 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonoDuo: Using One Robot Arm to Learn Bimanual Policies
May 28, 2026Bimanual coordination is essential for many real-world manipulation tasks, yet learning bimanual robot policies is limited by the scarcity of bimanual robots and datasets. Single-arm robots, however, are widely available in research labs. Can we leverage them to train bimanual robot policies? We present MonoDuo, a framework for learning bimanual manipulation policies using single-arm robot demonstrations paired with human collaboration. MonoDuo collects data by teleoperating a single-arm robot to perform one side of a bimanual task while a human performs the other, then swapping roles to cover both sides. RGB-D observations from a wrist-mounted and fixed camera are augmented into synthetic demonstrations for target bimanual robots using state-of-the-art hand pose estimation, image and point cloud segmentation, and inpainting. These synthetic demonstrations, grounded in real robot kinematics, are used to train bimanual policies. We evaluate MonoDuo on five tasks: box lifting, backpack packing, cloth folding, jacket zipping, and plate handover. Compared to approaches relying solely on human bimanual videos, MonoDuo enables zero-shot deployment on unseen bimanual robot configurations, achieving success rates up to 70%. With only 25 target robot demonstrations, few-shot finetuning further boosts success rates by 65-70% over training from scratch, demonstrating MonoDuo's effectiveness in efficiently transferring knowledge from single-arm robot data to bimanual robot policies.
OXE-AugE: A Large-Scale Robot Augmentation of OXE for Scaling Cross-Embodiment Policy Learning
Dec 15, 2025

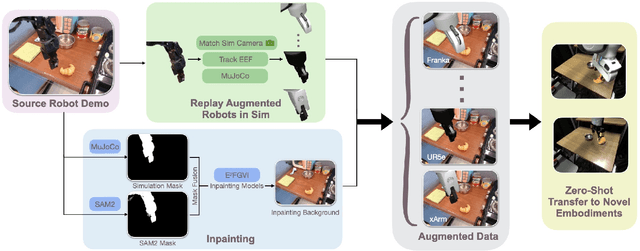
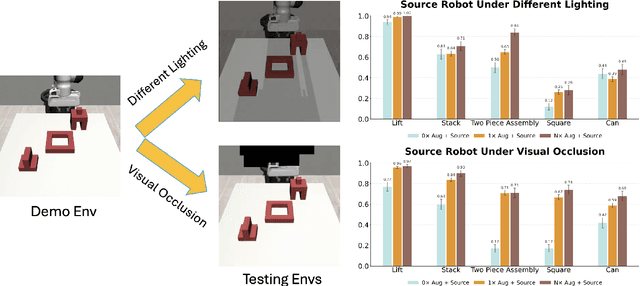
Large and diverse datasets are needed for training generalist robot policies that have potential to control a variety of robot embodiments -- robot arm and gripper combinations -- across diverse tasks and environments. As re-collecting demonstrations and retraining for each new hardware platform are prohibitively costly, we show that existing robot data can be augmented for transfer and generalization. The Open X-Embodiment (OXE) dataset, which aggregates demonstrations from over 60 robot datasets, has been widely used as the foundation for training generalist policies. However, it is highly imbalanced: the top four robot types account for over 85\% of its real data, which risks overfitting to robot-scene combinations. We present AugE-Toolkit, a scalable robot augmentation pipeline, and OXE-AugE, a high-quality open-source dataset that augments OXE with 9 different robot embodiments. OXE-AugE provides over 4.4 million trajectories, more than triple the size of the original OXE. We conduct a systematic study of how scaling robot augmentation impacts cross-embodiment learning. Results suggest that augmenting datasets with diverse arms and grippers improves policy performance not only on the augmented robots, but also on unseen robots and even the original robots under distribution shifts. In physical experiments, we demonstrate that state-of-the-art generalist policies such as OpenVLA and $π_0$ benefit from fine-tuning on OXE-AugE, improving success rates by 24-45% on previously unseen robot-gripper combinations across four real-world manipulation tasks. Project website: https://OXE-AugE.github.io/.
Robo-DM: Data Management For Large Robot Datasets
May 21, 2025
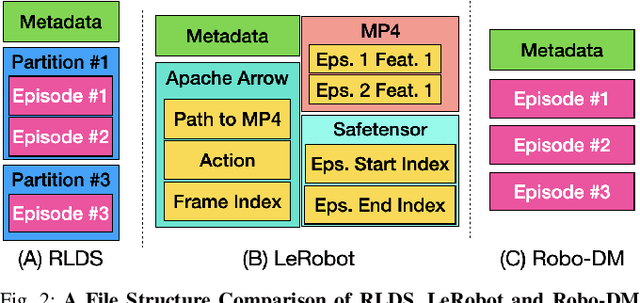


Recent results suggest that very large datasets of teleoperated robot demonstrations can be used to train transformer-based models that have the potential to generalize to new scenes, robots, and tasks. However, curating, distributing, and loading large datasets of robot trajectories, which typically consist of video, textual, and numerical modalities - including streams from multiple cameras - remains challenging. We propose Robo-DM, an efficient open-source cloud-based data management toolkit for collecting, sharing, and learning with robot data. With Robo-DM, robot datasets are stored in a self-contained format with Extensible Binary Meta Language (EBML). Robo-DM can significantly reduce the size of robot trajectory data, transfer costs, and data load time during training. Compared to the RLDS format used in OXE datasets, Robo-DM's compression saves space by up to 70x (lossy) and 3.5x (lossless). Robo-DM also accelerates data retrieval by load-balancing video decoding with memory-mapped decoding caches. Compared to LeRobot, a framework that also uses lossy video compression, Robo-DM is up to 50x faster when decoding sequentially. We physically evaluate a model trained by Robo-DM with lossy compression, a pick-and-place task, and In-Context Robot Transformer. Robo-DM uses 75x compression of the original dataset and does not suffer reduction in downstream task accuracy.
Sim-and-Real Co-Training: A Simple Recipe for Vision-Based Robotic Manipulation
Mar 31, 2025Large real-world robot datasets hold great potential to train generalist robot models, but scaling real-world human data collection is time-consuming and resource-intensive. Simulation has great potential in supplementing large-scale data, especially with recent advances in generative AI and automated data generation tools that enable scalable creation of robot behavior datasets. However, training a policy solely in simulation and transferring it to the real world often demands substantial human effort to bridge the reality gap. A compelling alternative is to co-train the policy on a mixture of simulation and real-world datasets. Preliminary studies have recently shown this strategy to substantially improve the performance of a policy over one trained on a limited amount of real-world data. Nonetheless, the community lacks a systematic understanding of sim-and-real co-training and what it takes to reap the benefits of simulation data for real-robot learning. This work presents a simple yet effective recipe for utilizing simulation data to solve vision-based robotic manipulation tasks. We derive this recipe from comprehensive experiments that validate the co-training strategy on various simulation and real-world datasets. Using two domains--a robot arm and a humanoid--across diverse tasks, we demonstrate that simulation data can enhance real-world task performance by an average of 38%, even with notable differences between the simulation and real-world data. Videos and additional results can be found at https://co-training.github.io/
RoVi-Aug: Robot and Viewpoint Augmentation for Cross-Embodiment Robot Learning
Sep 05, 2024



Scaling up robot learning requires large and diverse datasets, and how to efficiently reuse collected data and transfer policies to new embodiments remains an open question. Emerging research such as the Open-X Embodiment (OXE) project has shown promise in leveraging skills by combining datasets including different robots. However, imbalances in the distribution of robot types and camera angles in many datasets make policies prone to overfit. To mitigate this issue, we propose RoVi-Aug, which leverages state-of-the-art image-to-image generative models to augment robot data by synthesizing demonstrations with different robots and camera views. Through extensive physical experiments, we show that, by training on robot- and viewpoint-augmented data, RoVi-Aug can zero-shot deploy on an unseen robot with significantly different camera angles. Compared to test-time adaptation algorithms such as Mirage, RoVi-Aug requires no extra processing at test time, does not assume known camera angles, and allows policy fine-tuning. Moreover, by co-training on both the original and augmented robot datasets, RoVi-Aug can learn multi-robot and multi-task policies, enabling more efficient transfer between robots and skills and improving success rates by up to 30%.
In-Context Imitation Learning via Next-Token Prediction
Aug 28, 2024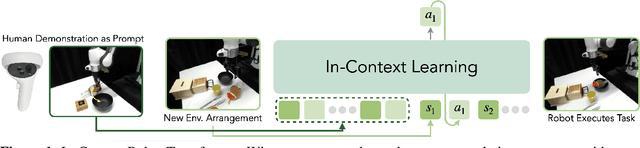
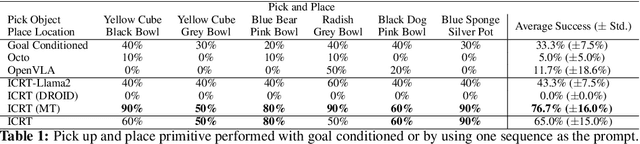
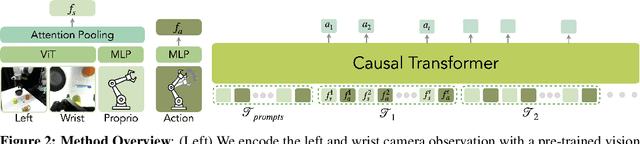
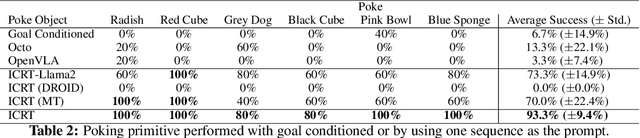
We explore how to enhance next-token prediction models to perform in-context imitation learning on a real robot, where the robot executes new tasks by interpreting contextual information provided during the input phase, without updating its underlying policy parameters. We propose In-Context Robot Transformer (ICRT), a causal transformer that performs autoregressive prediction on sensorimotor trajectories without relying on any linguistic data or reward function. This formulation enables flexible and training-free execution of new tasks at test time, achieved by prompting the model with sensorimotor trajectories of the new task composing of image observations, actions and states tuples, collected through human teleoperation. Experiments with a Franka Emika robot demonstrate that the ICRT can adapt to new tasks specified by prompts, even in environment configurations that differ from both the prompt and the training data. In a multitask environment setup, ICRT significantly outperforms current state-of-the-art next-token prediction models in robotics on generalizing to unseen tasks. Code, checkpoints and data are available on https://icrt.dev/
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Mar 19, 2024



The creation of large, diverse, high-quality robot manipulation datasets is an important stepping stone on the path toward more capable and robust robotic manipulation policies. However, creating such datasets is challenging: collecting robot manipulation data in diverse environments poses logistical and safety challenges and requires substantial investments in hardware and human labour. As a result, even the most general robot manipulation policies today are mostly trained on data collected in a small number of environments with limited scene and task diversity. In this work, we introduce DROID (Distributed Robot Interaction Dataset), a diverse robot manipulation dataset with 76k demonstration trajectories or 350 hours of interaction data, collected across 564 scenes and 84 tasks by 50 data collectors in North America, Asia, and Europe over the course of 12 months. We demonstrate that training with DROID leads to policies with higher performance and improved generalization ability. We open source the full dataset, policy learning code, and a detailed guide for reproducing our robot hardware setup.
Mirage: Cross-Embodiment Zero-Shot Policy Transfer with Cross-Painting
Feb 29, 2024



The ability to reuse collected data and transfer trained policies between robots could alleviate the burden of additional data collection and training. While existing approaches such as pretraining plus finetuning and co-training show promise, they do not generalize to robots unseen in training. Focusing on common robot arms with similar workspaces and 2-jaw grippers, we investigate the feasibility of zero-shot transfer. Through simulation studies on 8 manipulation tasks, we find that state-based Cartesian control policies can successfully zero-shot transfer to a target robot after accounting for forward dynamics. To address robot visual disparities for vision-based policies, we introduce Mirage, which uses "cross-painting"--masking out the unseen target robot and inpainting the seen source robot--during execution in real time so that it appears to the policy as if the trained source robot were performing the task. Despite its simplicity, our extensive simulation and physical experiments provide strong evidence that Mirage can successfully zero-shot transfer between different robot arms and grippers with only minimal performance degradation on a variety of manipulation tasks such as picking, stacking, and assembly, significantly outperforming a generalist policy. Project website: https://robot-mirage.github.io/
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023



Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.
Bagging by Learning to Singulate Layers Using Interactive Perception
Mar 29, 2023Many fabric handling and 2D deformable material tasks in homes and industry require singulating layers of material such as opening a bag or arranging garments for sewing. In contrast to methods requiring specialized sensing or end effectors, we use only visual observations with ordinary parallel jaw grippers. We propose SLIP: Singulating Layers using Interactive Perception, and apply SLIP to the task of autonomous bagging. We develop SLIP-Bagging, a bagging algorithm that manipulates a plastic or fabric bag from an unstructured state, and uses SLIP to grasp the top layer of the bag to open it for object insertion. In physical experiments, a YuMi robot achieves a success rate of 67% to 81% across bags of a variety of materials, shapes, and sizes, significantly improving in success rate and generality over prior work. Experiments also suggest that SLIP can be applied to tasks such as singulating layers of folded cloth and garments. Supplementary material is available at https://sites.google.com/view/slip-bagging/.