 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLOW: Graph-Language Co-Reasoning for Agentic Workflow Performance Prediction
Dec 11, 2025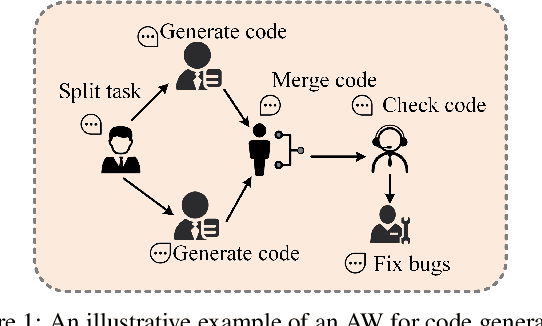



Agentic Workflows (AWs) have emerged as a promising paradigm for solving complex tasks. However, the scalability of automating their generation is severely constrained by the high cost and latency of execution-based evaluation. Existing AW performance prediction methods act as surrogates but fail to simultaneously capture the intricate topological dependencies and the deep semantic logic embedded in AWs. To address this limitation, we propose GLOW, a unified framework for AW performance prediction that combines the graph-structure modeling capabilities of GNNs with the reasoning power of LLMs. Specifically, we introduce a graph-oriented LLM, instruction-tuned on graph tasks, to extract topologically aware semantic features, which are fused with GNN-encoded structural representations. A contrastive alignment strategy further refines the latent space to distinguish high-quality AWs. Extensive experiments on FLORA-Bench show that GLOW outperforms state-of-the-art baselines in prediction accuracy and ranking utility.
More Than One Teacher: Adaptive Multi-Guidance Policy Optimization for Diverse Exploration
Oct 02, 2025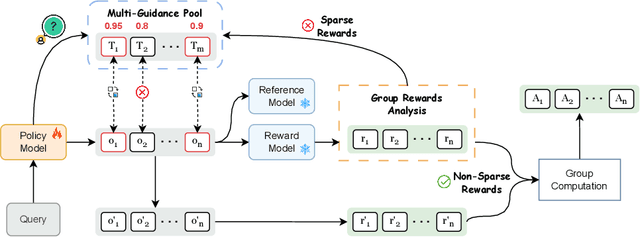
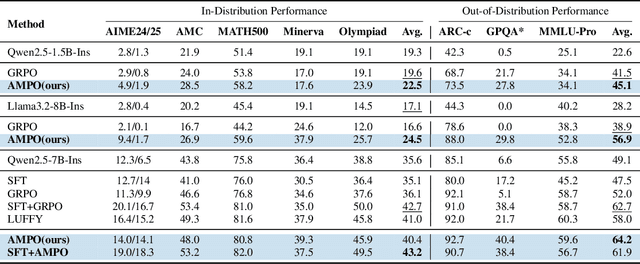

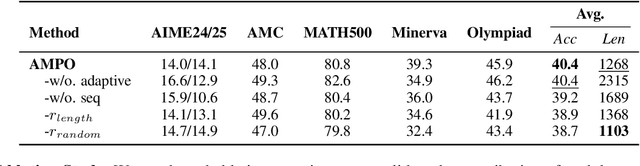
Reinforcement Learning with Verifiable Rewards (RLVR) is a promising paradigm for enhancing the reasoning ability in Large Language Models (LLMs). However, prevailing methods primarily rely on self-exploration or a single off-policy teacher to elicit long chain-of-thought (LongCoT) reasoning, which may introduce intrinsic model biases and restrict exploration, ultimately limiting reasoning diversity and performance. Drawing inspiration from multi-teacher strategies in knowledge distillation, we introduce Adaptive Multi-Guidance Policy Optimization (AMPO), a novel framework that adaptively leverages guidance from multiple proficient teacher models, but only when the on-policy model fails to generate correct solutions. This "guidance-on-demand" approach expands exploration while preserving the value of self-discovery. Moreover, AMPO incorporates a comprehension-based selection mechanism, prompting the student to learn from the reasoning paths that it is most likely to comprehend, thus balancing broad exploration with effective exploitation. Extensive experiments show AMPO substantially outperforms a strong baseline (GRPO), with a 4.3% improvement on mathematical reasoning tasks and 12.2% on out-of-distribution tasks, while significantly boosting Pass@k performance and enabling more diverse exploration. Notably, using four peer-sized teachers, our method achieves comparable results to approaches that leverage a single, more powerful teacher (e.g., DeepSeek-R1) with more data. These results demonstrate a more efficient and scalable path to superior reasoning and generalizability. Our code is available at https://github.com/SII-Enigma/AMPO.
WereWolf-Plus: An Update of Werewolf Game setting Based on DSGBench
Jun 15, 2025With the rapid development of LLM-based agents, increasing attention has been given to their social interaction and strategic reasoning capabilities. However, existing Werewolf-based benchmarking platforms suffer from overly simplified game settings, incomplete evaluation metrics, and poor scalability. To address these limitations, we propose WereWolf-Plus, a multi-model, multi-dimensional, and multi-method benchmarking platform for evaluating multi-agent strategic reasoning in the Werewolf game. The platform offers strong extensibility, supporting customizable configurations for roles such as Seer, Witch, Hunter, Guard, and Sheriff, along with flexible model assignment and reasoning enhancement strategies for different roles. In addition, we introduce a comprehensive set of quantitative evaluation metrics for all special roles, werewolves, and the sheriff, and enrich the assessment dimensions for agent reasoning ability, cooperation capacity, and social influence. WereWolf-Plus provides a more flexible and reliable environment for advancing research on inference and strategic interaction within multi-agent communities. Our code is open sourced at https://github.com/MinstrelsyXia/WereWolfPlus.
Simulation of Language Evolution under Regulated Social Media Platforms: A Synergistic Approach of Large Language Models and Genetic Algorithms
Feb 26, 2025Social media platforms frequently impose restrictive policies to moderate user content, prompting the emergence of creative evasion language strategies. This paper presents a multi-agent framework based on Large Language Models (LLMs) to simulate the iterative evolution of language strategies under regulatory constraints. In this framework, participant agents, as social media users, continuously evolve their language expression, while supervisory agents emulate platform-level regulation by assessing policy violations. To achieve a more faithful simulation, we employ a dual design of language strategies (constraint and expression) to differentiate conflicting goals and utilize an LLM-driven GA (Genetic Algorithm) for the selection, mutation, and crossover of language strategies. The framework is evaluated using two distinct scenarios: an abstract password game and a realistic simulated illegal pet trade scenario. Experimental results demonstrate that as the number of dialogue rounds increases, both the number of uninterrupted dialogue turns and the accuracy of information transmission improve significantly. Furthermore, a user study with 40 participants validates the real-world relevance of the generated dialogues and strategies. Moreover, ablation studies validate the importance of the GA, emphasizing its contribution to long-term adaptability and improved overall results.
Automatic Adaptation Rule Optimization via Large Language Models
Jul 02, 2024Rule-based adaptation is a foundational approach to self-adaptation, characterized by its human readability and rapid response. However, building high-performance and robust adaptation rules is often a challenge because it essentially involves searching the optimal design in a complex (variables) space. In response, this paper attempt to employ large language models (LLMs) as a optimizer to construct and optimize adaptation rules, leveraging the common sense and reasoning capabilities inherent in LLMs. Preliminary experiments conducted in SWIM have validated the effectiveness and limitation of our method.
Exploring the Improvement of Evolutionary Computation via Large Language Models
May 05, 2024Evolutionary computation (EC), as a powerful optimization algorithm, has been applied across various domains. However, as the complexity of problems increases, the limitations of EC have become more apparent. The advent of large language models (LLMs) has not only transformed natural language processing but also extended their capabilities to diverse fields. By harnessing LLMs' vast knowledge and adaptive capabilities, we provide a forward-looking overview of potential improvements LLMs can bring to EC, focusing on the algorithms themselves, population design, and additional enhancements. This presents a promising direction for future research at the intersection of LLMs and EC.
Language Evolution for Evading Social Media Regulation via LLM-based Multi-agent Simulation
May 05, 2024



Social media platforms such as Twitter, Reddit, and Sina Weibo play a crucial role in global communication but often encounter strict regulations in geopolitically sensitive regions. This situation has prompted users to ingeniously modify their way of communicating, frequently resorting to coded language in these regulated social media environments. This shift in communication is not merely a strategy to counteract regulation, but a vivid manifestation of language evolution, demonstrating how language naturally evolves under societal and technological pressures. Studying the evolution of language in regulated social media contexts is of significant importance for ensuring freedom of speech, optimizing content moderation, and advancing linguistic research. This paper proposes a multi-agent simulation framework using Large Language Models (LLMs) to explore the evolution of user language in regulated social media environments. The framework employs LLM-driven agents: supervisory agent who enforce dialogue supervision and participant agents who evolve their language strategies while engaging in conversation, simulating the evolution of communication styles under strict regulations aimed at evading social media regulation. The study evaluates the framework's effectiveness through a range of scenarios from abstract scenarios to real-world situations. Key findings indicate that LLMs are capable of simulating nuanced language dynamics and interactions in constrained settings, showing improvement in both evading supervision and information accuracy as evolution progresses. Furthermore, it was found that LLM agents adopt different strategies for different scenarios.
FGAD: Self-boosted Knowledge Distillation for An Effective Federated Graph Anomaly Detection Framework
Feb 20, 2024Graph anomaly detection (GAD) aims to identify anomalous graphs that significantly deviate from other ones, which has raised growing attention due to the broad existence and complexity of graph-structured data in many real-world scenarios. However, existing GAD methods usually execute with centralized training, which may lead to privacy leakage risk in some sensitive cases, thereby impeding collaboration among organizations seeking to collectively develop robust GAD models. Although federated learning offers a promising solution, the prevalent non-IID problems and high communication costs present significant challenges, particularly pronounced in collaborations with graph data distributed among different participants. To tackle these challenges, we propose an effective federated graph anomaly detection framework (FGAD). We first introduce an anomaly generator to perturb the normal graphs to be anomalous, and train a powerful anomaly detector by distinguishing generated anomalous graphs from normal ones. Then, we leverage a student model to distill knowledge from the trained anomaly detector (teacher model), which aims to maintain the personality of local models and alleviate the adverse impact of non-IID problems. Moreover, we design an effective collaborative learning mechanism that facilitates the personalization preservation of local models and significantly reduces communication costs among clients. Empirical results of the GAD tasks on non-IID graphs compared with state-of-the-art baselines demonstrate the superiority and efficiency of the proposed FGAD method.
Multi: Multimodal Understanding Leaderboard with Text and Images
Feb 05, 2024
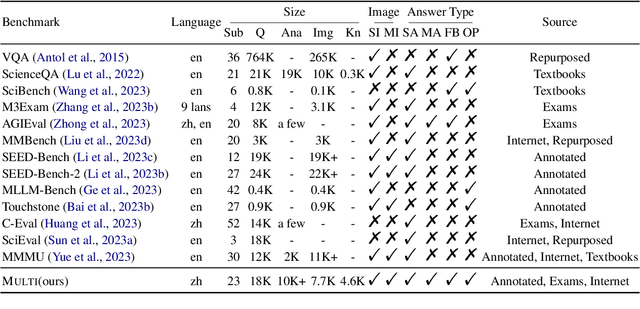
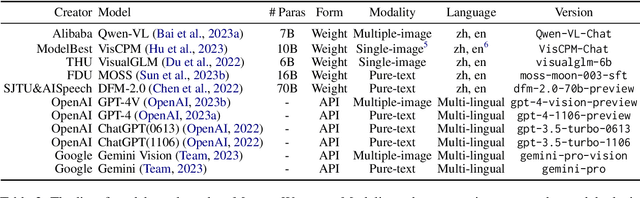

Rapid progress in multimodal large language models (MLLMs) highlights the need to introduce challenging yet realistic benchmarks to the academic community. Existing benchmarks primarily focus on simple natural image understanding, but Multi emerges as a cutting-edge benchmark for MLLMs, offering a comprehensive dataset for evaluating MLLMs against understanding complex figures and tables, and scientific questions. This benchmark, reflecting current realistic examination styles, provides multimodal inputs and requires responses that are either precise or open-ended, similar to real-life school tests. It challenges MLLMs with a variety of tasks, ranging from formula derivation to image detail analysis, and cross-modality reasoning. Multi includes over 18,000 questions, with a focus on science-based QA in diverse formats. We also introduce Multi-Elite, a 500-question subset for testing the extremities of MLLMs, and Multi-Extend, which enhances In-Context Learning research with more than 4,500 knowledge pieces. Our evaluation indicates significant potential for MLLM advancement, with GPT-4V achieving a 63.7% accuracy rate on Multi, in contrast to other MLLMs scoring between 31.3% and 53.7%. Multi serves not only as a robust evaluation platform but also paves the way for the development of expert-level AI.
Self-Discriminative Modeling for Anomalous Graph Detection
Oct 10, 2023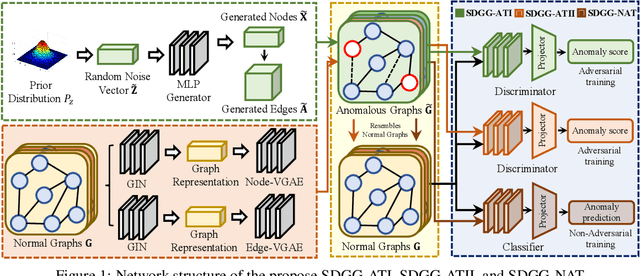
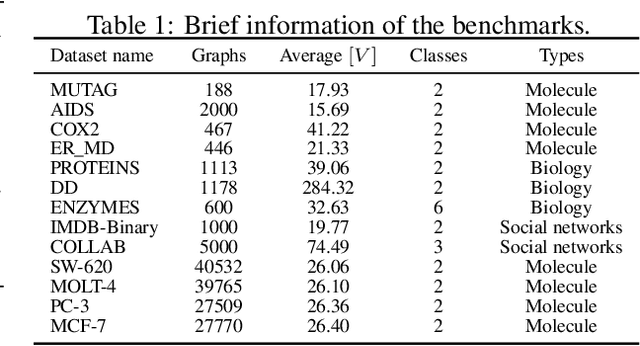
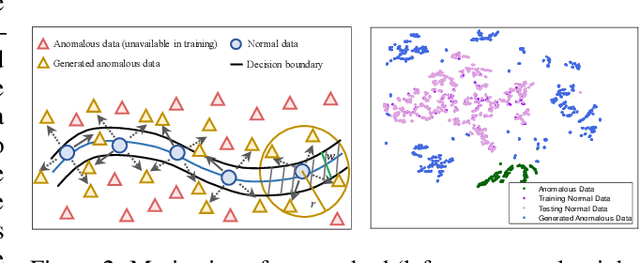
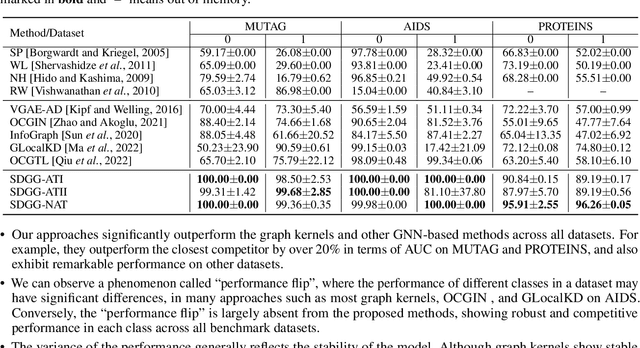
This paper studies the problem of detecting anomalous graphs using a machine learning model trained on only normal graphs, which has many applications in molecule, biology, and social network data analysis. We present a self-discriminative modeling framework for anomalous graph detection. The key idea, mathematically and numerically illustrated, is to learn a discriminator (classifier) from the given normal graphs together with pseudo-anomalous graphs generated by a model jointly trained, where we never use any true anomalous graphs and we hope that the generated pseudo-anomalous graphs interpolate between normal ones and (real) anomalous ones. Under the framework, we provide three algorithms with different computational efficiencies and stabilities for anomalous graph detection. The three algorithms are compared with several state-of-the-art graph-level anomaly detection baselines on nine popular graph datasets (four with small size and five with moderate size) and show significant improvement in terms of AUC. The success of our algorithms stems from the integration of the discriminative classifier and the well-posed pseudo-anomalous graphs, which provide new insights for anomaly detection. Moreover, we investigate our algorithms for large-scale imbalanced graph datasets. Surprisingly, our algorithms, though fully unsupervised, are able to significantly outperform supervised learning algorithms of anomalous graph detection. The corresponding reason is also analyzed.