 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Reinforcement learning in 3-Dimensional Hydrophobic-Polar Protein Folding Model with Attention-based layers
Apr 22, 2025Transformer-based architectures have recently propelled advances in sequence modeling across domains, but their application to the hydrophobic-hydrophilic (H-P) model for protein folding remains relatively unexplored. In this work, we adapt a Deep Q-Network (DQN) integrated with attention mechanisms (Transformers) to address the 3D H-P protein folding problem. Our system formulates folding decisions as a self-avoiding walk in a reinforced environment, and employs a specialized reward function based on favorable hydrophobic interactions. To improve performance, the method incorporates validity check including symmetry-breaking constraints, dueling and double Q-learning, and prioritized replay to focus learning on critical transitions. Experimental evaluations on standard benchmark sequences demonstrate that our approach achieves several known best solutions for shorter sequences, and obtains near-optimal results for longer chains. This study underscores the promise of attention-based reinforcement learning for protein folding, and created a prototype of Transformer-based Q-network structure for 3-dimensional lattice models.
Large Language Models as Particle Swarm Optimizers
Apr 12, 2025Optimization problems often require domain-specific expertise to design problem-dependent methodologies. Recently, several approaches have gained attention by integrating large language models (LLMs) into genetic algorithms. Building on this trend, we introduce Language Model Particle Swarm Optimization (LMPSO), a novel method that incorporates an LLM into the swarm intelligence framework of Particle Swarm Optimization (PSO). In LMPSO, the velocity of each particle is represented as a prompt that generates the next candidate solution, leveraging the capabilities of an LLM to produce solutions in accordance with the PSO paradigm. This integration enables an LLM-driven search process that adheres to the foundational principles of PSO. The proposed LMPSO approach is evaluated across multiple problem domains, including the Traveling Salesman Problem (TSP), heuristic improvement for TSP, and symbolic regression. These problems are traditionally challenging for standard PSO due to the structured nature of their solutions. Experimental results demonstrate that LMPSO is particularly effective for solving problems where solutions are represented as structured sequences, such as mathematical expressions or programmatic constructs. By incorporating LLMs into the PSO framework, LMPSO establishes a new direction in swarm intelligence research. This method not only broadens the applicability of PSO to previously intractable problems but also showcases the potential of LLMs in addressing complex optimization challenges.
Automatic Adaptation Rule Optimization via Large Language Models
Jul 02, 2024Rule-based adaptation is a foundational approach to self-adaptation, characterized by its human readability and rapid response. However, building high-performance and robust adaptation rules is often a challenge because it essentially involves searching the optimal design in a complex (variables) space. In response, this paper attempt to employ large language models (LLMs) as a optimizer to construct and optimize adaptation rules, leveraging the common sense and reasoning capabilities inherent in LLMs. Preliminary experiments conducted in SWIM have validated the effectiveness and limitation of our method.
Large Language Models Synergize with Automated Machine Learning
May 06, 2024Recently, code generation driven by large language models (LLMs) has become increasingly popular. However, automatically generating code for machine learning (ML) tasks still poses significant challenges. This paper explores the limits of program synthesis for ML by combining LLMs and automated machine learning (autoML). Specifically, our goal is to fully automate the code generation process for the entire ML workflow, from data preparation to modeling and post-processing, utilizing only textual descriptions of the ML tasks. To manage the length and diversity of ML programs, we propose to break each ML program into smaller, manageable parts. Each part is generated separately by the LLM, with careful consideration of their compatibilities. To implement the approach, we design a testing technique for ML programs. Furthermore, our approach enables integration with autoML. In our approach, autoML serves to numerically assess and optimize the ML programs generated by LLMs. LLMs, in turn, help to bridge the gap between theoretical, algorithm-centered autoML and practical autoML applications. This mutual enhancement underscores the synergy between LLMs and autoML in program synthesis for ML. In experiments across various ML tasks, our method outperforms existing methods in 10 out of 12 tasks for generating ML programs. In addition, autoML significantly improves the performance of the generated ML programs. In the experiments, our method, Text-to-ML, achieves fully automated synthesis of the entire ML pipeline based solely on textual descriptions of the ML tasks.
Exploring the Improvement of Evolutionary Computation via Large Language Models
May 05, 2024Evolutionary computation (EC), as a powerful optimization algorithm, has been applied across various domains. However, as the complexity of problems increases, the limitations of EC have become more apparent. The advent of large language models (LLMs) has not only transformed natural language processing but also extended their capabilities to diverse fields. By harnessing LLMs' vast knowledge and adaptive capabilities, we provide a forward-looking overview of potential improvements LLMs can bring to EC, focusing on the algorithms themselves, population design, and additional enhancements. This presents a promising direction for future research at the intersection of LLMs and EC.
Evolving Architectures with Gradient Misalignment toward Low Adversarial Transferability
Sep 13, 2021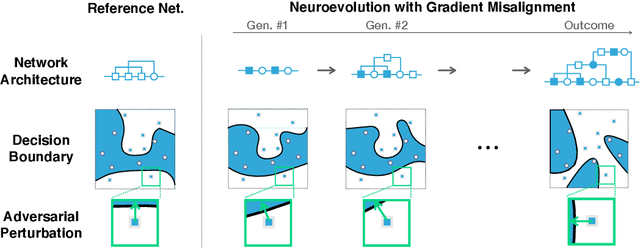

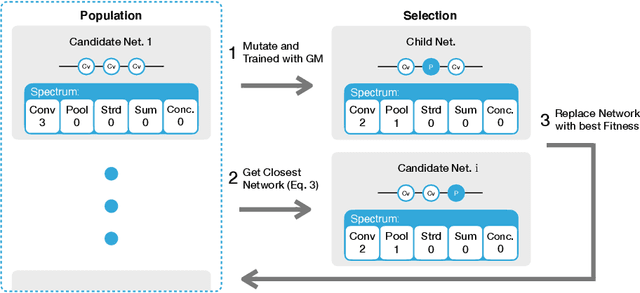
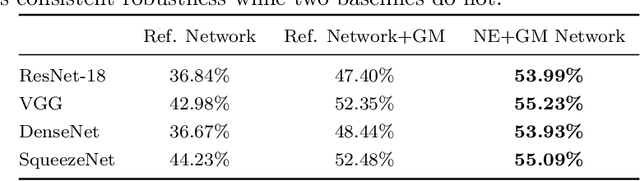
Deep neural network image classifiers are known to be susceptible not only to adversarial examples created for them but even those created for others. This phenomenon poses a potential security risk in various black-box systems relying on image classifiers. The reason behind such transferability of adversarial examples is not yet fully understood and many studies have proposed training methods to obtain classifiers with low transferability. In this study, we address this problem from a novel perspective through investigating the contribution of the network architecture to transferability. Specifically, we propose an architecture searching framework that employs neuroevolution to evolve network architectures and the gradient misalignment loss to encourage networks to converge into dissimilar functions after training. Our experiments show that the proposed framework successfully discovers architectures that reduce transferability from four standard networks including ResNet and VGG, while maintaining a good accuracy on unperturbed images. In addition, the evolved networks trained with gradient misalignment exhibit significantly lower transferability compared to standard networks trained with gradient misalignment, which indicates that the network architecture plays an important role in reducing transferability. This study demonstrates that designing or exploring proper network architectures is a promising approach to tackle the transferability issue and train adversarially robust image classifiers.
GP-RVM: Genetic Programing-based Symbolic Regression Using Relevance Vector Machine
Aug 26, 2018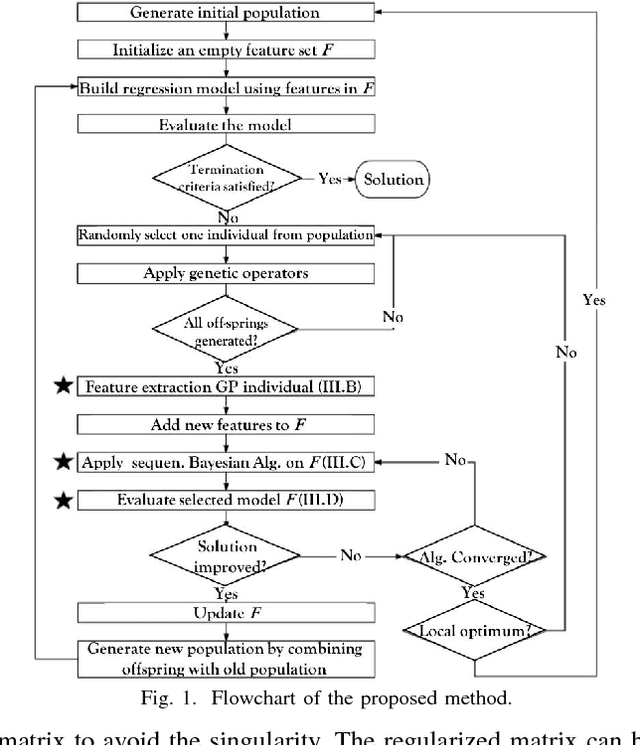
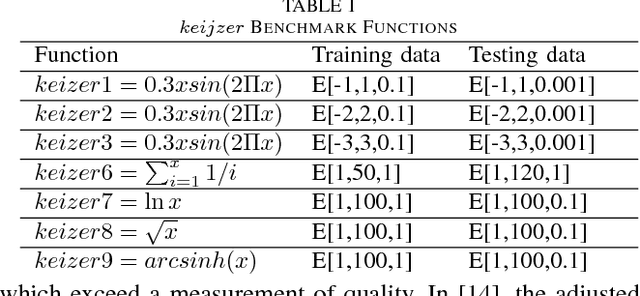
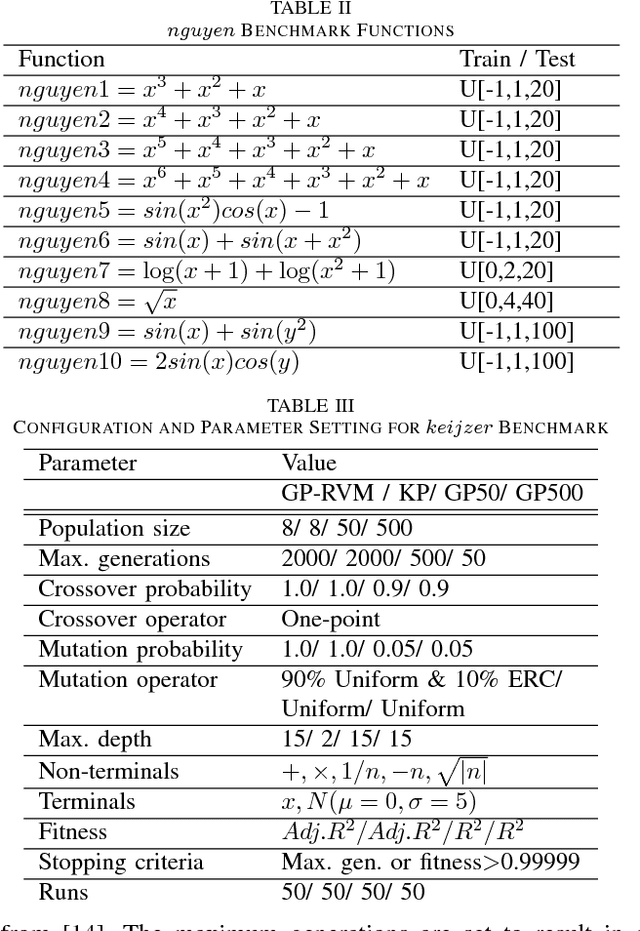

This paper proposes a hybrid basis function construction method (GP-RVM) for Symbolic Regression problem, which combines an extended version of Genetic Programming called Kaizen Programming and Relevance Vector Machine to evolve an optimal set of basis functions. Different from traditional evolutionary algorithms where a single individual is a complete solution, our method proposes a solution based on linear combination of basis functions built from individuals during the evolving process. RVM which is a sparse Bayesian kernel method selects suitable functions to constitute the basis. RVM determines the posterior weight of a function by evaluating its quality and sparsity. The solution produced by GP-RVM is a sparse Bayesian linear model of the coefficients of many non-linear functions. Our hybrid approach is focused on nonlinear white-box models selecting the right combination of functions to build robust predictions without prior knowledge about data. Experimental results show that GP-RVM outperforms conventional methods, which suggest that it is an efficient and accurate technique for solving SR. The computational complexity of GP-RVM scales in $O( M^{3})$, where $M$ is the number of functions in the basis set and is typically much smaller than the number $N$ of training patterns.