 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausally Robust Reward Learning from Reason-Augmented Preference Feedback
Mar 05, 2026Preference-based reward learning is widely used for shaping agent behavior to match a user's preference, yet its sparse binary feedback makes it especially vulnerable to causal confusion. The learned reward often latches onto spurious features that merely co-occur with preferred trajectories during training, collapsing when those correlations disappear or reverse at test time. We introduce ReCouPLe, a lightweight framework that uses natural language rationales to provide the missing causal signal. Each rationale is treated as a guiding projection axis in an embedding space, training the model to score trajectories based on features aligned with that axis while de-emphasizing context that is unrelated to the stated reason. Because the same rationales (e.g., "avoids collisions", "completes the task faster") can appear across multiple tasks, ReCouPLe naturally reuses the same causal direction whenever tasks share semantics, and transfers preference knowledge to novel tasks without extra data or language-model fine-tuning. Our learned reward model can ground preferences on the articulated reason, aligning better with user intent and generalizing beyond spurious features. ReCouPLe outperforms baselines by up to 1.5x in reward accuracy under distribution shifts, and 2x in downstream policy performance in novel tasks. We have released our code at https://github.com/mj-hwang/ReCouPLe
Judgelight: Trajectory-Level Post-Optimization for Multi-Agent Path Finding via Closed-Subwalk Collapsing
Jan 27, 2026Multi-Agent Path Finding (MAPF) is an NP-hard problem with applications in warehouse automation and multi-robot coordination. Learning-based MAPF solvers offer fast and scalable planning but often produce feasible trajectories that contain unnecessary or oscillatory movements. We propose Judgelight, a post-optimization method that improves trajectory quality after a MAPF solver generates a feasible schedule. Judgelight collapses closed subwalks in agents' trajectories to remove redundant movements while preserving all feasibility constraints. We formalize this process as MAPF-Collapse, prove that it is NP-hard, and present an exact optimization approach by formulating it as integer linear programming (ILP) problem. Experimental results show Judgelight consistently reduces solution cost by around 20%, particularly for learning-based solvers, producing trajectories that are better suited for real-world deployment.
Actor-Free Continuous Control via Structurally Maximizable Q-Functions
Oct 21, 2025Value-based algorithms are a cornerstone of off-policy reinforcement learning due to their simplicity and training stability. However, their use has traditionally been restricted to discrete action spaces, as they rely on estimating Q-values for individual state-action pairs. In continuous action spaces, evaluating the Q-value over the entire action space becomes computationally infeasible. To address this, actor-critic methods are typically employed, where a critic is trained on off-policy data to estimate Q-values, and an actor is trained to maximize the critic's output. Despite their popularity, these methods often suffer from instability during training. In this work, we propose a purely value-based framework for continuous control that revisits structural maximization of Q-functions, introducing a set of key architectural and algorithmic choices to enable efficient and stable learning. We evaluate the proposed actor-free Q-learning approach on a range of standard simulation tasks, demonstrating performance and sample efficiency on par with state-of-the-art baselines, without the cost of learning a separate actor. Particularly, in environments with constrained action spaces, where the value functions are typically non-smooth, our method with structural maximization outperforms traditional actor-critic methods with gradient-based maximization. We have released our code at https://github.com/USC-Lira/Q3C.
HAND Me the Data: Fast Robot Adaptation via Hand Path Retrieval
May 28, 2025



We hand the community HAND, a simple and time-efficient method for teaching robots new manipulation tasks through human hand demonstrations. Instead of relying on task-specific robot demonstrations collected via teleoperation, HAND uses easy-to-provide hand demonstrations to retrieve relevant behaviors from task-agnostic robot play data. Using a visual tracking pipeline, HAND extracts the motion of the human hand from the hand demonstration and retrieves robot sub-trajectories in two stages: first filtering by visual similarity, then retrieving trajectories with similar behaviors to the hand. Fine-tuning a policy on the retrieved data enables real-time learning of tasks in under four minutes, without requiring calibrated cameras or detailed hand pose estimation. Experiments also show that HAND outperforms retrieval baselines by over 2x in average task success rates on real robots. Videos can be found at our project website: https://liralab.usc.edu/handretrieval/.
IMPACT: Intelligent Motion Planning with Acceptable Contact Trajectories via Vision-Language Models
Mar 13, 2025



Motion planning involves determining a sequence of robot configurations to reach a desired pose, subject to movement and safety constraints. Traditional motion planning finds collision-free paths, but this is overly restrictive in clutter, where it may not be possible for a robot to accomplish a task without contact. In addition, contacts range from relatively benign (e.g., brushing a soft pillow) to more dangerous (e.g., toppling a glass vase). Due to this diversity, it is difficult to characterize which contacts may be acceptable or unacceptable. In this paper, we propose IMPACT, a novel motion planning framework that uses Vision-Language Models (VLMs) to infer environment semantics, identifying which parts of the environment can best tolerate contact based on object properties and locations. Our approach uses the VLM's outputs to produce a dense 3D "cost map" that encodes contact tolerances and seamlessly integrates with standard motion planners. We perform experiments using 20 simulation and 10 real-world scenes and assess using task success rate, object displacements, and feedback from human evaluators. Our results over 3620 simulation and 200 real-world trials suggest that IMPACT enables efficient contact-rich motion planning in cluttered settings while outperforming alternative methods and ablations. Supplementary material is available at https://impact-planning.github.io/.
Multi-Agent Inverse Q-Learning from Demonstrations
Mar 06, 2025



When reward functions are hand-designed, deep reinforcement learning algorithms often suffer from reward misspecification, causing them to learn suboptimal policies in terms of the intended task objectives. In the single-agent case, inverse reinforcement learning (IRL) techniques attempt to address this issue by inferring the reward function from expert demonstrations. However, in multi-agent problems, misalignment between the learned and true objectives is exacerbated due to increased environment non-stationarity and variance that scales with multiple agents. As such, in multi-agent general-sum games, multi-agent IRL algorithms have difficulty balancing cooperative and competitive objectives. To address these issues, we propose Multi-Agent Marginal Q-Learning from Demonstrations (MAMQL), a novel sample-efficient framework for multi-agent IRL. For each agent, MAMQL learns a critic marginalized over the other agents' policies, allowing for a well-motivated use of Boltzmann policies in the multi-agent context. We identify a connection between optimal marginalized critics and single-agent soft-Q IRL, allowing us to apply a direct, simple optimization criterion from the single-agent domain. Across our experiments on three different simulated domains, MAMQL significantly outperforms previous multi-agent methods in average reward, sample efficiency, and reward recovery by often more than 2-5x. We make our code available at https://sites.google.com/view/mamql .
RAILGUN: A Unified Convolutional Policy for Multi-Agent Path Finding Across Different Environments and Tasks
Mar 04, 2025



Multi-Agent Path Finding (MAPF), which focuses on finding collision-free paths for multiple robots, is crucial for applications ranging from aerial swarms to warehouse automation. Solving MAPF is NP-hard so learning-based approaches for MAPF have gained attention, particularly those leveraging deep neural networks. Nonetheless, despite the community's continued efforts, all learning-based MAPF planners still rely on decentralized planning due to variability in the number of agents and map sizes. We have developed the first centralized learning-based policy for MAPF problem called RAILGUN. RAILGUN is not an agent-based policy but a map-based policy. By leveraging a CNN-based architecture, RAILGUN can generalize across different maps and handle any number of agents. We collect trajectories from rule-based methods to train our model in a supervised way. In experiments, RAILGUN outperforms most baseline methods and demonstrates great zero-shot generalization capabilities on various tasks, maps and agent numbers that were not seen in the training dataset.
MILE: Model-based Intervention Learning
Feb 19, 2025



Imitation learning techniques have been shown to be highly effective in real-world control scenarios, such as robotics. However, these approaches not only suffer from compounding error issues but also require human experts to provide complete trajectories. Although there exist interactive methods where an expert oversees the robot and intervenes if needed, these extensions usually only utilize the data collected during intervention periods and ignore the feedback signal hidden in non-intervention timesteps. In this work, we create a model to formulate how the interventions occur in such cases, and show that it is possible to learn a policy with just a handful of expert interventions. Our key insight is that it is possible to get crucial information about the quality of the current state and the optimality of the chosen action from expert feedback, regardless of the presence or the absence of intervention. We evaluate our method on various discrete and continuous simulation environments, a real-world robotic manipulation task, as well as a human subject study. Videos and the code can be found at https://liralab.usc.edu/mile .
NaVILA: Legged Robot Vision-Language-Action Model for Navigation
Dec 05, 2024
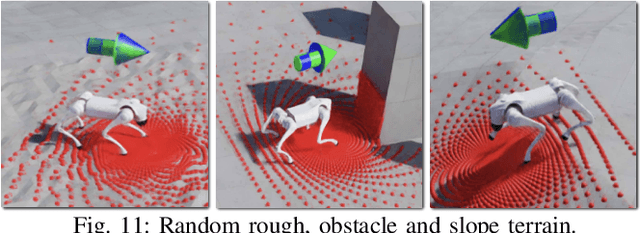


This paper proposes to solve the problem of Vision-and-Language Navigation with legged robots, which not only provides a flexible way for humans to command but also allows the robot to navigate through more challenging and cluttered scenes. However, it is non-trivial to translate human language instructions all the way to low-level leg joint actions. We propose NaVILA, a 2-level framework that unifies a Vision-Language-Action model (VLA) with locomotion skills. Instead of directly predicting low-level actions from VLA, NaVILA first generates mid-level actions with spatial information in the form of language, (e.g., "moving forward 75cm"), which serves as an input for a visual locomotion RL policy for execution. NaVILA substantially improves previous approaches on existing benchmarks. The same advantages are demonstrated in our newly developed benchmarks with IsaacLab, featuring more realistic scenes, low-level controls, and real-world robot experiments. We show more results at https://navila-bot.github.io/
Accurate and Data-Efficient Toxicity Prediction when Annotators Disagree
Oct 16, 2024



When annotators disagree, predicting the labels given by individual annotators can capture nuances overlooked by traditional label aggregation. We introduce three approaches to predicting individual annotator ratings on the toxicity of text by incorporating individual annotator-specific information: a neural collaborative filtering (NCF) approach, an in-context learning (ICL) approach, and an intermediate embedding-based architecture. We also study the utility of demographic information for rating prediction. NCF showed limited utility; however, integrating annotator history, demographics, and survey information permits both the embedding-based architecture and ICL to substantially improve prediction accuracy, with the embedding-based architecture outperforming the other methods. We also find that, if demographics are predicted from survey information, using these imputed demographics as features performs comparably to using true demographic data. This suggests that demographics may not provide substantial information for modeling ratings beyond what is captured in survey responses. Our findings raise considerations about the relative utility of different types of annotator information and provide new approaches for modeling annotators in subjective NLP tasks.