 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing SIA Development: A Case Study in User-Centered Design for Estuary, a Multimodal Socially Interactive Agent Framework
Apr 20, 2025This case study presents our user-centered design model for Socially Intelligent Agent (SIA) development frameworks through our experience developing Estuary, an open source multimodal framework for building low-latency real-time socially interactive agents. We leverage the Rapid Assessment Process (RAP) to collect the thoughts of leading researchers in the field of SIAs regarding the current state of the art for SIA development as well as their evaluation of how well Estuary may potentially address current research gaps. We achieve this through a series of end-user interviews conducted by a fellow researcher in the community. We hope that the findings of our work will not only assist the continued development of Estuary but also guide the development of other future frameworks and technologies for SIAs.
Estuary: A Framework For Building Multimodal Low-Latency Real-Time Socially Interactive Agents
Oct 26, 2024
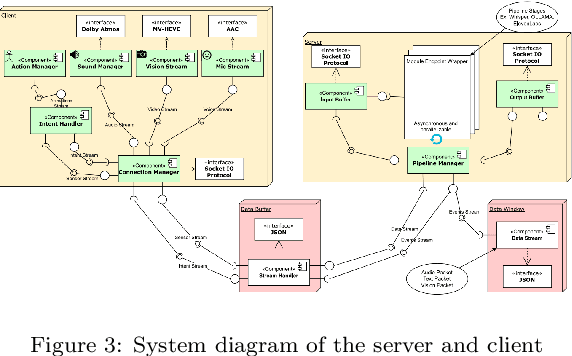
The rise in capability and ubiquity of generative artificial intelligence (AI) technologies has enabled its application to the field of Socially Interactive Agents (SIAs). Despite rising interest in modern AI-powered components used for real-time SIA research, substantial friction remains due to the absence of a standardized and universal SIA framework. To target this absence, we developed Estuary: a multimodal (text, audio, and soon video) framework which facilitates the development of low-latency, real-time SIAs. Estuary seeks to reduce repeat work between studies and to provide a flexible platform that can be run entirely off-cloud to maximize configurability, controllability, reproducibility of studies, and speed of agent response times. We are able to do this by constructing a robust multimodal framework which incorporates current and future components seamlessly into a modular and interoperable architecture.
Trajectory Improvement and Reward Learning from Comparative Language Feedback
Oct 08, 2024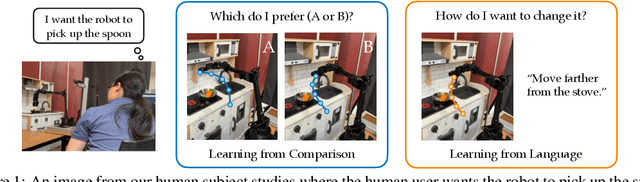
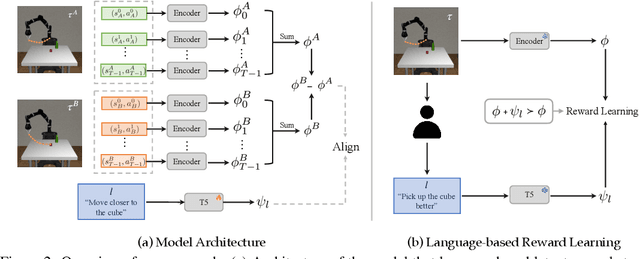
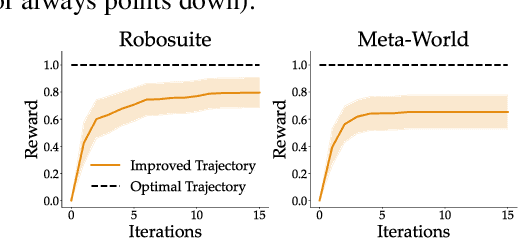
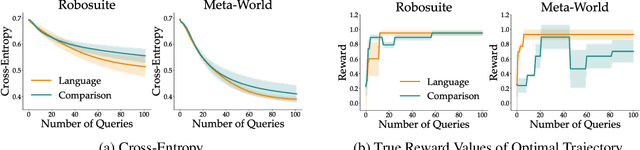
Learning from human feedback has gained traction in fields like robotics and natural language processing in recent years. While prior works mostly rely on human feedback in the form of comparisons, language is a preferable modality that provides more informative insights into user preferences. In this work, we aim to incorporate comparative language feedback to iteratively improve robot trajectories and to learn reward functions that encode human preferences. To achieve this goal, we learn a shared latent space that integrates trajectory data and language feedback, and subsequently leverage the learned latent space to improve trajectories and learn human preferences. To the best of our knowledge, we are the first to incorporate comparative language feedback into reward learning. Our simulation experiments demonstrate the effectiveness of the learned latent space and the success of our learning algorithms. We also conduct human subject studies that show our reward learning algorithm achieves a 23.9% higher subjective score on average and is 11.3% more time-efficient compared to preference-based reward learning, underscoring the superior performance of our method. Our website is at https://liralab.usc.edu/comparative-language-feedback/
Do Bayesian Neural Networks Weapon System Improve Predictive Maintenance?
Dec 16, 2023We implement a Bayesian inference process for Neural Networks to model the time to failure of highly reliable weapon systems with interval-censored data and time-varying covariates. We analyze and benchmark our approach, LaplaceNN, on synthetic and real datasets with standard classification metrics such as Receiver Operating Characteristic (ROC) Area Under Curve (AUC) Precision-Recall (PR) AUC, and reliability curve visualizations.