 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Fooling Images: Fooling Machine Perception through Unrecognizable Images
Paper and Code
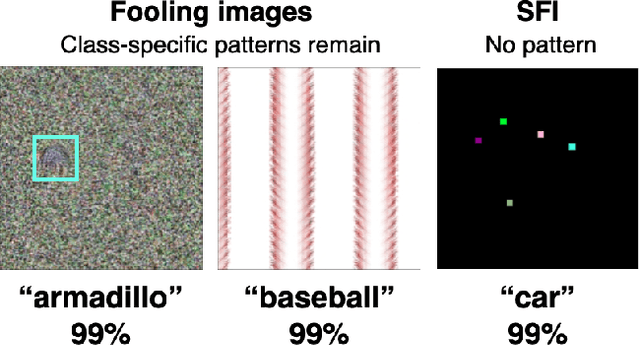

In recent years, deep neural networks (DNNs) have achieved equivalent or even higher accuracy in various recognition tasks than humans. However, some images exist that lead DNNs to a completely wrong decision, whereas humans never fail with these images. Among others, fooling images are those that are not recognizable as natural objects such as dogs and cats, but DNNs classify these images into classes with high confidence scores. In this paper, we propose a new class of fooling images, sparse fooling images (SFIs), which are single color images with a small number of altered pixels. Unlike existing fooling images, which retain some characteristic features of natural objects, SFIs do not have any local or global features that can be recognizable to humans; however, in machine perception (i.e., by DNN classifiers), SFIs are recognizable as natural objects and classified to certain classes with high confidence scores. We propose two methods to generate SFIs for different settings~(semiblack-box and white-box). We also experimentally demonstrate the vulnerability of DNNs through out-of-distribution detection and compare three architectures in terms of the robustness against SFIs. This study gives rise to questions on the structure and robustness of CNNs and discusses the differences between human and machine perception.