 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarially Pretrained Transformers may be Universally Robust In-Context Learners
May 20, 2025Adversarial training is one of the most effective adversarial defenses, but it incurs a high computational cost. In this study, we show that transformers adversarially pretrained on diverse tasks can serve as robust foundation models and eliminate the need for adversarial training in downstream tasks. Specifically, we theoretically demonstrate that through in-context learning, a single adversarially pretrained transformer can robustly generalize to multiple unseen tasks without any additional training, i.e., without any parameter updates. This robustness stems from the model's focus on robust features and its resistance to attacks that exploit non-predictive features. Besides these positive findings, we also identify several limitations. Under certain conditions (though unrealistic), no universally robust single-layer transformers exist. Moreover, robust transformers exhibit an accuracy--robustness trade-off and require a large number of in-context demonstrations. The code is available at https://github.com/s-kumano/universally-robust-in-context-learner.
Adversarial Training from Mean Field Perspective
May 20, 2025Although adversarial training is known to be effective against adversarial examples, training dynamics are not well understood. In this study, we present the first theoretical analysis of adversarial training in random deep neural networks without any assumptions on data distributions. We introduce a new theoretical framework based on mean field theory, which addresses the limitations of existing mean field-based approaches. Based on this framework, we derive (empirically tight) upper bounds of $\ell_q$ norm-based adversarial loss with $\ell_p$ norm-based adversarial examples for various values of $p$ and $q$. Moreover, we prove that networks without shortcuts are generally not adversarially trainable and that adversarial training reduces network capacity. We also show that network width alleviates these issues. Furthermore, we present the various impacts of the input and output dimensions on the upper bounds and time evolution of the weight variance.
Wide Two-Layer Networks can Learn from Adversarial Perturbations
Oct 31, 2024Adversarial examples have raised several open questions, such as why they can deceive classifiers and transfer between different models. A prevailing hypothesis to explain these phenomena suggests that adversarial perturbations appear as random noise but contain class-specific features. This hypothesis is supported by the success of perturbation learning, where classifiers trained solely on adversarial examples and the corresponding incorrect labels generalize well to correctly labeled test data. Although this hypothesis and perturbation learning are effective in explaining intriguing properties of adversarial examples, their solid theoretical foundation is limited. In this study, we theoretically explain the counterintuitive success of perturbation learning. We assume wide two-layer networks and the results hold for any data distribution. We prove that adversarial perturbations contain sufficient class-specific features for networks to generalize from them. Moreover, the predictions of classifiers trained on mislabeled adversarial examples coincide with those of classifiers trained on correctly labeled clean samples. The code is available at https://github.com/s-kumano/perturbation-learning.
Language-guided Detection and Mitigation of Unknown Dataset Bias
Jun 05, 2024

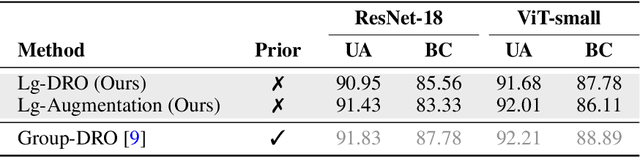

Dataset bias is a significant problem in training fair classifiers. When attributes unrelated to classification exhibit strong biases towards certain classes, classifiers trained on such dataset may overfit to these bias attributes, substantially reducing the accuracy for minority groups. Mitigation techniques can be categorized according to the availability of bias information (\ie, prior knowledge). Although scenarios with unknown biases are better suited for real-world settings, previous work in this field often suffers from a lack of interpretability regarding biases and lower performance. In this study, we propose a framework to identify potential biases as keywords without prior knowledge based on the partial occurrence in the captions. We further propose two debiasing methods: (a) handing over to an existing debiasing approach which requires prior knowledge by assigning pseudo-labels, and (b) employing data augmentation via text-to-image generative models, using acquired bias keywords as prompts. Despite its simplicity, experimental results show that our framework not only outperforms existing methods without prior knowledge, but also is even comparable with a method that assumes prior knowledge.
Theoretical Understanding of Learning from Adversarial Perturbations
Feb 16, 2024It is not fully understood why adversarial examples can deceive neural networks and transfer between different networks. To elucidate this, several studies have hypothesized that adversarial perturbations, while appearing as noises, contain class features. This is supported by empirical evidence showing that networks trained on mislabeled adversarial examples can still generalize well to correctly labeled test samples. However, a theoretical understanding of how perturbations include class features and contribute to generalization is limited. In this study, we provide a theoretical framework for understanding learning from perturbations using a one-hidden-layer network trained on mutually orthogonal samples. Our results highlight that various adversarial perturbations, even perturbations of a few pixels, contain sufficient class features for generalization. Moreover, we reveal that the decision boundary when learning from perturbations matches that from standard samples except for specific regions under mild conditions. The code is available at https://github.com/s-kumano/learning-from-adversarial-perturbations.
Data-Driven Prediction of Seismic Intensity Distributions Featuring Hybrid Classification-Regression Models
Feb 03, 2024
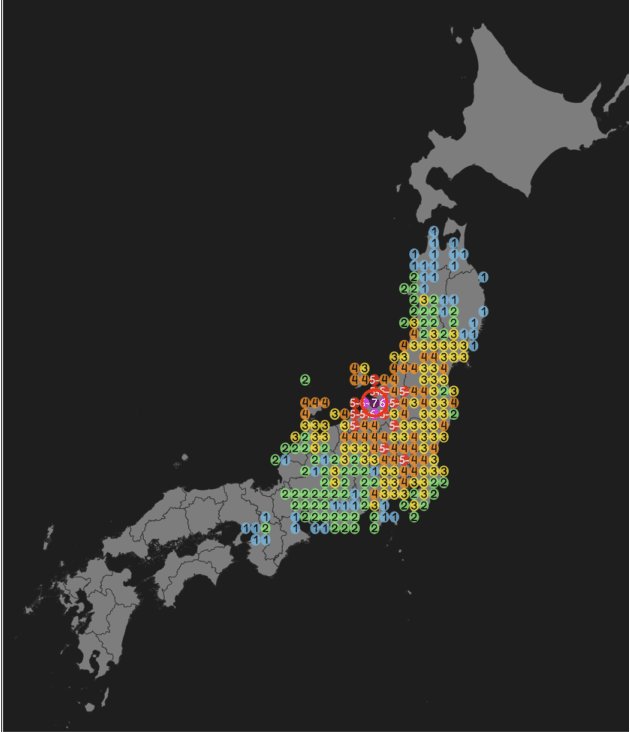
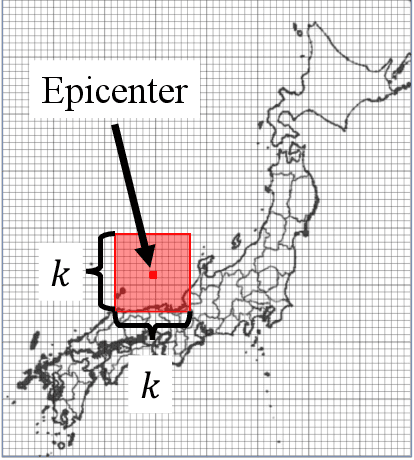

Earthquakes are among the most immediate and deadly natural disasters that humans face. Accurately forecasting the extent of earthquake damage and assessing potential risks can be instrumental in saving numerous lives. In this study, we developed linear regression models capable of predicting seismic intensity distributions based on earthquake parameters: location, depth, and magnitude. Because it is completely data-driven, it can predict intensity distributions without geographical information. The dataset comprises seismic intensity data from earthquakes that occurred in the vicinity of Japan between 1997 and 2020, specifically containing 1,857 instances of earthquakes with a magnitude of 5.0 or greater, sourced from the Japan Meteorological Agency. We trained both regression and classification models and combined them to take advantage of both to create a hybrid model. The proposed model outperformed commonly used Ground Motion Prediction Equations (GMPEs) in terms of the correlation coefficient, F1 score, and MCC. Furthermore, the proposed model can predict even abnormal seismic intensity distributions, a task at conventional GMPEs often struggle.
Improving Robustness to Out-of-Distribution Data by Frequency-based Augmentation
Sep 06, 2022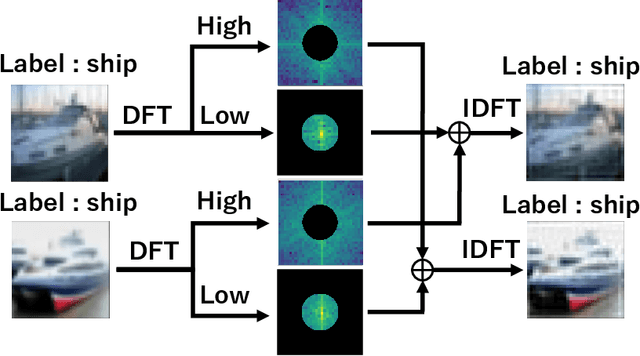
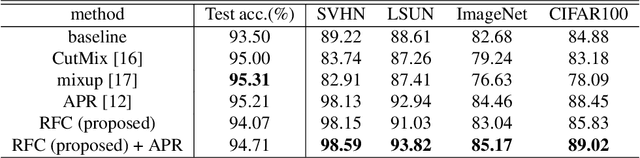

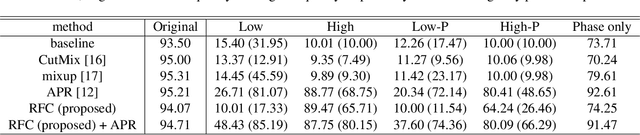
Although Convolutional Neural Networks (CNNs) have high accuracy in image recognition, they are vulnerable to adversarial examples and out-of-distribution data, and the difference from human recognition has been pointed out. In order to improve the robustness against out-of-distribution data, we present a frequency-based data augmentation technique that replaces the frequency components with other images of the same class. When the training data are CIFAR10 and the out-of-distribution data are SVHN, the Area Under Receiver Operating Characteristic (AUROC) curve of the model trained with the proposed method increases from 89.22\% to 98.15\%, and further increased to 98.59\% when combined with another data augmentation method. Furthermore, we experimentally demonstrate that the robust model for out-of-distribution data uses a lot of high-frequency components of the image.
Prediction of Seismic Intensity Distributions Using Neural Networks
Aug 16, 2022
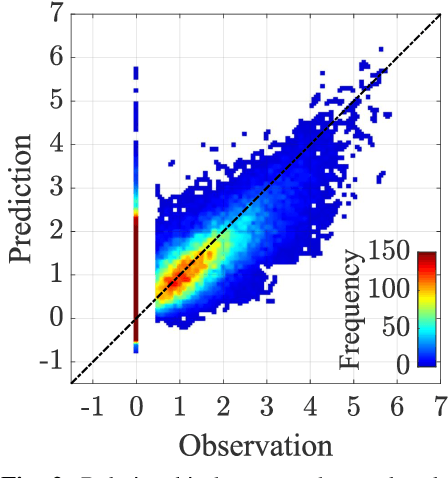
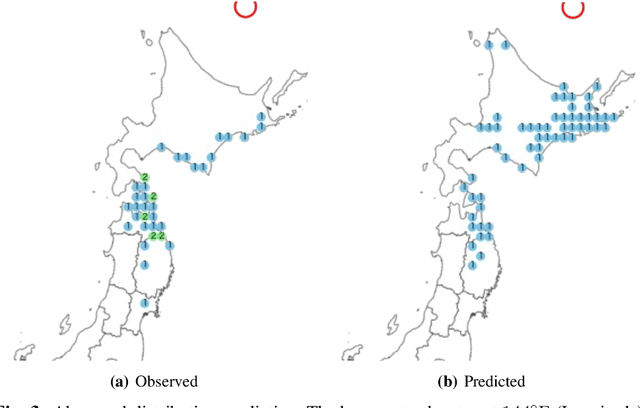
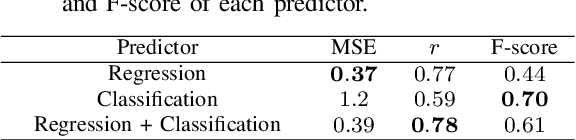
The ground motion prediction equation is commonly used to predict the seismic intensity distribution. However, it is not easy to apply this method to seismic distributions affected by underground plate structures, which are commonly known as abnormal seismic distributions. This study proposes a hybrid of regression and classification approaches using neural networks. The proposed model treats the distributions as 2-dimensional data like an image. Our method can accurately predict seismic intensity distributions, even abnormal distributions.
Superclass Adversarial Attack
May 29, 2022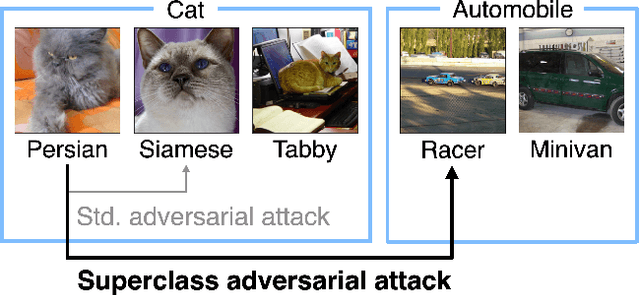
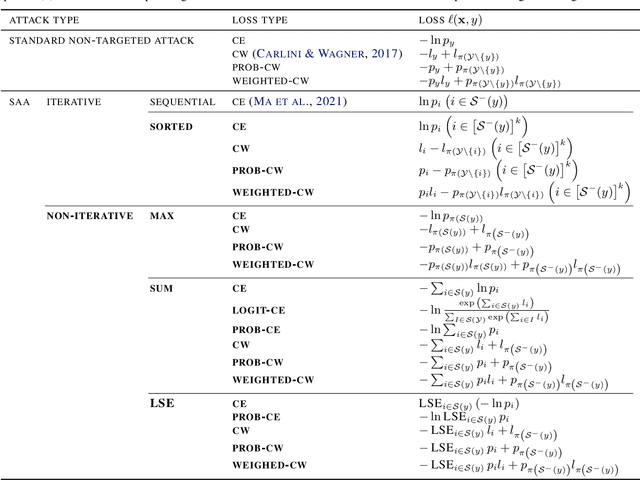

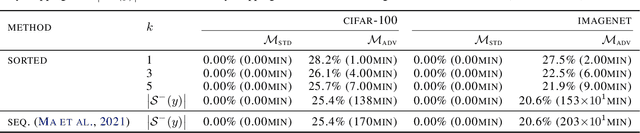
Adversarial attacks have only focused on changing the predictions of the classifier, but their danger greatly depends on how the class is mistaken. For example, when an automatic driving system mistakes a Persian cat for a Siamese cat, it is hardly a problem. However, if it mistakes a cat for a 120km/h minimum speed sign, serious problems can arise. As a stepping stone to more threatening adversarial attacks, we consider the superclass adversarial attack, which causes misclassification of not only fine classes, but also superclasses. We conducted the first comprehensive analysis of superclass adversarial attacks (an existing and 19 new methods) in terms of accuracy, speed, and stability, and identified several strategies to achieve better performance. Although this study is aimed at superclass misclassification, the findings can be applied to other problem settings involving multiple classes, such as top-k and multi-label classification attacks.
Sparse Fooling Images: Fooling Machine Perception through Unrecognizable Images
Dec 07, 2020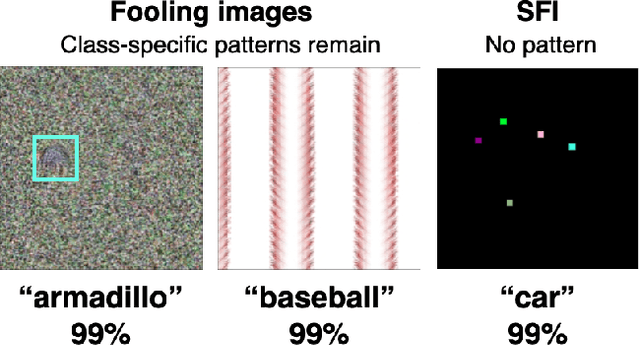

In recent years, deep neural networks (DNNs) have achieved equivalent or even higher accuracy in various recognition tasks than humans. However, some images exist that lead DNNs to a completely wrong decision, whereas humans never fail with these images. Among others, fooling images are those that are not recognizable as natural objects such as dogs and cats, but DNNs classify these images into classes with high confidence scores. In this paper, we propose a new class of fooling images, sparse fooling images (SFIs), which are single color images with a small number of altered pixels. Unlike existing fooling images, which retain some characteristic features of natural objects, SFIs do not have any local or global features that can be recognizable to humans; however, in machine perception (i.e., by DNN classifiers), SFIs are recognizable as natural objects and classified to certain classes with high confidence scores. We propose two methods to generate SFIs for different settings~(semiblack-box and white-box). We also experimentally demonstrate the vulnerability of DNNs through out-of-distribution detection and compare three architectures in terms of the robustness against SFIs. This study gives rise to questions on the structure and robustness of CNNs and discusses the differences between human and machine perception.