 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Vision Language Model Unlearning via Fictitious Facial Identity Dataset
Nov 05, 2024



Machine unlearning has emerged as an effective strategy for forgetting specific information in the training data. However, with the increasing integration of visual data, privacy concerns in Vision Language Models (VLMs) remain underexplored. To address this, we introduce Facial Identity Unlearning Benchmark (FIUBench), a novel VLM unlearning benchmark designed to robustly evaluate the effectiveness of unlearning algorithms under the Right to be Forgotten setting. Specifically, we formulate the VLM unlearning task via constructing the Fictitious Facial Identity VQA dataset and apply a two-stage evaluation pipeline that is designed to precisely control the sources of information and their exposure levels. In terms of evaluation, since VLM supports various forms of ways to ask questions with the same semantic meaning, we also provide robust evaluation metrics including membership inference attacks and carefully designed adversarial privacy attacks to evaluate the performance of algorithms. Through the evaluation of four baseline VLM unlearning algorithms within FIUBench, we find that all methods remain limited in their unlearning performance, with significant trade-offs between model utility and forget quality. Furthermore, our findings also highlight the importance of privacy attacks for robust evaluations. We hope FIUBench will drive progress in developing more effective VLM unlearning algorithms.
MixLoRA: Enhancing Large Language Models Fine-Tuning with LoRA based Mixture of Experts
Apr 22, 2024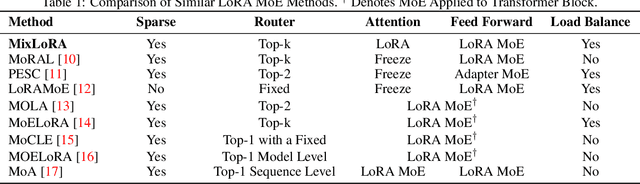
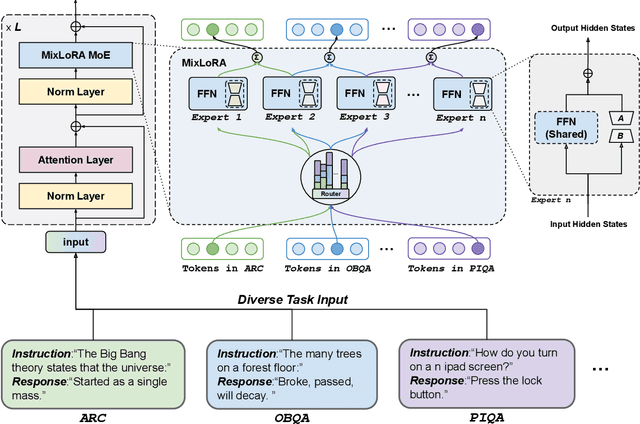


Large Language Models (LLMs) have showcased exceptional performance across a wide array of Natural Language Processing (NLP) tasks. Fine-tuning techniques are commonly utilized to tailor pre-trained models to specific applications. While methods like LoRA have effectively tackled GPU memory constraints during fine-tuning, their applicability is often restricted to limited performance, especially on multi-task. On the other hand, Mix-of-Expert (MoE) models, such as Mixtral 8x7B, demonstrate remarkable performance across multiple NLP tasks while maintaining a reduced parameter count. However, the resource requirements of these MoEs still challenging, particularly for consumer-grade GPUs only have limited VRAM. To address these challenge, we propose MixLoRA, an innovative approach aimed at constructing a resource-efficient sparse MoE model based on LoRA. MixLoRA inserts multiple LoRA-based experts within the feed-forward network block of a frozen pre-trained dense model through fine-tuning, employing a commonly used top-k router. Unlike other LoRA based MoE methods, MixLoRA enhances model performance by utilizing independently configurable attention-layer LoRA adapters, supporting the use of LoRA and its variants for the construction of experts, and applying auxiliary load balance loss to address the imbalance problem of the router. In experiments, MixLoRA achieves commendable performance across all evaluation metrics in both single-task and multi-task learning scenarios. Implemented within the m-LoRA framework, MixLoRA enables parallel fine-tuning of multiple mixture-of-experts models on a single 24GB consumer-grade GPU without quantization, thereby reducing GPU memory consumption by 41\% and latency during the training process by 17\%.
Multi: Multimodal Understanding Leaderboard with Text and Images
Feb 05, 2024
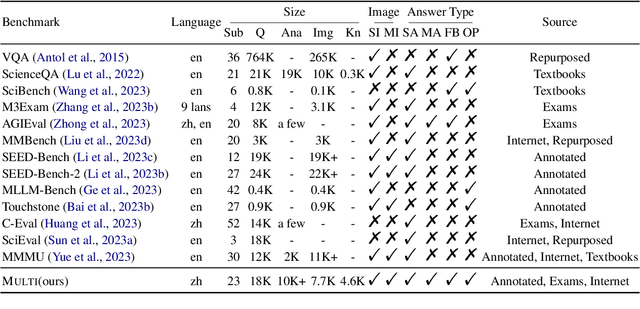
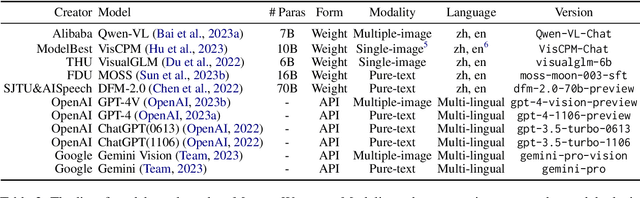

Rapid progress in multimodal large language models (MLLMs) highlights the need to introduce challenging yet realistic benchmarks to the academic community. Existing benchmarks primarily focus on simple natural image understanding, but Multi emerges as a cutting-edge benchmark for MLLMs, offering a comprehensive dataset for evaluating MLLMs against understanding complex figures and tables, and scientific questions. This benchmark, reflecting current realistic examination styles, provides multimodal inputs and requires responses that are either precise or open-ended, similar to real-life school tests. It challenges MLLMs with a variety of tasks, ranging from formula derivation to image detail analysis, and cross-modality reasoning. Multi includes over 18,000 questions, with a focus on science-based QA in diverse formats. We also introduce Multi-Elite, a 500-question subset for testing the extremities of MLLMs, and Multi-Extend, which enhances In-Context Learning research with more than 4,500 knowledge pieces. Our evaluation indicates significant potential for MLLM advancement, with GPT-4V achieving a 63.7% accuracy rate on Multi, in contrast to other MLLMs scoring between 31.3% and 53.7%. Multi serves not only as a robust evaluation platform but also paves the way for the development of expert-level AI.
Dolphins: Multimodal Language Model for Driving
Dec 01, 2023



The quest for fully autonomous vehicles (AVs) capable of navigating complex real-world scenarios with human-like understanding and responsiveness. In this paper, we introduce Dolphins, a novel vision-language model architected to imbibe human-like abilities as a conversational driving assistant. Dolphins is adept at processing multimodal inputs comprising video (or image) data, text instructions, and historical control signals to generate informed outputs corresponding to the provided instructions. Building upon the open-sourced pretrained Vision-Language Model, OpenFlamingo, we first enhance Dolphins's reasoning capabilities through an innovative Grounded Chain of Thought (GCoT) process. Then we tailored Dolphins to the driving domain by constructing driving-specific instruction data and conducting instruction tuning. Through the utilization of the BDD-X dataset, we designed and consolidated four distinct AV tasks into Dolphins to foster a holistic understanding of intricate driving scenarios. As a result, the distinctive features of Dolphins are characterized into two dimensions: (1) the ability to provide a comprehensive understanding of complex and long-tailed open-world driving scenarios and solve a spectrum of AV tasks, and (2) the emergence of human-like capabilities including gradient-free instant adaptation via in-context learning and error recovery via reflection.