 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Last Human-Written Paper: Agent-Native Research Artifacts
Apr 27, 2026Scientific publication compresses a branching, iterative research process into a linear narrative, discarding the majority of what was discovered along the way. This compilation imposes two structural costs: a Storytelling Tax, where failed experiments, rejected hypotheses, and the branching exploration process are discarded to fit a linear narrative; and an Engineering Tax, where the gap between reviewer-sufficient prose and agent-sufficient specification leaves critical implementation details unwritten. Tolerable for human readers, these costs become critical when AI agents must understand, reproduce, and extend published work. We introduce the Agent-Native Research Artifact (Ara), a protocol that replaces the narrative paper with a machine-executable research package structured around four layers: scientific logic, executable code with full specifications, an exploration graph that preserves the failures compilation discards, and evidence grounding every claim in raw outputs. Three mechanisms support the ecosystem: a Live Research Manager that captures decisions and dead ends during ordinary development; an Ara Compiler that translates legacy PDFs and repos into Aras; and an Ara-native review system that automates objective checks so human reviewers can focus on significance, novelty, and taste. On PaperBench and RE-Bench, Ara raises question-answering accuracy from 72.4% to 93.7% and reproduction success from 57.4% to 64.4%. On RE-Bench's five open-ended extension tasks, preserved failure traces in Ara accelerate progress, but can also constrain a capable agent from stepping outside the prior-run box depending on the agent's capabilities.
On-Policy Self-Distillation for Reasoning Compression
Mar 05, 2026Reasoning models think out loud, but much of what they say is noise. We introduce OPSDC (On-Policy Self-Distillation for Reasoning Compression), a method that teaches models to reason more concisely by distilling their own concise behavior back into themselves. The entire approach reduces to one idea: condition the same model on a "be concise" instruction to obtain teacher logits, and minimize per-token reverse KL on the student's own rollouts. No ground-truth answers, no token budgets, no difficulty estimators. Just self-distillation. Yet this simplicity belies surprising sophistication: OPSDC automatically compresses easy problems aggressively while preserving the deliberation needed for hard ones. On Qwen3-8B and Qwen3-14B, we achieve 57-59% token reduction on MATH-500 while improving accuracy by 9-16 points absolute. On AIME 2024, the 14B model gains 10 points with 41% compression. The secret? Much of what reasoning models produce is not just redundant-it is actively harmful, compounding errors with every unnecessary token.
HulluEdit: Single-Pass Evidence-Consistent Subspace Editing for Mitigating Hallucinations in Large Vision-Language Models
Feb 26, 2026Object hallucination in Large Vision-Language Models (LVLMs) significantly hinders their reliable deployment. Existing methods struggle to balance efficiency and accuracy: they often require expensive reference models and multiple forward passes, or apply static edits that risk suppressing genuine visual evidence. To address this, we introduce HulluEdit, a single-pass, reference-free intervention framework. Our core innovation is orthogonal subspace editing: we decompose the hidden states of the model into orthogonal subspaces - visual evidence, conflicting priors, and residual uncertainty - enabling selective suppression of hallucinatory patterns without interfering with visual grounding. This approach mathematically guarantees that edits applied to the prior subspace leave the visual component entirely unaffected. Extensive experiments show that HulluEdit achieves state-of-the-art hallucination reduction on benchmarks including POPE and CHAIR across diverse architectures, while preserving general capabilities on MME and maintaining efficient inference. Our method consistently outperforms contrastive decoding and static subspace editing baselines, offering a new pathway toward more trustworthy LVLMs.
Stance-Driven Multimodal Controlled Statement Generation: New Dataset and Task
Apr 04, 2025



Formulating statements that support diverse or controversial stances on specific topics is vital for platforms that enable user expression, reshape political discourse, and drive social critique and information dissemination. With the rise of Large Language Models (LLMs), controllable text generation towards specific stances has become a promising research area with applications in shaping public opinion and commercial marketing. However, current datasets often focus solely on pure texts, lacking multimodal content and effective context, particularly in the context of stance detection. In this paper, we formally define and study the new problem of stance-driven controllable content generation for tweets with text and images, where given a multimodal post (text and image/video), a model generates a stance-controlled response. To this end, we create the Multimodal Stance Generation Dataset (StanceGen2024), the first resource explicitly designed for multimodal stance-controllable text generation in political discourse. It includes posts and user comments from the 2024 U.S. presidential election, featuring text, images, videos, and stance annotations to explore how multimodal political content shapes stance expression. Furthermore, we propose a Stance-Driven Multimodal Generation (SDMG) framework that integrates weighted fusion of multimodal features and stance guidance to improve semantic consistency and stance control. We release the dataset and code (https://anonymous.4open.science/r/StanceGen-BE9D) for public use and further research.
Optimizing GPT for Video Understanding: Zero-Shot Performance and Prompt Engineering
Feb 13, 2025



In this study, we tackle industry challenges in video content classification by exploring and optimizing GPT-based models for zero-shot classification across seven critical categories of video quality. We contribute a novel approach to improving GPT's performance through prompt optimization and policy refinement, demonstrating that simplifying complex policies significantly reduces false negatives. Additionally, we introduce a new decomposition-aggregation-based prompt engineering technique, which outperforms traditional single-prompt methods. These experiments, conducted on real industry problems, show that thoughtful prompt design can substantially enhance GPT's performance without additional finetuning, offering an effective and scalable solution for improving video classification systems across various domains in industry.
Cocoon: Robust Multi-Modal Perception with Uncertainty-Aware Sensor Fusion
Oct 16, 2024
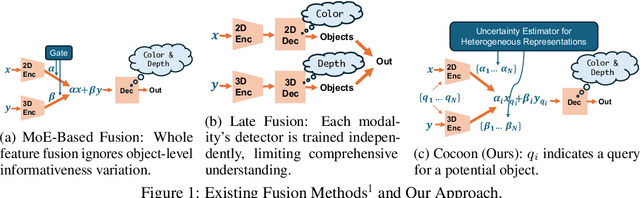
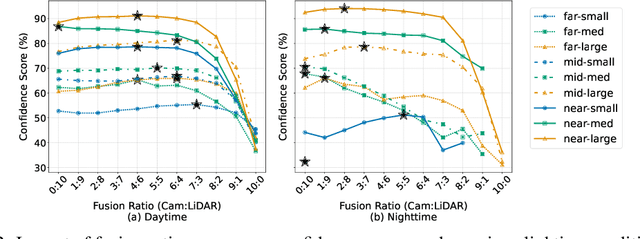
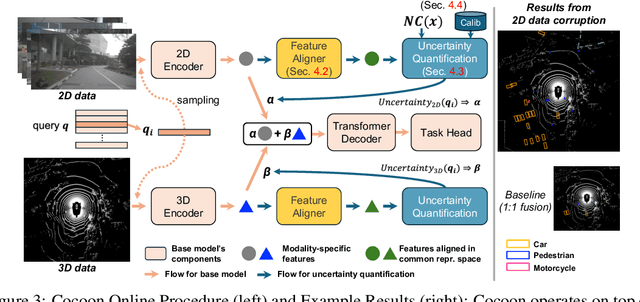
An important paradigm in 3D object detection is the use of multiple modalities to enhance accuracy in both normal and challenging conditions, particularly for long-tail scenarios. To address this, recent studies have explored two directions of adaptive approaches: MoE-based adaptive fusion, which struggles with uncertainties arising from distinct object configurations, and late fusion for output-level adaptive fusion, which relies on separate detection pipelines and limits comprehensive understanding. In this work, we introduce Cocoon, an object- and feature-level uncertainty-aware fusion framework. The key innovation lies in uncertainty quantification for heterogeneous representations, enabling fair comparison across modalities through the introduction of a feature aligner and a learnable surrogate ground truth, termed feature impression. We also define a training objective to ensure that their relationship provides a valid metric for uncertainty quantification. Cocoon consistently outperforms existing static and adaptive methods in both normal and challenging conditions, including those with natural and artificial corruptions. Furthermore, we show the validity and efficacy of our uncertainty metric across diverse datasets.
ASFT: Aligned Supervised Fine-Tuning through Absolute Likelihood
Sep 14, 2024



Direct Preference Optimization (DPO) is a method for enhancing model performance by directly optimizing for the preferences or rankings of outcomes, instead of traditional loss functions. This approach has proven effective in aligning Large Language Models (LLMs) with human preferences. Despite its widespread use across various tasks, DPO has been criticized for its sensitivity to the effectiveness of Supervised Fine-Tuning (SFT) and its limitations in enabling models to learn human-preferred responses, leading to less satisfactory performance. To address these limitations, we propose Aligned Supervised Fine-Tuning (ASFT), an effective approach that better aligns LLMs with pair-wise datasets by optimizing absolute likelihood for each response, rather than using the Bradley-Terry model, and eliminates the need for a reference model. Through theoretical gradient analysis, we demonstrate that ASFT mitigates the issue where the DPO loss function decreases the probability of generating human-dispreferred data at a faster rate than it increases the probability of producing preferred data. Additionally, we compare ASFT to DPO and its latest variants, such as the single-step approach ORPO, using the latest instruction-tuned model Llama3, which has been fine-tuned on UltraFeedback and HH-RLHF. We evaluated performance on instruction-following benchmarks like MT-Bench and traditional text generation metrics such as BLEU-4 and ROUGE-L. Extensive experiments demonstrate that ASFT is an effective alignment approach, consistently outperforming existing methods.
ELFS: Enhancing Label-Free Coreset Selection via Clustering-based Pseudo-Labeling
Jun 06, 2024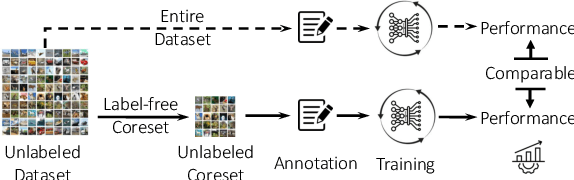
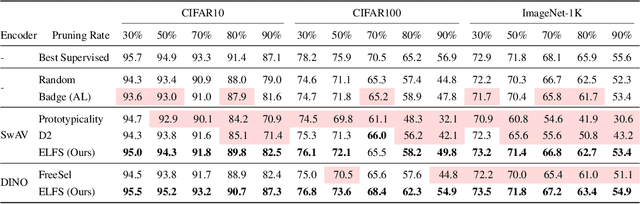

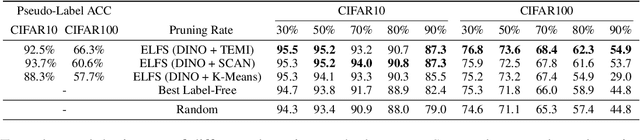
High-quality human-annotated data is crucial for modern deep learning pipelines, yet the human annotation process is both costly and time-consuming. Given a constrained human labeling budget, selecting an informative and representative data subset for labeling can significantly reduce human annotation effort. Well-performing state-of-the-art (SOTA) coreset selection methods require ground-truth labels over the whole dataset, failing to reduce the human labeling burden. Meanwhile, SOTA label-free coreset selection methods deliver inferior performance due to poor geometry-based scores. In this paper, we introduce ELFS, a novel label-free coreset selection method. ELFS employs deep clustering to estimate data difficulty scores without ground-truth labels. Furthermore, ELFS uses a simple but effective double-end pruning method to mitigate bias on calculated scores, which further improves the performance on selected coresets. We evaluate ELFS on five vision benchmarks and show that ELFS consistently outperforms SOTA label-free baselines. For instance, at a 90% pruning rate, ELFS surpasses the best-performing baseline by 5.3% on CIFAR10 and 7.1% on CIFAR100. Moreover, ELFS even achieves comparable performance to supervised coreset selection at low pruning rates (e.g., 30% and 50%) on CIFAR10 and ImageNet-1K.
Safeguarding Vision-Language Models Against Patched Visual Prompt Injectors
May 17, 2024



Large language models have become increasingly prominent, also signaling a shift towards multimodality as the next frontier in artificial intelligence, where their embeddings are harnessed as prompts to generate textual content. Vision-language models (VLMs) stand at the forefront of this advancement, offering innovative ways to combine visual and textual data for enhanced understanding and interaction. However, this integration also enlarges the attack surface. Patch-based adversarial attack is considered the most realistic threat model in physical vision applications, as demonstrated in many existing literature. In this paper, we propose to address patched visual prompt injection, where adversaries exploit adversarial patches to generate target content in VLMs. Our investigation reveals that patched adversarial prompts exhibit sensitivity to pixel-wise randomization, a trait that remains robust even against adaptive attacks designed to counteract such defenses. Leveraging this insight, we introduce SmoothVLM, a defense mechanism rooted in smoothing techniques, specifically tailored to protect VLMs from the threat of patched visual prompt injectors. Our framework significantly lowers the attack success rate to a range between 0% and 5.0% on two leading VLMs, while achieving around 67.3% to 95.0% context recovery of the benign images, demonstrating a balance between security and usability.
Dolphins: Multimodal Language Model for Driving
Dec 01, 2023



The quest for fully autonomous vehicles (AVs) capable of navigating complex real-world scenarios with human-like understanding and responsiveness. In this paper, we introduce Dolphins, a novel vision-language model architected to imbibe human-like abilities as a conversational driving assistant. Dolphins is adept at processing multimodal inputs comprising video (or image) data, text instructions, and historical control signals to generate informed outputs corresponding to the provided instructions. Building upon the open-sourced pretrained Vision-Language Model, OpenFlamingo, we first enhance Dolphins's reasoning capabilities through an innovative Grounded Chain of Thought (GCoT) process. Then we tailored Dolphins to the driving domain by constructing driving-specific instruction data and conducting instruction tuning. Through the utilization of the BDD-X dataset, we designed and consolidated four distinct AV tasks into Dolphins to foster a holistic understanding of intricate driving scenarios. As a result, the distinctive features of Dolphins are characterized into two dimensions: (1) the ability to provide a comprehensive understanding of complex and long-tailed open-world driving scenarios and solve a spectrum of AV tasks, and (2) the emergence of human-like capabilities including gradient-free instant adaptation via in-context learning and error recovery via reflection.