 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing GPT for Video Understanding: Zero-Shot Performance and Prompt Engineering
Feb 13, 2025



In this study, we tackle industry challenges in video content classification by exploring and optimizing GPT-based models for zero-shot classification across seven critical categories of video quality. We contribute a novel approach to improving GPT's performance through prompt optimization and policy refinement, demonstrating that simplifying complex policies significantly reduces false negatives. Additionally, we introduce a new decomposition-aggregation-based prompt engineering technique, which outperforms traditional single-prompt methods. These experiments, conducted on real industry problems, show that thoughtful prompt design can substantially enhance GPT's performance without additional finetuning, offering an effective and scalable solution for improving video classification systems across various domains in industry.
Inverse Reinforcement Learning by Estimating Expertise of Demonstrators
Feb 02, 2024



In Imitation Learning (IL), utilizing suboptimal and heterogeneous demonstrations presents a substantial challenge due to the varied nature of real-world data. However, standard IL algorithms consider these datasets as homogeneous, thereby inheriting the deficiencies of suboptimal demonstrators. Previous approaches to this issue typically rely on impractical assumptions like high-quality data subsets, confidence rankings, or explicit environmental knowledge. This paper introduces IRLEED, Inverse Reinforcement Learning by Estimating Expertise of Demonstrators, a novel framework that overcomes these hurdles without prior knowledge of demonstrator expertise. IRLEED enhances existing Inverse Reinforcement Learning (IRL) algorithms by combining a general model for demonstrator suboptimality to address reward bias and action variance, with a Maximum Entropy IRL framework to efficiently derive the optimal policy from diverse, suboptimal demonstrations. Experiments in both online and offline IL settings, with simulated and human-generated data, demonstrate IRLEED's adaptability and effectiveness, making it a versatile solution for learning from suboptimal demonstrations.
Imitation Learning by Estimating Expertise of Demonstrators
Feb 02, 2022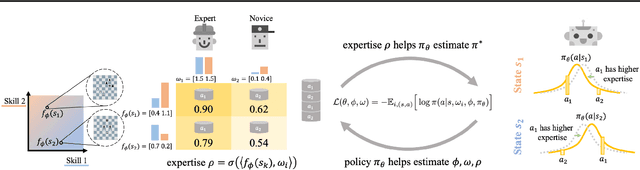



Many existing imitation learning datasets are collected from multiple demonstrators, each with different expertise at different parts of the environment. Yet, standard imitation learning algorithms typically treat all demonstrators as homogeneous, regardless of their expertise, absorbing the weaknesses of any suboptimal demonstrators. In this work, we show that unsupervised learning over demonstrator expertise can lead to a consistent boost in the performance of imitation learning algorithms. We develop and optimize a joint model over a learned policy and expertise levels of the demonstrators. This enables our model to learn from the optimal behavior and filter out the suboptimal behavior of each demonstrator. Our model learns a single policy that can outperform even the best demonstrator, and can be used to estimate the expertise of any demonstrator at any state. We illustrate our findings on real-robotic continuous control tasks from Robomimic and discrete environments such as MiniGrid and chess, out-performing competing methods in $21$ out of $23$ settings, with an average of $7\%$ and up to $60\%$ improvement in terms of the final reward.
Efficient and Robust Classification for Sparse Attacks
Jan 23, 2022



In the past two decades we have seen the popularity of neural networks increase in conjunction with their classification accuracy. Parallel to this, we have also witnessed how fragile the very same prediction models are: tiny perturbations to the inputs can cause misclassification errors throughout entire datasets. In this paper, we consider perturbations bounded by the $\ell_0$--norm, which have been shown as effective attacks in the domains of image-recognition, natural language processing, and malware-detection. To this end, we propose a novel defense method that consists of "truncation" and "adversarial training". We then theoretically study the Gaussian mixture setting and prove the asymptotic optimality of our proposed classifier. Motivated by the insights we obtain, we extend these components to neural network classifiers. We conduct numerical experiments in the domain of computer vision using the MNIST and CIFAR datasets, demonstrating significant improvement for the robust classification error of neural networks.
Emergent Prosociality in Multi-Agent Games Through Gifting
May 13, 2021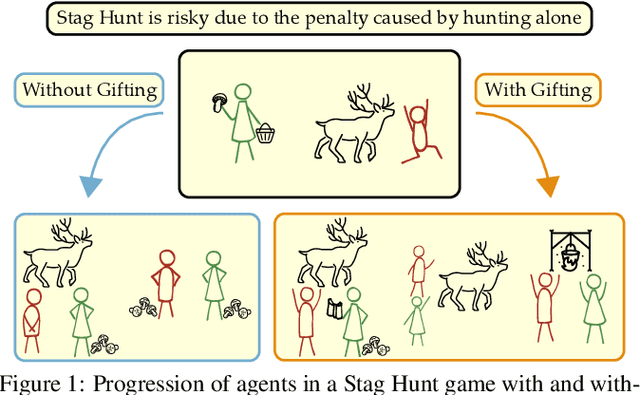
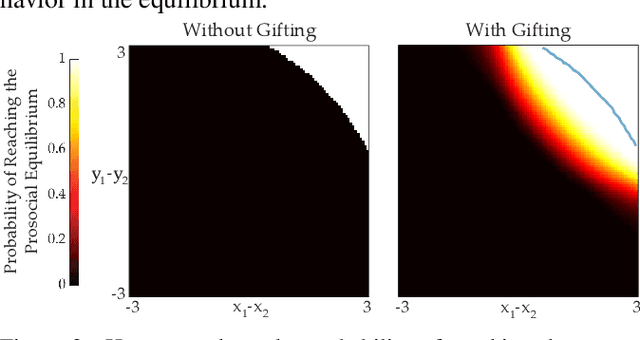

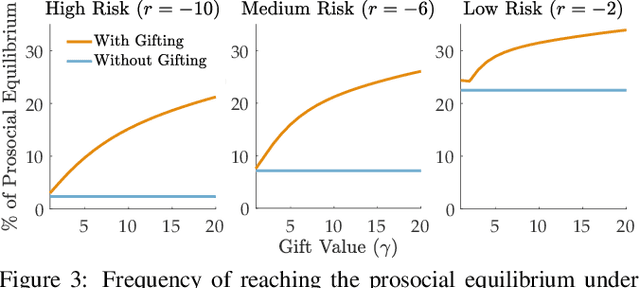
Coordination is often critical to forming prosocial behaviors -- behaviors that increase the overall sum of rewards received by all agents in a multi-agent game. However, state of the art reinforcement learning algorithms often suffer from converging to socially less desirable equilibria when multiple equilibria exist. Previous works address this challenge with explicit reward shaping, which requires the strong assumption that agents can be forced to be prosocial. We propose using a less restrictive peer-rewarding mechanism, gifting, that guides the agents toward more socially desirable equilibria while allowing agents to remain selfish and decentralized. Gifting allows each agent to give some of their reward to other agents. We employ a theoretical framework that captures the benefit of gifting in converging to the prosocial equilibrium by characterizing the equilibria's basins of attraction in a dynamical system. With gifting, we demonstrate increased convergence of high risk, general-sum coordination games to the prosocial equilibrium both via numerical analysis and experiments.
Incentivizing Routing Choices for Safe and Efficient Transportation in the Face of the COVID-19 Pandemic
Dec 28, 2020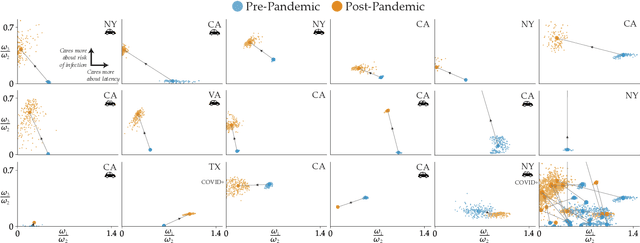
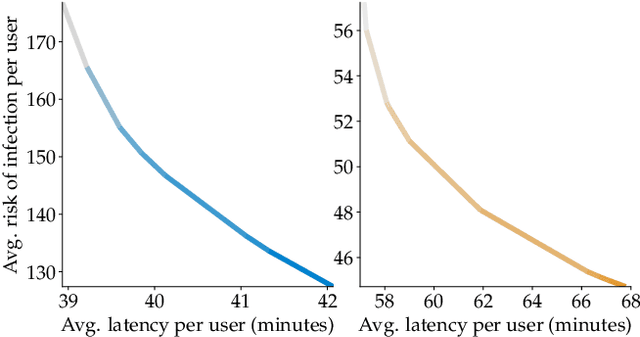
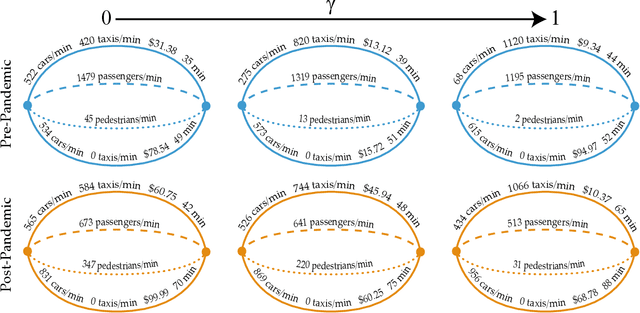
The COVID-19 pandemic has severely affected many aspects of people's daily lives. While many countries are in a re-opening stage, some effects of the pandemic on people's behaviors are expected to last much longer, including how they choose between different transport options. Experts predict considerably delayed recovery of the public transport options, as people try to avoid crowded places. In turn, significant increases in traffic congestion are expected, since people are likely to prefer using their own vehicles or taxis as opposed to riskier and more crowded options such as the railway. In this paper, we propose to use financial incentives to set the tradeoff between risk of infection and congestion to achieve safe and efficient transportation networks. To this end, we formulate a network optimization problem to optimize taxi fares. For our framework to be useful in various cities and times of the day without much designer effort, we also propose a data-driven approach to learn human preferences about transport options, which is then used in our taxi fare optimization. Our user studies and simulation experiments show our framework is able to minimize congestion and risk of infection.