 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArgRE: Formal Argumentation for Conflict Resolution in Multi-Agent Requirements Negotiation
Apr 25, 2026As software systems grow in complexity, they must satisfy an increasing number of competing quality attributes, making it essential to balance them in a principled manner -- for example, a safety requirement for sensor-fusion verification may conflict with a tight planning-cycle budget. Multi-agent large language model frameworks support this balancing process by assigning specialized agents to different objectives. However, their conflict resolution is typically heuristic. Requirements are aggregated implicitly without explicit acceptance or rejection, limiting auditability in regulated domains. We present ArgRE, a multi-agent requirements negotiation system that embeds Dung-style abstract argumentation into the negotiation stage. Each proposal, critique, and refinement is modeled as an argument, conflicts are represented as directed attack relations, and the accepted set of arguments is computed under grounded and preferred semantics. The pipeline further integrates KAOS goal modeling, multi-layer verification, and standards-oriented artifact generation. Evaluation across five case studies spanning safety-critical, financial, and information-system domains shows that ArgRE provides argument-level traceability absent from existing frameworks. Independent evaluators rated its decision justifications significantly higher than those of heuristic synthesis (4.32 vs. 3.07, p < 0.001), indicating improved auditability, while semantic intent preservation remains comparable (94.9% BERTScore F1) and compliance coverage reaches 84.7% versus 47.6%--47.8% for baselines. Structural analysis further confirms that the default pairwise protocol yields acyclic graphs in which grounded and preferred semantics coincide, whereas cross-pair arbitration introduces controlled cyclicity, leading to predictable divergence between the two semantics.
Robust Exploration in Directed Controller Synthesis via Reinforcement Learning with Soft Mixture-of-Experts
Feb 22, 2026On-the-fly Directed Controller Synthesis (OTF-DCS) mitigates state-space explosion by incrementally exploring the system and relies critically on an exploration policy to guide search efficiently. Recent reinforcement learning (RL) approaches learn such policies and achieve promising zero-shot generalization from small training instances to larger unseen ones. However, a fundamental limitation is anisotropic generalization, where an RL policy exhibits strong performance only in a specific region of the domain-parameter space while remaining fragile elsewhere due to training stochasticity and trajectory-dependent bias. To address this, we propose a Soft Mixture-of-Experts framework that combines multiple RL experts via a prior-confidence gating mechanism and treats these anisotropic behaviors as complementary specializations. The evaluation on the Air Traffic benchmark shows that Soft-MoE substantially expands the solvable parameter space and improves robustness compared to any single expert.
Statistical MIA: Rethinking Membership Inference Attack for Reliable Unlearning Auditing
Feb 01, 2026Machine unlearning (MU) is essential for enforcing the right to be forgotten in machine learning systems. A key challenge of MU is how to reliably audit whether a model has truly forgotten specified training data. Membership Inference Attacks (MIAs) are widely used for unlearning auditing, where samples that evade membership detection are often regarded as successfully forgotten. After carefully revisiting the reliability of MIA, we show that this assumption is flawed: failed membership inference does not imply true forgetting. We theoretically demonstrate that MIA-based auditing, when formulated as a binary classification problem, inevitably incurs statistical errors whose magnitude cannot be observed during the auditing process. This leads to overly optimistic evaluations of unlearning performance, while incurring substantial computational overhead due to shadow model training. To address these limitations, we propose Statistical Membership Inference Attack (SMIA), a novel training-free and highly effective auditing framework. SMIA directly compares the distributions of member and non-member data using statistical tests, eliminating the need for learned attack models. Moreover, SMIA outputs both a forgetting rate and a corresponding confidence interval, enabling quantified reliability of the auditing results. Extensive experiments show that SMIA provides more reliable auditing with significantly lower computational cost than existing MIA-based approaches. Notably, the theoretical guarantees and empirical effectiveness of SMIA suggest it as a new paradigm for reliable machine unlearning auditing.
Quest2ROS2: A ROS 2 Framework for Bi-manual VR Teleoperation
Jan 26, 2026Quest2ROS2 is an open-source ROS2 framework for bi-manual teleoperation designed to scale robot data collection. Extending Quest2ROS, it overcomes workspace limitations via relative motion-based control, calculating robot movement from VR controller pose changes to enable intuitive, pose-independent operation. The framework integrates essential usability and safety features, including real-time RViz visualization, streamlined gripper control, and a pause-and-reset function for smooth transitions. We detail a modular architecture that supports "Side-by-Side" and "Mirror" control modes to optimize operator experience across diverse platforms. Code is available at: https://github.com/Taokt/Quest2ROS2.
FAROS: Robust Federated Learning with Adaptive Scaling against Backdoor Attacks
Jan 05, 2026Federated Learning (FL) enables multiple clients to collaboratively train a shared model without exposing local data. However, backdoor attacks pose a significant threat to FL. These attacks aim to implant a stealthy trigger into the global model, causing it to mislead on inputs that possess a specific trigger while functioning normally on benign data. Although pre-aggregation detection is a main defense direction, existing state-of-the-art defenses often rely on fixed defense parameters. This reliance makes them vulnerable to single-point-of-failure risks, rendering them less effective against sophisticated attackers. To address these limitations, we propose FAROS, an enhanced FL framework that incorporates Adaptive Differential Scaling (ADS) and Robust Core-set Computing (RCC). The ADS mechanism adjusts the defense's sensitivity dynamically, based on the dispersion of uploaded gradients by clients in each round. This allows it to counter attackers who strategically shift between stealthiness and effectiveness. Furthermore, the RCC effectively mitigates the risk of single-point failure by computing the centroid of a core set comprising clients with the highest confidence. We conducted extensive experiments across various datasets, models, and attack scenarios. The results demonstrate that our method outperforms current defenses in both attack success rate and main task accuracy.
Graph Contextual Reinforcement Learning for Efficient Directed Controller Synthesis
Dec 17, 2025Controller synthesis is a formal method approach for automatically generating Labeled Transition System (LTS) controllers that satisfy specified properties. The efficiency of the synthesis process, however, is critically dependent on exploration policies. These policies often rely on fixed rules or strategies learned through reinforcement learning (RL) that consider only a limited set of current features. To address this limitation, this paper introduces GCRL, an approach that enhances RL-based methods by integrating Graph Neural Networks (GNNs). GCRL encodes the history of LTS exploration into a graph structure, allowing it to capture a broader, non-current-based context. In a comparative experiment against state-of-the-art methods, GCRL exhibited superior learning efficiency and generalization across four out of five benchmark domains, except one particular domain characterized by high symmetry and strictly local interactions.
Synergizing Code Coverage and Gameplay Intent: Coverage-Aware Game Playtesting with LLM-Guided Reinforcement Learning
Dec 14, 2025The widespread adoption of the "Games as a Service" model necessitates frequent content updates, placing immense pressure on quality assurance. In response, automated game testing has been viewed as a promising solution to cope with this demanding release cadence. However, existing automated testing approaches typically create a dichotomy: code-centric methods focus on structural coverage without understanding gameplay context, while player-centric agents validate high-level intent but often fail to cover specific underlying code changes. To bridge this gap, we propose SMART (Structural Mapping for Augmented Reinforcement Testing), a novel framework that synergizes structural verification and functional validation for game update testing. SMART leverages large language models (LLMs) to interpret abstract syntax tree (AST) differences and extract functional intent, constructing a context-aware hybrid reward mechanism. This mechanism guides reinforcement learning agents to sequentially fulfill gameplay goals while adaptively exploring modified code branches. We evaluate SMART on two environments, Overcooked and Minecraft. The results demonstrate that SMART significantly outperforms state-of-the-art baselines; it achieves over 94% branch coverage of modified code, nearly double that of traditional reinforcement learning methods, while maintaining a 98% task completion rate, effectively balancing structural comprehensiveness with functional correctness.
FedLAD: A Modular and Adaptive Testbed for Federated Log Anomaly Detection
Dec 09, 2025Log-based anomaly detection (LAD) is critical for ensuring the reliability of large-scale distributed systems. However, most existing LAD approaches assume centralized training, which is often impractical due to privacy constraints and the decentralized nature of system logs. While federated learning (FL) offers a promising alternative, there is a lack of dedicated testbeds tailored to the needs of LAD in federated settings. To address this, we present FedLAD, a unified platform for training and evaluating LAD models under FL constraints. FedLAD supports plug-and-play integration of diverse LAD models, benchmark datasets, and aggregation strategies, while offering runtime support for validation logging (self-monitoring), parameter tuning (self-configuration), and adaptive strategy control (self-adaptation). By enabling reproducible and scalable experimentation, FedLAD bridges the gap between FL frameworks and LAD requirements, providing a solid foundation for future research. Project code is publicly available at: https://github.com/AA-cityu/FedLAD.
PLATONT: Learning a Platonic Representation for Unified Network Tomography
Nov 19, 2025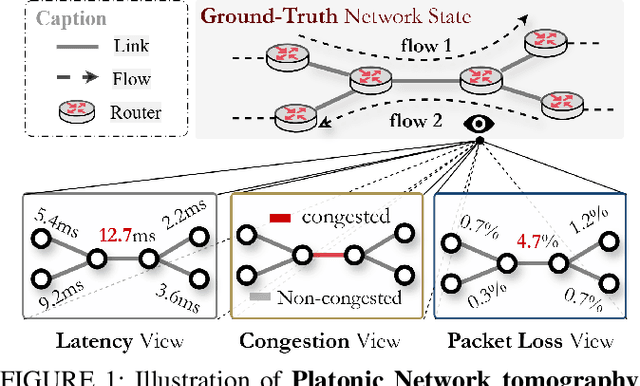
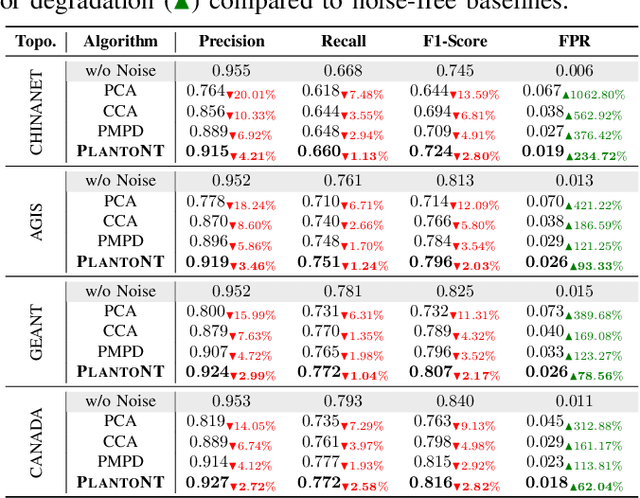
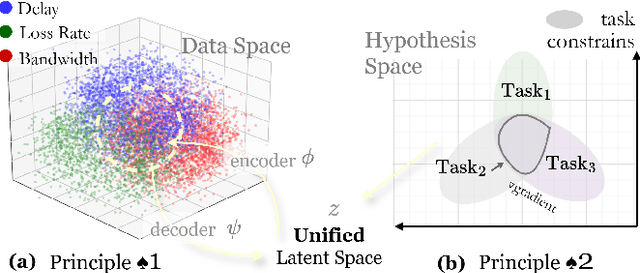
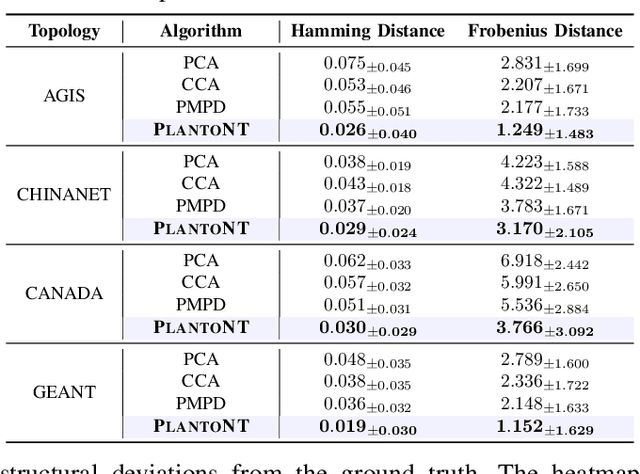
Network tomography aims to infer hidden network states, such as link performance, traffic load, and topology, from external observations. Most existing methods solve these problems separately and depend on limited task-specific signals, which limits generalization and interpretability. We present PLATONT, a unified framework that models different network indicators (e.g., delay, loss, bandwidth) as projections of a shared latent network state. Guided by the Platonic Representation Hypothesis, PLATONT learns this latent state through multimodal alignment and contrastive learning. By training multiple tomography tasks within a shared latent space, it builds compact and structured representations that improve cross-task generalization. Experiments on synthetic and real-world datasets show that PLATONT consistently outperforms existing methods in link estimation, topology inference, and traffic prediction, achieving higher accuracy and stronger robustness under varying network conditions.
AMO: Adaptive Motion Optimization for Hyper-Dexterous Humanoid Whole-Body Control
May 06, 2025Humanoid robots derive much of their dexterity from hyper-dexterous whole-body movements, enabling tasks that require a large operational workspace: such as picking objects off the ground. However, achieving these capabilities on real humanoids remains challenging due to their high degrees of freedom (DoF) and nonlinear dynamics. We propose Adaptive Motion Optimization (AMO), a framework that integrates sim-to-real reinforcement learning (RL) with trajectory optimization for real-time, adaptive whole-body control. To mitigate distribution bias in motion imitation RL, we construct a hybrid AMO dataset and train a network capable of robust, on-demand adaptation to potentially O.O.D. commands. We validate AMO in simulation and on a 29-DoF Unitree G1 humanoid robot, demonstrating superior stability and an expanded workspace compared to strong baselines. Finally, we show that AMO's consistent performance supports autonomous task execution via imitation learning, underscoring the system's versatility and robustness.