 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti: Multimodal Understanding Leaderboard with Text and Images
Feb 05, 2024
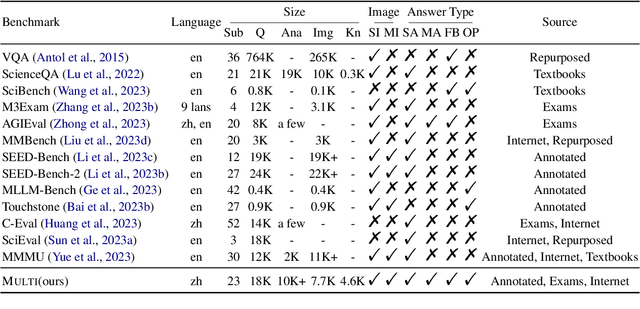
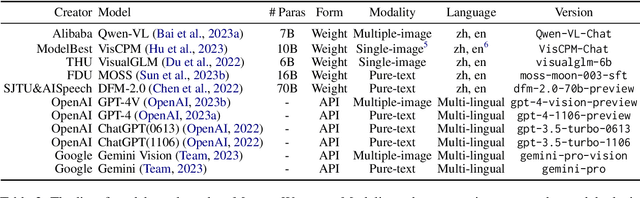

Rapid progress in multimodal large language models (MLLMs) highlights the need to introduce challenging yet realistic benchmarks to the academic community. Existing benchmarks primarily focus on simple natural image understanding, but Multi emerges as a cutting-edge benchmark for MLLMs, offering a comprehensive dataset for evaluating MLLMs against understanding complex figures and tables, and scientific questions. This benchmark, reflecting current realistic examination styles, provides multimodal inputs and requires responses that are either precise or open-ended, similar to real-life school tests. It challenges MLLMs with a variety of tasks, ranging from formula derivation to image detail analysis, and cross-modality reasoning. Multi includes over 18,000 questions, with a focus on science-based QA in diverse formats. We also introduce Multi-Elite, a 500-question subset for testing the extremities of MLLMs, and Multi-Extend, which enhances In-Context Learning research with more than 4,500 knowledge pieces. Our evaluation indicates significant potential for MLLM advancement, with GPT-4V achieving a 63.7% accuracy rate on Multi, in contrast to other MLLMs scoring between 31.3% and 53.7%. Multi serves not only as a robust evaluation platform but also paves the way for the development of expert-level AI.