 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Taxonomy for Evaluating Generalist Robot Policies
Mar 03, 2025Machine learning for robotics promises to unlock generalization to novel tasks and environments. Guided by this promise, many recent works have focused on scaling up robot data collection and developing larger, more expressive policies to achieve this. But how do we measure progress towards this goal of policy generalization in practice? Evaluating and quantifying generalization is the Wild West of modern robotics, with each work proposing and measuring different types of generalization in their own, often difficult to reproduce, settings. In this work, our goal is (1) to outline the forms of generalization we believe are important in robot manipulation in a comprehensive and fine-grained manner, and (2) to provide reproducible guidelines for measuring these notions of generalization. We first propose STAR-Gen, a taxonomy of generalization for robot manipulation structured around visual, semantic, and behavioral generalization. We discuss how our taxonomy encompasses most prior notions of generalization in robotics. Next, we instantiate STAR-Gen with a concrete real-world benchmark based on the widely-used Bridge V2 dataset. We evaluate a variety of state-of-the-art models on this benchmark to demonstrate the utility of our taxonomy in practice. Our taxonomy of generalization can yield many interesting insights into existing models: for example, we observe that current vision-language-action models struggle with various types of semantic generalization, despite the promise of pre-training on internet-scale language datasets. We believe STAR-Gen and our guidelines can improve the dissemination and evaluation of progress towards generalization in robotics, which we hope will guide model design and future data collection efforts. We provide videos and demos at our website stargen-taxonomy.github.io.
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Mar 19, 2024



The creation of large, diverse, high-quality robot manipulation datasets is an important stepping stone on the path toward more capable and robust robotic manipulation policies. However, creating such datasets is challenging: collecting robot manipulation data in diverse environments poses logistical and safety challenges and requires substantial investments in hardware and human labour. As a result, even the most general robot manipulation policies today are mostly trained on data collected in a small number of environments with limited scene and task diversity. In this work, we introduce DROID (Distributed Robot Interaction Dataset), a diverse robot manipulation dataset with 76k demonstration trajectories or 350 hours of interaction data, collected across 564 scenes and 84 tasks by 50 data collectors in North America, Asia, and Europe over the course of 12 months. We demonstrate that training with DROID leads to policies with higher performance and improved generalization ability. We open source the full dataset, policy learning code, and a detailed guide for reproducing our robot hardware setup.
Efficient Data Collection for Robotic Manipulation via Compositional Generalization
Mar 08, 2024



Data collection has become an increasingly important problem in robotic manipulation, yet there still lacks much understanding of how to effectively collect data to facilitate broad generalization. Recent works on large-scale robotic data collection typically vary a wide range of environmental factors during data collection, such as object types and table textures. While these works attempt to cover a diverse variety of scenarios, they do not explicitly account for the possible compositional abilities of policies trained on the data. If robot policies are able to compose different environmental factors of variation (e.g., object types, table heights) from their training data to succeed when encountering unseen factor combinations, then we can exploit this to avoid collecting data for situations that composition would address. To investigate this possibility, we conduct thorough empirical studies both in simulation and on a real robot that compare data collection strategies and assess whether visual imitation learning policies can compose environmental factors. We find that policies do exhibit composition, although leveraging prior robotic datasets is critical for this on a real robot. We use these insights to provide better practices for in-domain data collection by proposing data collection strategies that exploit composition, which can induce better generalization than naive approaches for the same amount of effort during data collection. We further demonstrate that a real robot policy trained on data from such a strategy achieves a success rate of 77.5% when transferred to entirely new environments that encompass unseen combinations of environmental factors, whereas policies trained using data collected without accounting for environmental variation fail to transfer effectively, with a success rate of only 2.5%. We provide videos at http://iliad.stanford.edu/robot-data-comp/.
Physically Grounded Vision-Language Models for Robotic Manipulation
Sep 13, 2023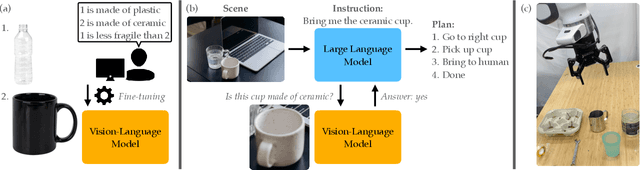

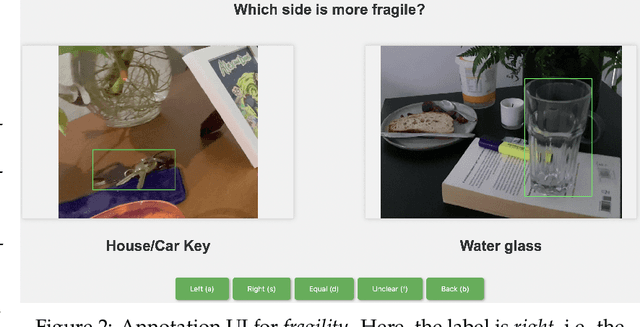
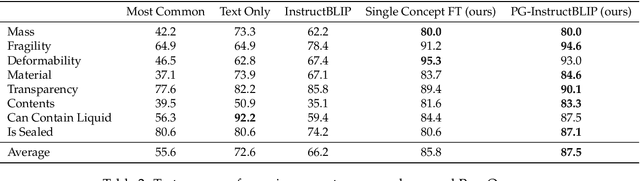
Recent advances in vision-language models (VLMs) have led to improved performance on tasks such as visual question answering and image captioning. Consequently, these models are now well-positioned to reason about the physical world, particularly within domains such as robotic manipulation. However, current VLMs are limited in their understanding of the physical concepts (e.g., material, fragility) of common objects, which restricts their usefulness for robotic manipulation tasks that involve interaction and physical reasoning about such objects. To address this limitation, we propose PhysObjects, an object-centric dataset of 39.6K crowd-sourced and 417K automated physical concept annotations of common household objects. We demonstrate that fine-tuning a VLM on PhysObjects improves its understanding of physical object concepts, including generalization to held-out concepts, by capturing human priors of these concepts from visual appearance. We incorporate this physically-grounded VLM in an interactive framework with a large language model-based robotic planner, and show improved planning performance on tasks that require reasoning about physical object concepts, compared to baselines that do not leverage physically-grounded VLMs. We additionally illustrate the benefits of our physically-grounded VLM on a real robot, where it improves task success rates. We release our dataset and provide further details and visualizations of our results at https://iliad.stanford.edu/pg-vlm/.
Bootstrapping Adaptive Human-Machine Interfaces with Offline Reinforcement Learning
Sep 07, 2023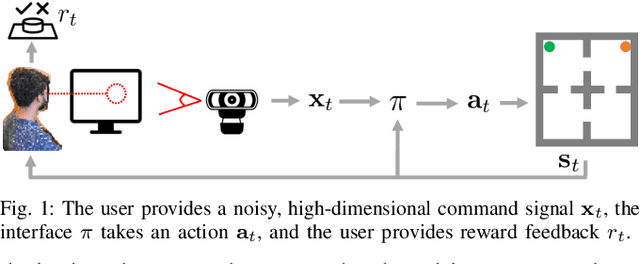
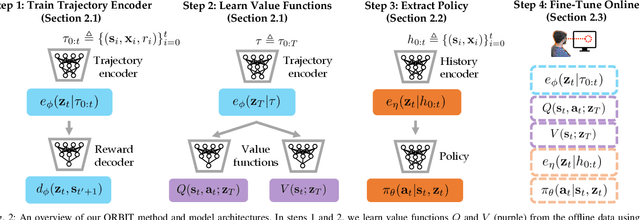
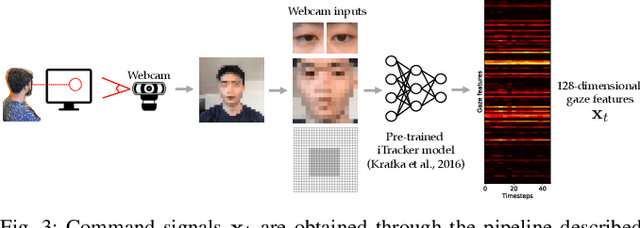
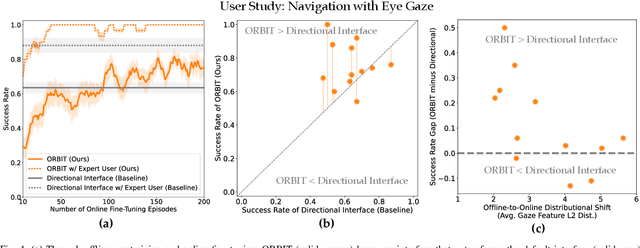
Adaptive interfaces can help users perform sequential decision-making tasks like robotic teleoperation given noisy, high-dimensional command signals (e.g., from a brain-computer interface). Recent advances in human-in-the-loop machine learning enable such systems to improve by interacting with users, but tend to be limited by the amount of data that they can collect from individual users in practice. In this paper, we propose a reinforcement learning algorithm to address this by training an interface to map raw command signals to actions using a combination of offline pre-training and online fine-tuning. To address the challenges posed by noisy command signals and sparse rewards, we develop a novel method for representing and inferring the user's long-term intent for a given trajectory. We primarily evaluate our method's ability to assist users who can only communicate through noisy, high-dimensional input channels through a user study in which 12 participants performed a simulated navigation task by using their eye gaze to modulate a 128-dimensional command signal from their webcam. The results show that our method enables successful goal navigation more often than a baseline directional interface, by learning to denoise user commands signals and provide shared autonomy assistance. We further evaluate on a simulated Sawyer pushing task with eye gaze control, and the Lunar Lander game with simulated user commands, and find that our method improves over baseline interfaces in these domains as well. Extensive ablation experiments with simulated user commands empirically motivate each component of our method.
Distance Weighted Supervised Learning for Offline Interaction Data
Apr 26, 2023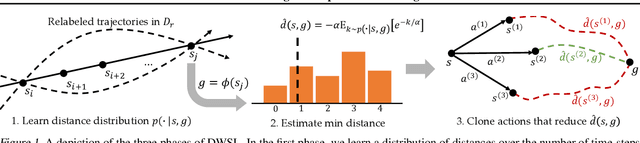



Sequential decision making algorithms often struggle to leverage different sources of unstructured offline interaction data. Imitation learning (IL) methods based on supervised learning are robust, but require optimal demonstrations, which are hard to collect. Offline goal-conditioned reinforcement learning (RL) algorithms promise to learn from sub-optimal data, but face optimization challenges especially with high-dimensional data. To bridge the gap between IL and RL, we introduce Distance Weighted Supervised Learning or DWSL, a supervised method for learning goal-conditioned policies from offline data. DWSL models the entire distribution of time-steps between states in offline data with only supervised learning, and uses this distribution to approximate shortest path distances. To extract a policy, we weight actions by their reduction in distance estimates. Theoretically, DWSL converges to an optimal policy constrained to the data distribution, an attractive property for offline learning, without any bootstrapping. Across all datasets we test, DWSL empirically maintains behavior cloning as a lower bound while still exhibiting policy improvement. In high-dimensional image domains, DWSL surpasses the performance of both prior goal-conditioned IL and RL algorithms. Visualizations and code can be found at https://sites.google.com/view/dwsl/home .
X2T: Training an X-to-Text Typing Interface with Online Learning from User Feedback
Mar 07, 2022

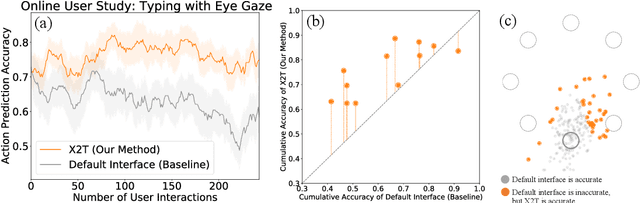

We aim to help users communicate their intent to machines using flexible, adaptive interfaces that translate arbitrary user input into desired actions. In this work, we focus on assistive typing applications in which a user cannot operate a keyboard, but can instead supply other inputs, such as webcam images that capture eye gaze or neural activity measured by a brain implant. Standard methods train a model on a fixed dataset of user inputs, then deploy a static interface that does not learn from its mistakes; in part, because extracting an error signal from user behavior can be challenging. We investigate a simple idea that would enable such interfaces to improve over time, with minimal additional effort from the user: online learning from user feedback on the accuracy of the interface's actions. In the typing domain, we leverage backspaces as feedback that the interface did not perform the desired action. We propose an algorithm called x-to-text (X2T) that trains a predictive model of this feedback signal, and uses this model to fine-tune any existing, default interface for translating user input into actions that select words or characters. We evaluate X2T through a small-scale online user study with 12 participants who type sentences by gazing at their desired words, a large-scale observational study on handwriting samples from 60 users, and a pilot study with one participant using an electrocorticography-based brain-computer interface. The results show that X2T learns to outperform a non-adaptive default interface, stimulates user co-adaptation to the interface, personalizes the interface to individual users, and can leverage offline data collected from the default interface to improve its initial performance and accelerate online learning.
ASHA: Assistive Teleoperation via Human-in-the-Loop Reinforcement Learning
Feb 05, 2022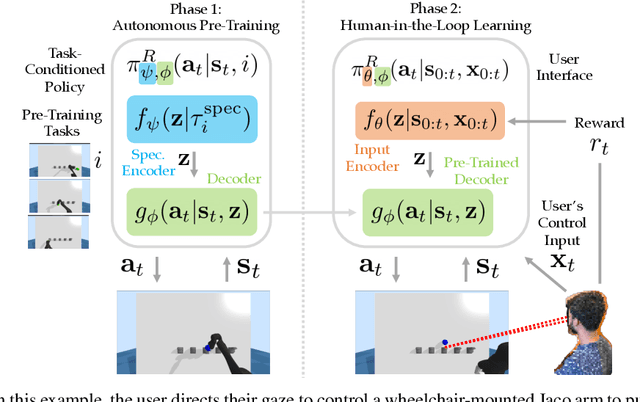
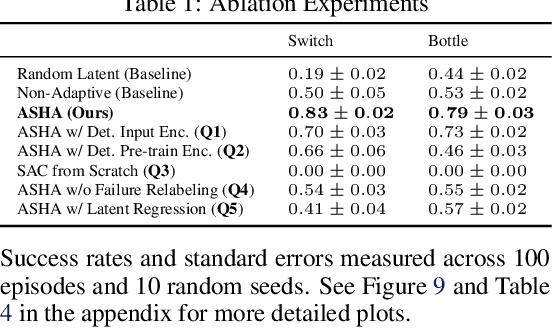
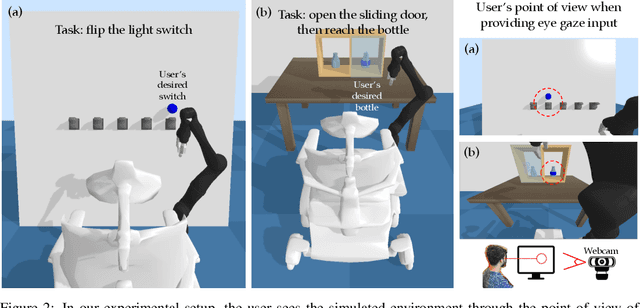
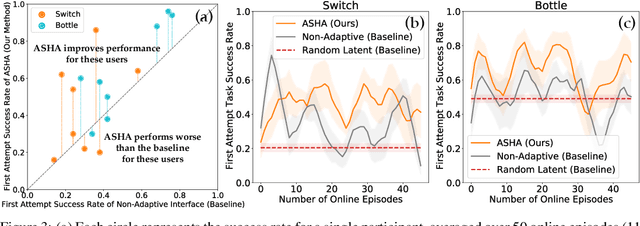
Building assistive interfaces for controlling robots through arbitrary, high-dimensional, noisy inputs (e.g., webcam images of eye gaze) can be challenging, especially when it involves inferring the user's desired action in the absence of a natural 'default' interface. Reinforcement learning from online user feedback on the system's performance presents a natural solution to this problem, and enables the interface to adapt to individual users. However, this approach tends to require a large amount of human-in-the-loop training data, especially when feedback is sparse. We propose a hierarchical solution that learns efficiently from sparse user feedback: we use offline pre-training to acquire a latent embedding space of useful, high-level robot behaviors, which, in turn, enables the system to focus on using online user feedback to learn a mapping from user inputs to desired high-level behaviors. The key insight is that access to a pre-trained policy enables the system to learn more from sparse rewards than a na\"ive RL algorithm: using the pre-trained policy, the system can make use of successful task executions to relabel, in hindsight, what the user actually meant to do during unsuccessful executions. We evaluate our method primarily through a user study with 12 participants who perform tasks in three simulated robotic manipulation domains using a webcam and their eye gaze: flipping light switches, opening a shelf door to reach objects inside, and rotating a valve. The results show that our method successfully learns to map 128-dimensional gaze features to 7-dimensional joint torques from sparse rewards in under 10 minutes of online training, and seamlessly helps users who employ different gaze strategies, while adapting to distributional shift in webcam inputs, tasks, and environments.