 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Gemini Robotics Policies in a Veo World Simulator
Dec 11, 2025Generative world models hold significant potential for simulating interactions with visuomotor policies in varied environments. Frontier video models can enable generation of realistic observations and environment interactions in a scalable and general manner. However, the use of video models in robotics has been limited primarily to in-distribution evaluations, i.e., scenarios that are similar to ones used to train the policy or fine-tune the base video model. In this report, we demonstrate that video models can be used for the entire spectrum of policy evaluation use cases in robotics: from assessing nominal performance to out-of-distribution (OOD) generalization, and probing physical and semantic safety. We introduce a generative evaluation system built upon a frontier video foundation model (Veo). The system is optimized to support robot action conditioning and multi-view consistency, while integrating generative image-editing and multi-view completion to synthesize realistic variations of real-world scenes along multiple axes of generalization. We demonstrate that the system preserves the base capabilities of the video model to enable accurate simulation of scenes that have been edited to include novel interaction objects, novel visual backgrounds, and novel distractor objects. This fidelity enables accurately predicting the relative performance of different policies in both nominal and OOD conditions, determining the relative impact of different axes of generalization on policy performance, and performing red teaming of policies to expose behaviors that violate physical or semantic safety constraints. We validate these capabilities through 1600+ real-world evaluations of eight Gemini Robotics policy checkpoints and five tasks for a bimanual manipulator.
ViTaMIn-B: A Reliable and Efficient Visuo-Tactile Bimanual Manipulation Interface
Nov 08, 2025Handheld devices have opened up unprecedented opportunities to collect large-scale, high-quality demonstrations efficiently. However, existing systems often lack robust tactile sensing or reliable pose tracking to handle complex interaction scenarios, especially for bimanual and contact-rich tasks. In this work, we propose ViTaMIn-B, a more capable and efficient handheld data collection system for such tasks. We first design DuoTact, a novel compliant visuo-tactile sensor built with a flexible frame to withstand large contact forces during manipulation while capturing high-resolution contact geometry. To enhance the cross-sensor generalizability, we propose reconstructing the sensor's global deformation as a 3D point cloud and using it as the policy input. We further develop a robust, unified 6-DoF bimanual pose acquisition process using Meta Quest controllers, which eliminates the trajectory drift issue in common SLAM-based methods. Comprehensive user studies confirm the efficiency and high usability of ViTaMIn-B among novice and expert operators. Furthermore, experiments on four bimanual manipulation tasks demonstrate its superior task performance relative to existing systems.
ViTaMIn: Learning Contact-Rich Tasks Through Robot-Free Visuo-Tactile Manipulation Interface
Apr 08, 2025Tactile information plays a crucial role for humans and robots to interact effectively with their environment, particularly for tasks requiring the understanding of contact properties. Solving such dexterous manipulation tasks often relies on imitation learning from demonstration datasets, which are typically collected via teleoperation systems and often demand substantial time and effort. To address these challenges, we present ViTaMIn, an embodiment-free manipulation interface that seamlessly integrates visual and tactile sensing into a hand-held gripper, enabling data collection without the need for teleoperation. Our design employs a compliant Fin Ray gripper with tactile sensing, allowing operators to perceive force feedback during manipulation for more intuitive operation. Additionally, we propose a multimodal representation learning strategy to obtain pre-trained tactile representations, improving data efficiency and policy robustness. Experiments on seven contact-rich manipulation tasks demonstrate that ViTaMIn significantly outperforms baseline methods, demonstrating its effectiveness for complex manipulation tasks.
OTTER: A Vision-Language-Action Model with Text-Aware Visual Feature Extraction
Mar 05, 2025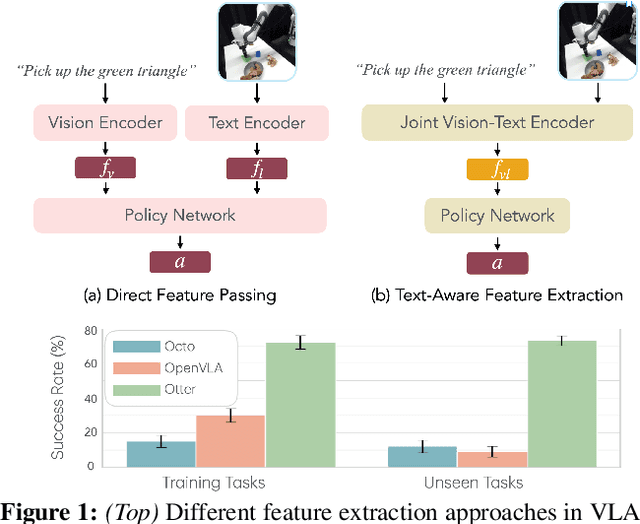
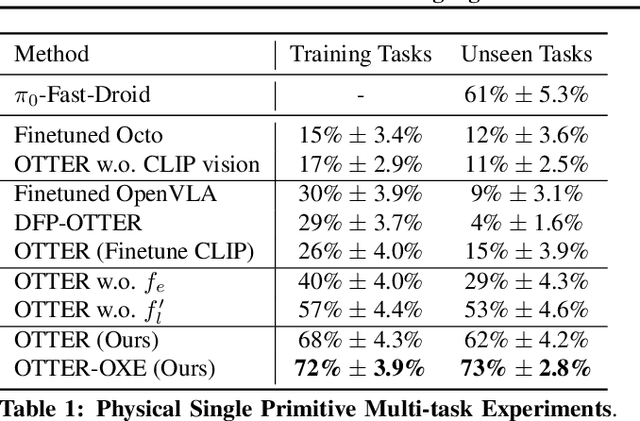
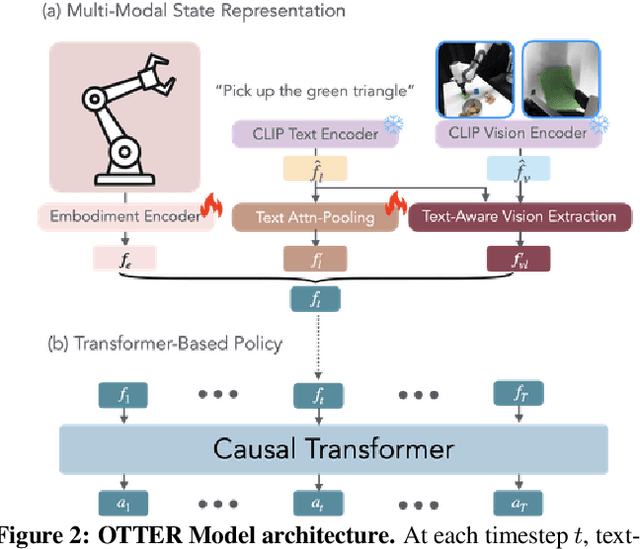
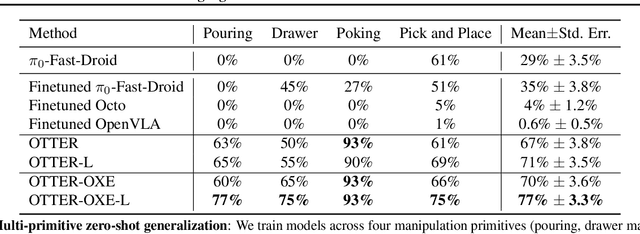
Vision-Language-Action (VLA) models aim to predict robotic actions based on visual observations and language instructions. Existing approaches require fine-tuning pre-trained visionlanguage models (VLMs) as visual and language features are independently fed into downstream policies, degrading the pre-trained semantic alignments. We propose OTTER, a novel VLA architecture that leverages these existing alignments through explicit, text-aware visual feature extraction. Instead of processing all visual features, OTTER selectively extracts and passes only task-relevant visual features that are semantically aligned with the language instruction to the policy transformer. This allows OTTER to keep the pre-trained vision-language encoders frozen. Thereby, OTTER preserves and utilizes the rich semantic understanding learned from large-scale pre-training, enabling strong zero-shot generalization capabilities. In simulation and real-world experiments, OTTER significantly outperforms existing VLA models, demonstrating strong zeroshot generalization to novel objects and environments. Video, code, checkpoints, and dataset: https://ottervla.github.io/.
ExBody2: Advanced Expressive Humanoid Whole-Body Control
Dec 17, 2024This paper enables real-world humanoid robots to maintain stability while performing expressive motions like humans do. We propose ExBody2, a generalized whole-body tracking framework that can take any reference motion inputs and control the humanoid to mimic the motion. The model is trained in simulation with Reinforcement Learning and then transferred to the real world. It decouples keypoint tracking with velocity control, and effectively leverages a privileged teacher policy to distill precise mimic skills into the target student policy, which enables high-fidelity replication of dynamic movements such as running, crouching, dancing, and other challenging motions. We present a comprehensive qualitative and quantitative analysis of crucial design factors in the paper. We conduct our experiments on two humanoid platforms and demonstrate the superiority of our approach against state-of-the-arts, providing practical guidelines to pursue the extreme of whole-body control for humanoid robots.
In-Context Imitation Learning via Next-Token Prediction
Aug 28, 2024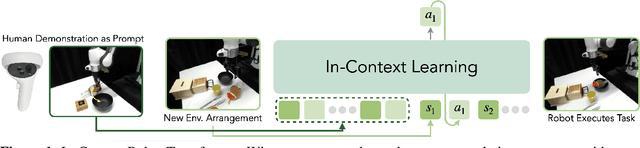
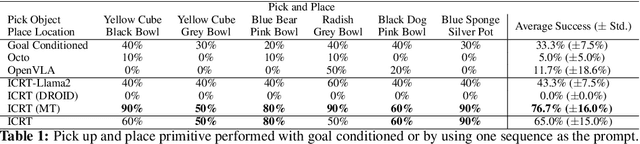
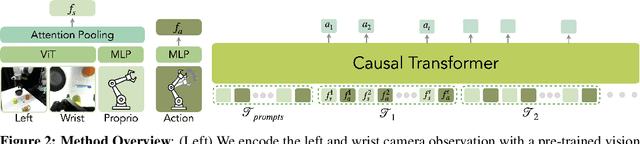
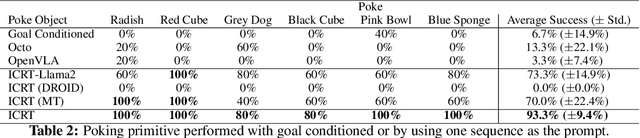
We explore how to enhance next-token prediction models to perform in-context imitation learning on a real robot, where the robot executes new tasks by interpreting contextual information provided during the input phase, without updating its underlying policy parameters. We propose In-Context Robot Transformer (ICRT), a causal transformer that performs autoregressive prediction on sensorimotor trajectories without relying on any linguistic data or reward function. This formulation enables flexible and training-free execution of new tasks at test time, achieved by prompting the model with sensorimotor trajectories of the new task composing of image observations, actions and states tuples, collected through human teleoperation. Experiments with a Franka Emika robot demonstrate that the ICRT can adapt to new tasks specified by prompts, even in environment configurations that differ from both the prompt and the training data. In a multitask environment setup, ICRT significantly outperforms current state-of-the-art next-token prediction models in robotics on generalizing to unseen tasks. Code, checkpoints and data are available on https://icrt.dev/
Body Transformer: Leveraging Robot Embodiment for Policy Learning
Aug 12, 2024



In recent years, the transformer architecture has become the de facto standard for machine learning algorithms applied to natural language processing and computer vision. Despite notable evidence of successful deployment of this architecture in the context of robot learning, we claim that vanilla transformers do not fully exploit the structure of the robot learning problem. Therefore, we propose Body Transformer (BoT), an architecture that leverages the robot embodiment by providing an inductive bias that guides the learning process. We represent the robot body as a graph of sensors and actuators, and rely on masked attention to pool information throughout the architecture. The resulting architecture outperforms the vanilla transformer, as well as the classical multilayer perceptron, in terms of task completion, scaling properties, and computational efficiency when representing either imitation or reinforcement learning policies. Additional material including the open-source code is available at https://sferrazza.cc/bot_site.
MOKA: Open-Vocabulary Robotic Manipulation through Mark-Based Visual Prompting
Mar 05, 2024Open-vocabulary generalization requires robotic systems to perform tasks involving complex and diverse environments and task goals. While the recent advances in vision language models (VLMs) present unprecedented opportunities to solve unseen problems, how to utilize their emergent capabilities to control robots in the physical world remains an open question. In this paper, we present MOKA (Marking Open-vocabulary Keypoint Affordances), an approach that employs VLMs to solve robotic manipulation tasks specified by free-form language descriptions. At the heart of our approach is a compact point-based representation of affordance and motion that bridges the VLM's predictions on RGB images and the robot's motions in the physical world. By prompting a VLM pre-trained on Internet-scale data, our approach predicts the affordances and generates the corresponding motions by leveraging the concept understanding and commonsense knowledge from broad sources. To scaffold the VLM's reasoning in zero-shot, we propose a visual prompting technique that annotates marks on the images, converting the prediction of keypoints and waypoints into a series of visual question answering problems that are feasible for the VLM to solve. Using the robot experiences collected in this way, we further investigate ways to bootstrap the performance through in-context learning and policy distillation. We evaluate and analyze MOKA's performance on a variety of manipulation tasks specified by free-form language descriptions, such as tool use, deformable body manipulation, and object rearrangement.
FMB: a Functional Manipulation Benchmark for Generalizable Robotic Learning
Jan 16, 2024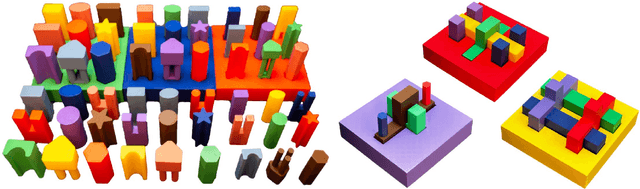


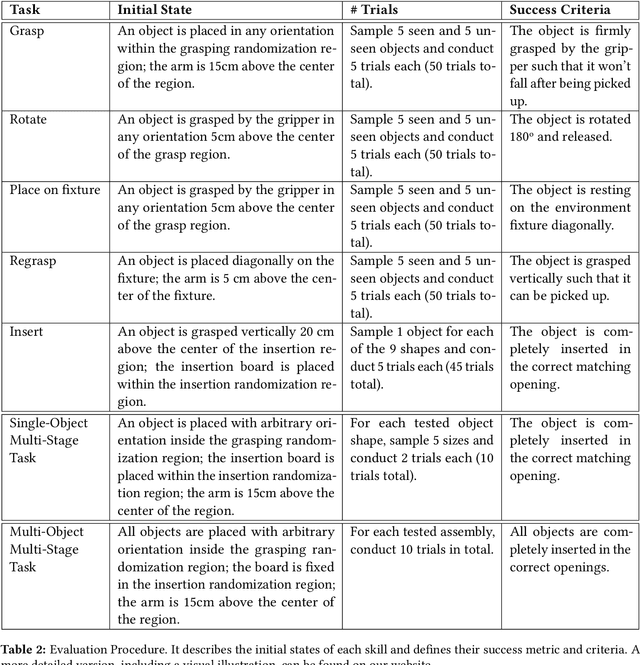
In this paper, we propose a real-world benchmark for studying robotic learning in the context of functional manipulation: a robot needs to accomplish complex long-horizon behaviors by composing individual manipulation skills in functionally relevant ways. The core design principles of our Functional Manipulation Benchmark (FMB) emphasize a harmonious balance between complexity and accessibility. Tasks are deliberately scoped to be narrow, ensuring that models and datasets of manageable scale can be utilized effectively to track progress. Simultaneously, they are diverse enough to pose a significant generalization challenge. Furthermore, the benchmark is designed to be easily replicable, encompassing all essential hardware and software components. To achieve this goal, FMB consists of a variety of 3D-printed objects designed for easy and accurate replication by other researchers. The objects are procedurally generated, providing a principled framework to study generalization in a controlled fashion. We focus on fundamental manipulation skills, including grasping, repositioning, and a range of assembly behaviors. The FMB can be used to evaluate methods for acquiring individual skills, as well as methods for combining and ordering such skills to solve complex, multi-stage manipulation tasks. We also offer an imitation learning framework that includes a suite of policies trained to solve the proposed tasks. This enables researchers to utilize our tasks as a versatile toolkit for examining various parts of the pipeline. For example, researchers could propose a better design for a grasping controller and evaluate it in combination with our baseline reorientation and assembly policies as part of a pipeline for solving multi-stage tasks. Our dataset, object CAD files, code, and evaluation videos can be found on our project website: https://functional-manipulation-benchmark.github.io
SpawnNet: Learning Generalizable Visuomotor Skills from Pre-trained Networks
Jul 07, 2023



The existing internet-scale image and video datasets cover a wide range of everyday objects and tasks, bringing the potential of learning policies that have broad generalization. Prior works have explored visual pre-training with different self-supervised objectives, but the generalization capabilities of the learned policies remain relatively unknown. In this work, we take the first step towards this challenge, focusing on how pre-trained representations can help the generalization of the learned policies. We first identify the key bottleneck in using a frozen pre-trained visual backbone for policy learning. We then propose SpawnNet, a novel two-stream architecture that learns to fuse pre-trained multi-layer representations into a separate network to learn a robust policy. Through extensive simulated and real experiments, we demonstrate significantly better categorical generalization compared to prior approaches in imitation learning settings.