 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEANNA: A Binary-Enabled Architecture for Neural Network Acceleration
Paper and Code
Aug 04, 2021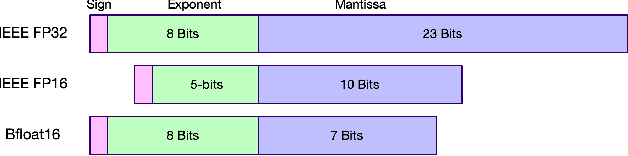
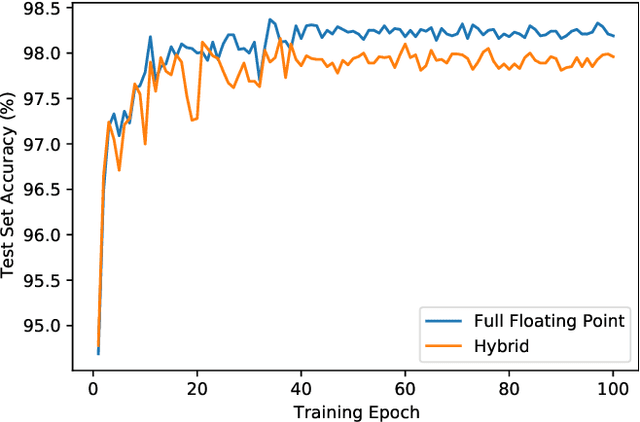
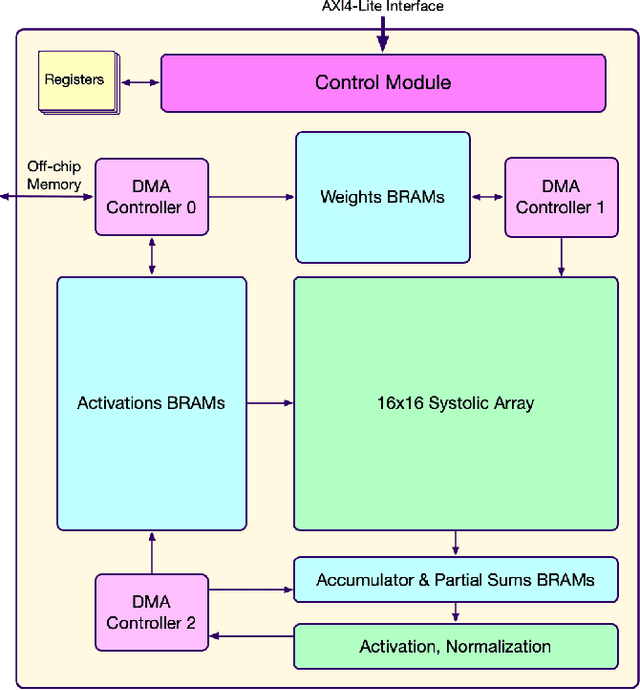
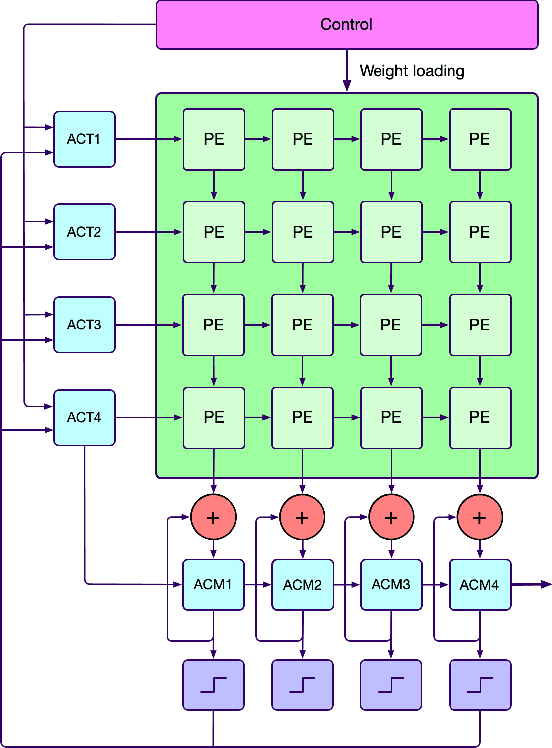
Modern hardware design trends have shifted towards specialized hardware acceleration for computationally intensive tasks like machine learning and computer vision. While these complex workloads can be accelerated by commercial GPUs, domain-specific hardware is far more optimal when needing to meet the stringent memory, throughput, and power constraints of mobile and embedded devices. This paper proposes and evaluates a Binary-Enabled Architecture for Neural Network Acceleration (BEANNA), a neural network hardware accelerator capable of processing both floating point and binary network layers. Through the use of a novel 16x16 systolic array based matrix multiplier with processing elements that compute both floating point and binary multiply-adds, BEANNA seamlessly switches between high precision floating point and binary neural network layers. Running at a clock speed of 100MHz, BEANNA achieves a peak throughput of 52.8 GigaOps/second when operating in high precision mode, and 820 GigaOps/second when operating in binary mode. Evaluation of BEANNA was performed by comparing a hybrid network with floating point outer layers and binary hidden layers to a network with only floating point layers. The hybrid network accelerated using BEANNA achieved a 194% throughput increase, a 68% memory usage decrease, and a 66% energy consumption decrease per inference, all this at the cost of a mere 0.23% classification accuracy decrease on the MNIST dataset.