 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Viewpoint-Robust End-to-End Autonomous Driving with 3D Foundation Model Priors
Apr 01, 2026Robust trajectory planning under camera viewpoint changes is important for scalable end-to-end autonomous driving. However, existing models often depend heavily on the camera viewpoints seen during training. We investigate an augmentation-free approach that leverages geometric priors from a 3D foundation model. The method injects per-pixel 3D positions derived from depth estimates as positional embeddings and fuses intermediate geometric features through cross-attention. Experiments on the VR-Drive camera viewpoint perturbation benchmark show reduced performance degradation under most perturbation conditions, with clear improvements under pitch and height perturbations. Gains under longitudinal translation are smaller, suggesting that more viewpoint-agnostic integration is needed for robustness to camera viewpoint changes.
Robust Human Trajectory Prediction via Self-Supervised Skeleton Representation Learning
Feb 26, 2026Human trajectory prediction plays a crucial role in applications such as autonomous navigation and video surveillance. While recent works have explored the integration of human skeleton sequences to complement trajectory information, skeleton data in real-world environments often suffer from missing joints caused by occlusions. These disturbances significantly degrade prediction accuracy, indicating the need for more robust skeleton representations. We propose a robust trajectory prediction method that incorporates a self-supervised skeleton representation model pretrained with masked autoencoding. Experimental results in occlusion-prone scenarios show that our method improves robustness to missing skeletal data without sacrificing prediction accuracy, and consistently outperforms baseline models in clean-to-moderate missingness regimes.
Zero-Shot Textual Explanations via Translating Decision-Critical Features
Dec 08, 2025Textual explanations make image classifier decisions transparent by describing the prediction rationale in natural language. Large vision-language models can generate captions but are designed for general visual understanding, not classifier-specific reasoning. Existing zero-shot explanation methods align global image features with language, producing descriptions of what is visible rather than what drives the prediction. We propose TEXTER, which overcomes this limitation by isolating decision-critical features before alignment. TEXTER identifies the neurons contributing to the prediction and emphasizes the features encoded in those neurons -- i.e., the decision-critical features. It then maps these emphasized features into the CLIP feature space to retrieve textual explanations that reflect the model's reasoning. A sparse autoencoder further improves interpretability, particularly for Transformer architectures. Extensive experiments show that TEXTER generates more faithful and interpretable explanations than existing methods. The code will be publicly released.
Cross-Model Transfer of Task Vectors via Few-Shot Orthogonal Alignment
May 17, 2025Task arithmetic enables efficient model editing by representing task-specific changes as vectors in parameter space. Task arithmetic typically assumes that the source and target models are initialized from the same pre-trained parameters. This assumption limits its applicability in cross-model transfer settings, where models are independently pre-trained on different datasets. To address this challenge, we propose a method based on few-shot orthogonal alignment, which aligns task vectors to the parameter space of a differently pre-trained target model. These transformations preserve key properties of task vectors, such as norm and rank, and are learned using only a small number of labeled examples. We evaluate the method using two Vision Transformers pre-trained on YFCC100M and LAION400M, and test on eight classification datasets. Experimental results show that our method improves transfer accuracy over direct task vector application and achieves performance comparable to few-shot fine-tuning, while maintaining the modularity and reusability of task vectors. Our code is available at https://github.com/kawakera-lab/CrossModelTransfer.
Undertrained Image Reconstruction for Realistic Degradation in Blind Image Super-Resolution
Mar 04, 2025



Most super-resolution (SR) models struggle with real-world low-resolution (LR) images. This issue arises because the degradation characteristics in the synthetic datasets differ from those in real-world LR images. Since SR models are trained on pairs of high-resolution (HR) and LR images generated by downsampling, they are optimized for simple degradation. However, real-world LR images contain complex degradation caused by factors such as the imaging process and JPEG compression. Due to these differences in degradation characteristics, most SR models perform poorly on real-world LR images. This study proposes a dataset generation method using undertrained image reconstruction models. These models have the property of reconstructing low-quality images with diverse degradation from input images. By leveraging this property, this study generates LR images with diverse degradation from HR images to construct the datasets. Fine-tuning pre-trained SR models on our generated datasets improves noise removal and blur reduction, enhancing performance on real-world LR images. Furthermore, an analysis of the datasets reveals that degradation diversity contributes to performance improvements, whereas color differences between HR and LR images may degrade performance. 11 pages, (11 figures and 2 tables)
Robustness Evaluation of Offline Reinforcement Learning for Robot Control Against Action Perturbations
Dec 25, 2024Offline reinforcement learning, which learns solely from datasets without environmental interaction, has gained attention. This approach, similar to traditional online deep reinforcement learning, is particularly promising for robot control applications. Nevertheless, its robustness against real-world challenges, such as joint actuator faults in robots, remains a critical concern. This study evaluates the robustness of existing offline reinforcement learning methods using legged robots from OpenAI Gym based on average episodic rewards. For robustness evaluation, we simulate failures by incorporating both random and adversarial perturbations, representing worst-case scenarios, into the joint torque signals. Our experiments show that existing offline reinforcement learning methods exhibit significant vulnerabilities to these action perturbations and are more vulnerable than online reinforcement learning methods, highlighting the need for more robust approaches in this field.
Adapter Merging with Centroid Prototype Mapping for Scalable Class-Incremental Learning
Dec 24, 2024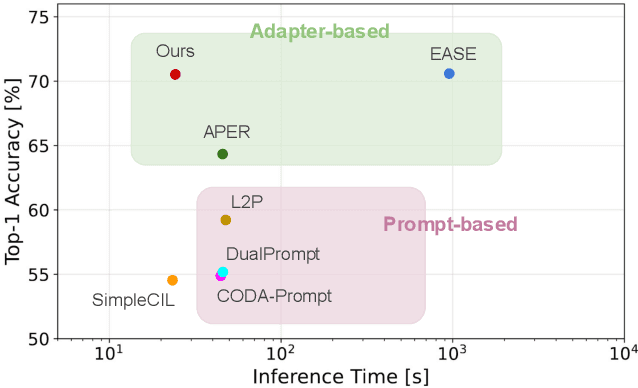
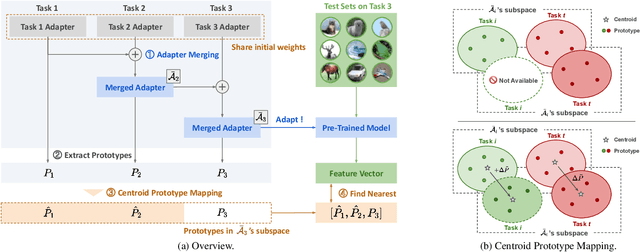
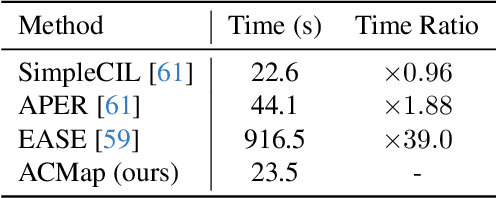
We propose Adapter Merging with Centroid Prototype Mapping (ACMap), an exemplar-free framework for class-incremental learning (CIL) that addresses both catastrophic forgetting and scalability. While existing methods trade-off between inference time and accuracy, ACMap consolidates task-specific adapters into a single adapter, ensuring constant inference time across tasks without compromising accuracy. The framework employs adapter merging to build a shared subspace that aligns task representations and mitigates forgetting, while centroid prototype mapping maintains high accuracy through consistent adaptation in the shared subspace. To further improve scalability, an early stopping strategy limits adapter merging as tasks increase. Extensive experiments on five benchmark datasets demonstrate that ACMap matches state-of-the-art accuracy while maintaining inference time comparable to the fastest existing methods. The code is available at https://github.com/tf63/ACMap
Explaining Object Detectors via Collective Contribution of Pixels
Dec 01, 2024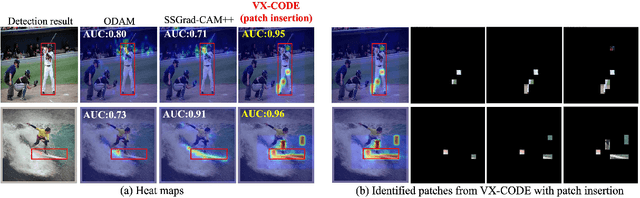
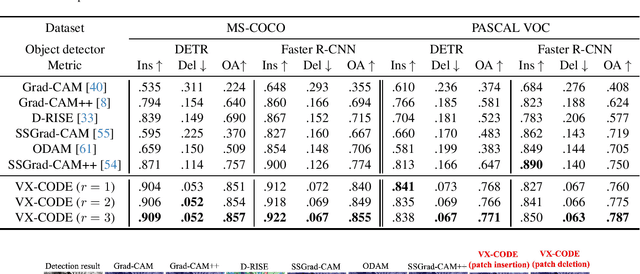
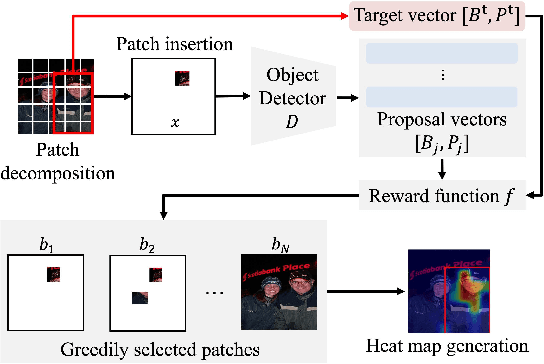
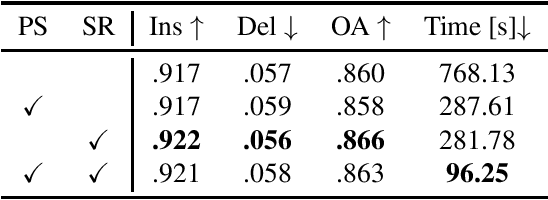
Visual explanations for object detectors are crucial for enhancing their reliability. Since object detectors identify and localize instances by assessing multiple features collectively, generating explanations that capture these collective contributions is critical. However, existing methods focus solely on individual pixel contributions, ignoring the collective contribution of multiple pixels. To address this, we proposed a method for object detectors that considers the collective contribution of multiple pixels. Our approach leverages game-theoretic concepts, specifically Shapley values and interactions, to provide explanations. These explanations cover both bounding box generation and class determination, considering both individual and collective pixel contributions. Extensive quantitative and qualitative experiments demonstrate that the proposed method more accurately identifies important regions in detection results compared to current state-of-the-art methods. The code will be publicly available soon.
Low-Quality Image Detection by Hierarchical VAE
Aug 20, 2024To make an employee roster, photo album, or training dataset of generative models, one needs to collect high-quality images while dismissing low-quality ones. This study addresses a new task of unsupervised detection of low-quality images. We propose a method that not only detects low-quality images with various types of degradation but also provides visual clues of them based on an observation that partial reconstruction by hierarchical variational autoencoders fails for low-quality images. The experiments show that our method outperforms several unsupervised out-of-distribution detection methods and also gives visual clues for low-quality images that help humans recognize them even in thumbnail view.
VarteX: Enhancing Weather Forecast through Distributed Variable Representation
Jun 28, 2024Weather forecasting is essential for various human activities. Recent data-driven models have outperformed numerical weather prediction by utilizing deep learning in forecasting performance. However, challenges remain in efficiently handling multiple meteorological variables. This study proposes a new variable aggregation scheme and an efficient learning framework for that challenge. Experiments show that VarteX outperforms the conventional model in forecast performance, requiring significantly fewer parameters and resources. The effectiveness of learning through multiple aggregations and regional split training is demonstrated, enabling more efficient and accurate deep learning-based weather forecasting.