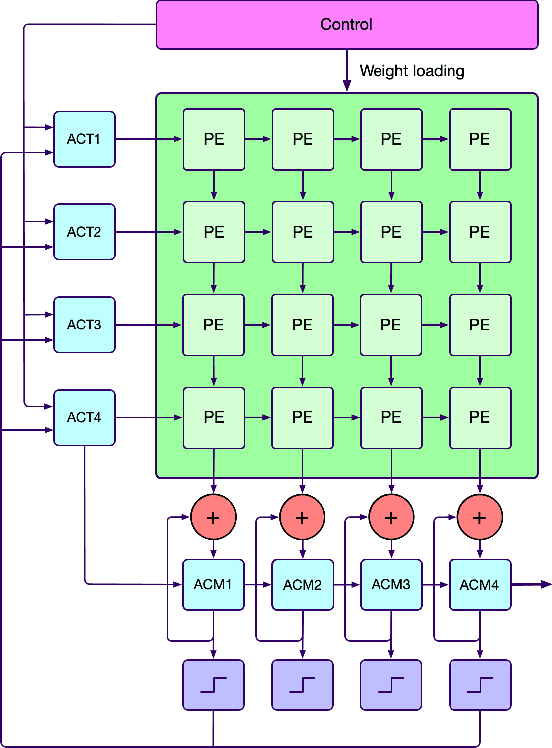
Modern hardware design trends have shifted towards specialized hardware acceleration for computationally intensive tasks like machine learning and computer vision. While these complex workloads can be accelerated by commercial GPUs, domain-specific hardware is far more optimal when needing to meet the stringent memory, throughput, and power constraints of mobile and embedded devices. This paper proposes and evaluates a Binary-Enabled Architecture for Neural Network Acceleration (BEANNA), a neural network hardware accelerator capable of processing both floating point and binary network layers. Through the use of a novel 16x16 systolic array based matrix multiplier with processing elements that compute both floating point and binary multiply-adds, BEANNA seamlessly switches between high precision floating point and binary neural network layers. Running at a clock speed of 100MHz, BEANNA achieves a peak throughput of 52.8 GigaOps/second when operating in high precision mode, and 820 GigaOps/second when operating in binary mode. Evaluation of BEANNA was performed by comparing a hybrid network with floating point outer layers and binary hidden layers to a network with only floating point layers. The hybrid network accelerated using BEANNA achieved a 194% throughput increase, a 68% memory usage decrease, and a 66% energy consumption decrease per inference, all this at the cost of a mere 0.23% classification accuracy decrease on the MNIST dataset.
FPGA Implementations of Layered MinSum LDPC Decoders Using RCQ Message Passing
Apr 19, 2021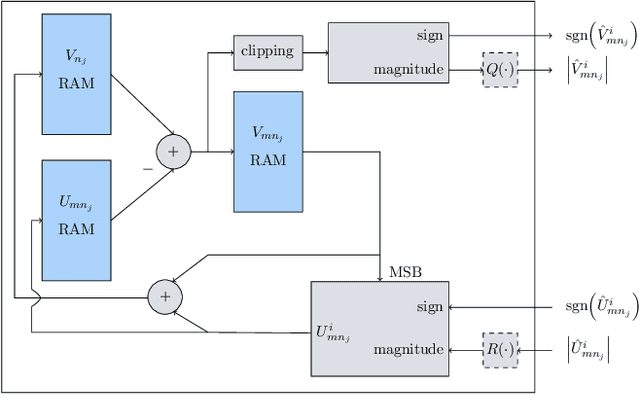
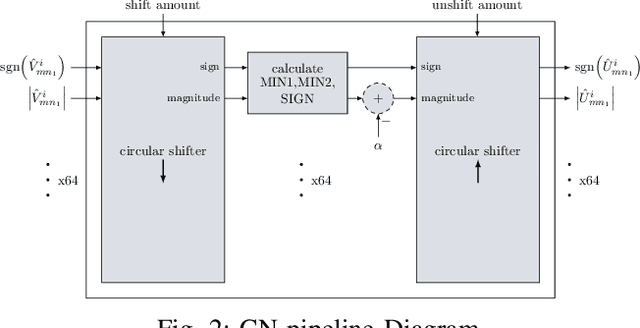
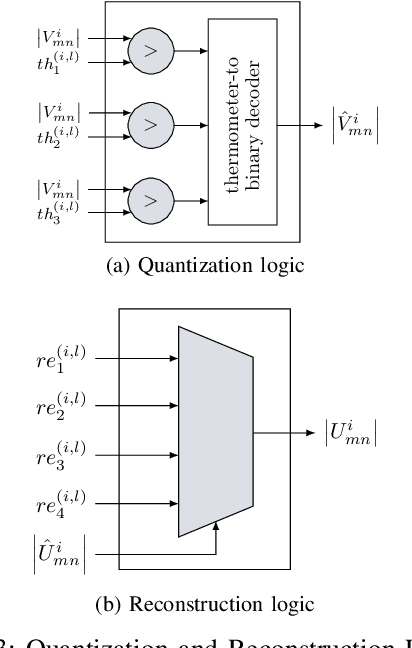
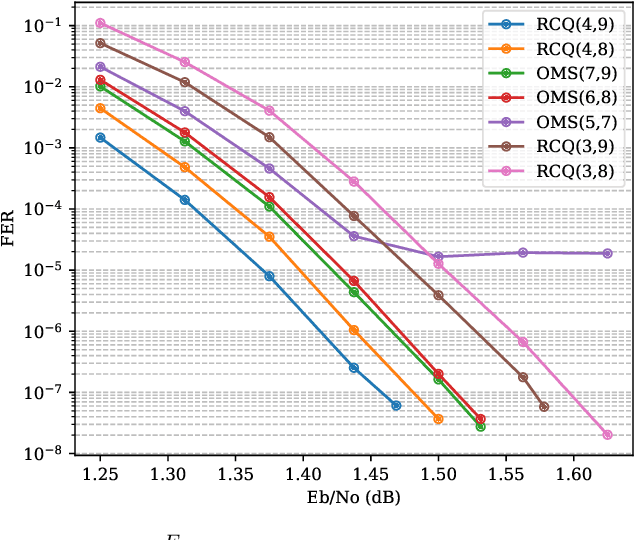
Non-uniform message quantization techniques such as reconstruction-computation-quantization (RCQ) improve error-correction performance and decrease hardware complexity of low-density parity-check (LDPC) decoders that use a flooding schedule. Layered MinSum RCQ (L-msRCQ) enables message quantization to be utilized for layered decoders and irregular LDPC codes. We investigate field-programmable gate array (FPGA) implementations of L-msRCQ decoders. Three design methods for message quantization are presented, which we name the Lookup, Broadcast, and Dribble methods. The decoding performance and hardware complexity of these schemes are compared to a layered offset MinSum (OMS) decoder. Simulation results on a (16384, 8192) protograph-based raptor-like (PBRL) LDPC code show that a 4-bit L-msRCQ decoder using the Broadcast method can achieve a 0.03 dB improvement in error-correction performance while using 12% fewer registers than the OMS decoder. A Broadcast-based 3-bit L-msRCQ decoder uses 15% fewer lookup tables, 18% fewer registers, and 13% fewer routed nets than the OMS decoder, but results in a 0.09 dB loss in performance.