 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Textual Explanations via Translating Decision-Critical Features
Dec 08, 2025Textual explanations make image classifier decisions transparent by describing the prediction rationale in natural language. Large vision-language models can generate captions but are designed for general visual understanding, not classifier-specific reasoning. Existing zero-shot explanation methods align global image features with language, producing descriptions of what is visible rather than what drives the prediction. We propose TEXTER, which overcomes this limitation by isolating decision-critical features before alignment. TEXTER identifies the neurons contributing to the prediction and emphasizes the features encoded in those neurons -- i.e., the decision-critical features. It then maps these emphasized features into the CLIP feature space to retrieve textual explanations that reflect the model's reasoning. A sparse autoencoder further improves interpretability, particularly for Transformer architectures. Extensive experiments show that TEXTER generates more faithful and interpretable explanations than existing methods. The code will be publicly released.
CALT: A Library for Computer Algebra with Transformer
Jun 10, 2025Recent advances in artificial intelligence have demonstrated the learnability of symbolic computation through end-to-end deep learning. Given a sufficient number of examples of symbolic expressions before and after the target computation, Transformer models - highly effective learners of sequence-to-sequence functions - can be trained to emulate the computation. This development opens up several intriguing challenges and new research directions, which require active contributions from the symbolic computation community. In this work, we introduce Computer Algebra with Transformer (CALT), a user-friendly Python library designed to help non-experts in deep learning train models for symbolic computation tasks.
Computational Algebra with Attention: Transformer Oracles for Border Basis Algorithms
May 29, 2025Solving systems of polynomial equations, particularly those with finitely many solutions, is a crucial challenge across many scientific fields. Traditional methods like Gr\"obner and Border bases are fundamental but suffer from high computational costs, which have motivated recent Deep Learning approaches to improve efficiency, albeit at the expense of output correctness. In this work, we introduce the Oracle Border Basis Algorithm, the first Deep Learning approach that accelerates Border basis computation while maintaining output guarantees. To this end, we design and train a Transformer-based oracle that identifies and eliminates computationally expensive reduction steps, which we find to dominate the algorithm's runtime. By selectively invoking this oracle during critical phases of computation, we achieve substantial speedup factors of up to 3.5x compared to the base algorithm, without compromising the correctness of results. To generate the training data, we develop a sampling method and provide the first sampling theorem for border bases. We construct a tokenization and embedding scheme tailored to monomial-centered algebraic computations, resulting in a compact and expressive input representation, which reduces the number of tokens to encode an $n$-variate polynomial by a factor of $O(n)$. Our learning approach is data efficient, stable, and a practical enhancement to traditional computer algebra algorithms and symbolic computation.
Training on Plausible Counterfactuals Removes Spurious Correlations
May 22, 2025Plausible counterfactual explanations (p-CFEs) are perturbations that minimally modify inputs to change classifier decisions while remaining plausible under the data distribution. In this study, we demonstrate that classifiers can be trained on p-CFEs labeled with induced \emph{incorrect} target classes to classify unperturbed inputs with the original labels. While previous studies have shown that such learning is possible with adversarial perturbations, we extend this paradigm to p-CFEs. Interestingly, our experiments reveal that learning from p-CFEs is even more effective: the resulting classifiers achieve not only high in-distribution accuracy but also exhibit significantly reduced bias with respect to spurious correlations.
Adversarially Pretrained Transformers may be Universally Robust In-Context Learners
May 20, 2025Adversarial training is one of the most effective adversarial defenses, but it incurs a high computational cost. In this study, we show that transformers adversarially pretrained on diverse tasks can serve as robust foundation models and eliminate the need for adversarial training in downstream tasks. Specifically, we theoretically demonstrate that through in-context learning, a single adversarially pretrained transformer can robustly generalize to multiple unseen tasks without any additional training, i.e., without any parameter updates. This robustness stems from the model's focus on robust features and its resistance to attacks that exploit non-predictive features. Besides these positive findings, we also identify several limitations. Under certain conditions (though unrealistic), no universally robust single-layer transformers exist. Moreover, robust transformers exhibit an accuracy--robustness trade-off and require a large number of in-context demonstrations. The code is available at https://github.com/s-kumano/universally-robust-in-context-learner.
Adversarial Training from Mean Field Perspective
May 20, 2025Although adversarial training is known to be effective against adversarial examples, training dynamics are not well understood. In this study, we present the first theoretical analysis of adversarial training in random deep neural networks without any assumptions on data distributions. We introduce a new theoretical framework based on mean field theory, which addresses the limitations of existing mean field-based approaches. Based on this framework, we derive (empirically tight) upper bounds of $\ell_q$ norm-based adversarial loss with $\ell_p$ norm-based adversarial examples for various values of $p$ and $q$. Moreover, we prove that networks without shortcuts are generally not adversarially trainable and that adversarial training reduces network capacity. We also show that network width alleviates these issues. Furthermore, we present the various impacts of the input and output dimensions on the upper bounds and time evolution of the weight variance.
Cross-Model Transfer of Task Vectors via Few-Shot Orthogonal Alignment
May 17, 2025Task arithmetic enables efficient model editing by representing task-specific changes as vectors in parameter space. Task arithmetic typically assumes that the source and target models are initialized from the same pre-trained parameters. This assumption limits its applicability in cross-model transfer settings, where models are independently pre-trained on different datasets. To address this challenge, we propose a method based on few-shot orthogonal alignment, which aligns task vectors to the parameter space of a differently pre-trained target model. These transformations preserve key properties of task vectors, such as norm and rank, and are learned using only a small number of labeled examples. We evaluate the method using two Vision Transformers pre-trained on YFCC100M and LAION400M, and test on eight classification datasets. Experimental results show that our method improves transfer accuracy over direct task vector application and achieves performance comparable to few-shot fine-tuning, while maintaining the modularity and reusability of task vectors. Our code is available at https://github.com/kawakera-lab/CrossModelTransfer.
Undertrained Image Reconstruction for Realistic Degradation in Blind Image Super-Resolution
Mar 04, 2025



Most super-resolution (SR) models struggle with real-world low-resolution (LR) images. This issue arises because the degradation characteristics in the synthetic datasets differ from those in real-world LR images. Since SR models are trained on pairs of high-resolution (HR) and LR images generated by downsampling, they are optimized for simple degradation. However, real-world LR images contain complex degradation caused by factors such as the imaging process and JPEG compression. Due to these differences in degradation characteristics, most SR models perform poorly on real-world LR images. This study proposes a dataset generation method using undertrained image reconstruction models. These models have the property of reconstructing low-quality images with diverse degradation from input images. By leveraging this property, this study generates LR images with diverse degradation from HR images to construct the datasets. Fine-tuning pre-trained SR models on our generated datasets improves noise removal and blur reduction, enhancing performance on real-world LR images. Furthermore, an analysis of the datasets reveals that degradation diversity contributes to performance improvements, whereas color differences between HR and LR images may degrade performance. 11 pages, (11 figures and 2 tables)
Robustness Evaluation of Offline Reinforcement Learning for Robot Control Against Action Perturbations
Dec 25, 2024Offline reinforcement learning, which learns solely from datasets without environmental interaction, has gained attention. This approach, similar to traditional online deep reinforcement learning, is particularly promising for robot control applications. Nevertheless, its robustness against real-world challenges, such as joint actuator faults in robots, remains a critical concern. This study evaluates the robustness of existing offline reinforcement learning methods using legged robots from OpenAI Gym based on average episodic rewards. For robustness evaluation, we simulate failures by incorporating both random and adversarial perturbations, representing worst-case scenarios, into the joint torque signals. Our experiments show that existing offline reinforcement learning methods exhibit significant vulnerabilities to these action perturbations and are more vulnerable than online reinforcement learning methods, highlighting the need for more robust approaches in this field.
Adapter Merging with Centroid Prototype Mapping for Scalable Class-Incremental Learning
Dec 24, 2024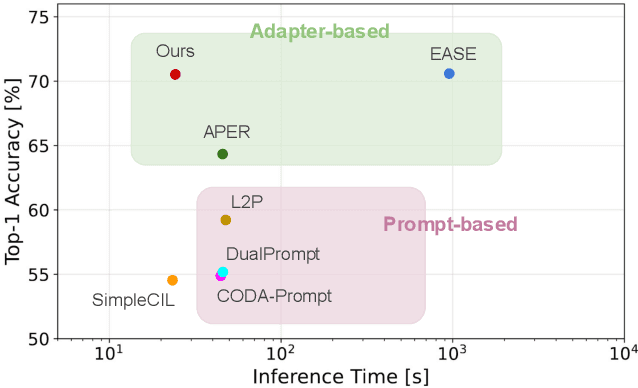
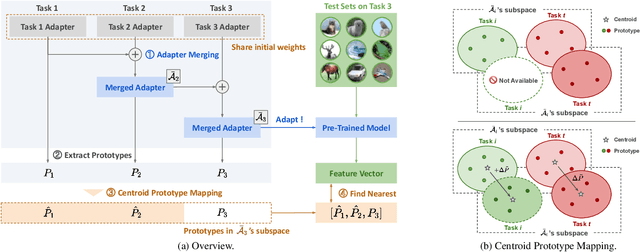
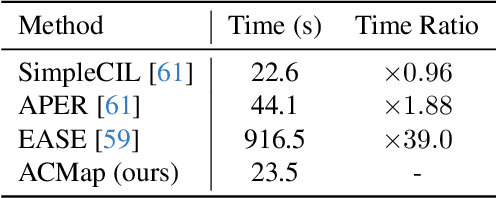
We propose Adapter Merging with Centroid Prototype Mapping (ACMap), an exemplar-free framework for class-incremental learning (CIL) that addresses both catastrophic forgetting and scalability. While existing methods trade-off between inference time and accuracy, ACMap consolidates task-specific adapters into a single adapter, ensuring constant inference time across tasks without compromising accuracy. The framework employs adapter merging to build a shared subspace that aligns task representations and mitigates forgetting, while centroid prototype mapping maintains high accuracy through consistent adaptation in the shared subspace. To further improve scalability, an early stopping strategy limits adapter merging as tasks increase. Extensive experiments on five benchmark datasets demonstrate that ACMap matches state-of-the-art accuracy while maintaining inference time comparable to the fastest existing methods. The code is available at https://github.com/tf63/ACMap