 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Suboptimality of Deterministic Policy Gradients in Complex Q-functions
Oct 15, 2024



In reinforcement learning, off-policy actor-critic approaches like DDPG and TD3 are based on the deterministic policy gradient. Herein, the Q-function is trained from off-policy environment data and the actor (policy) is trained to maximize the Q-function via gradient ascent. We observe that in complex tasks like dexterous manipulation and restricted locomotion, the Q-value is a complex function of action, having several local optima or discontinuities. This poses a challenge for gradient ascent to traverse and makes the actor prone to get stuck at local optima. To address this, we introduce a new actor architecture that combines two simple insights: (i) use multiple actors and evaluate the Q-value maximizing action, and (ii) learn surrogates to the Q-function that are simpler to optimize with gradient-based methods. We evaluate tasks such as restricted locomotion, dexterous manipulation, and large discrete-action space recommender systems and show that our actor finds optimal actions more frequently and outperforms alternate actor architectures.
Designing an offline reinforcement learning objective from scratch
Jan 30, 2023
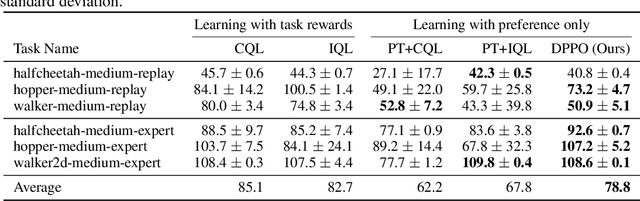
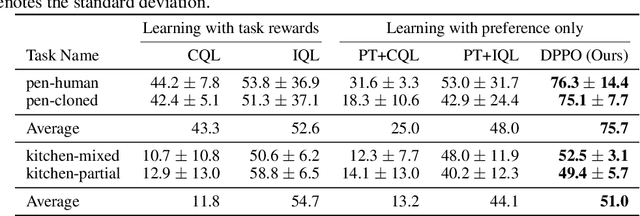
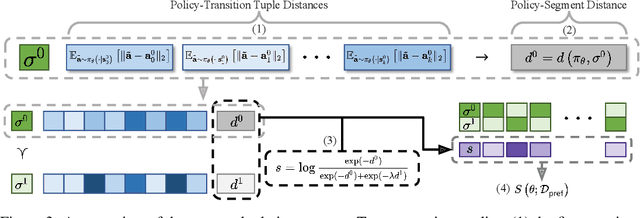
Offline reinforcement learning has developed rapidly over the recent years, but estimating the actual performance of offline policies still remains a challenge. We propose a scoring metric for offline policies that highly correlates with actual policy performance and can be directly used for offline policy optimization in a supervised manner. To achieve this, we leverage the contrastive learning framework to design a scoring metric that gives high scores to policies that imitate the actions yielding relatively high returns while avoiding those yielding relatively low returns. Our experiments show that 1) our scoring metric is able to more accurately rank offline policies and 2) the policies optimized using our metric show high performance on various offline reinforcement learning benchmarks. Notably, our algorithm has a much lower network capacity requirement for the policy network compared to other supervised learning-based methods and also does not need any additional networks such as a Q-network.
PlaNet of the Bayesians: Reconsidering and Improving Deep Planning Network by Incorporating Bayesian Inference
Mar 01, 2020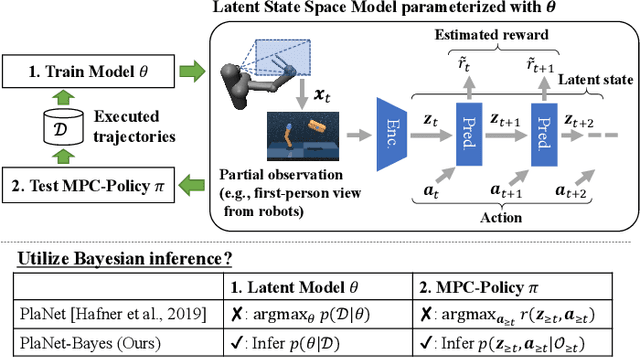
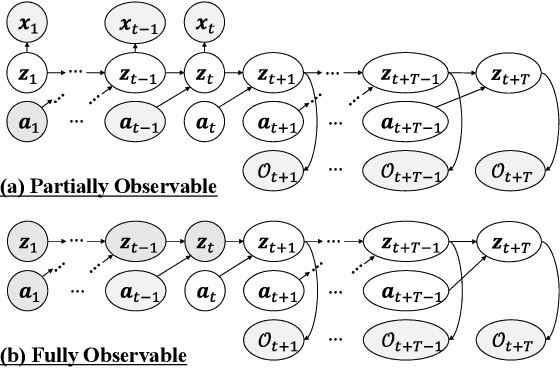
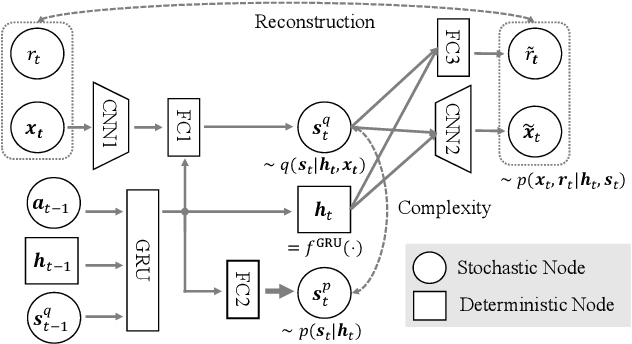

In the present paper, we propose an extension of the Deep Planning Network (PlaNet), also referred to as PlaNet of the Bayesians (PlaNet-Bayes). There has been a growing demand in model predictive control (MPC) in partially observable environments in which complete information is unavailable because of, for example, lack of expensive sensors. PlaNet is a promising solution to realize such latent MPC, as it is used to train state-space models via model-based reinforcement learning (MBRL) and to conduct planning in the latent space. However, recent state-of-the-art strategies mentioned in MBRR literature, such as involving uncertainty into training and planning, have not been considered, significantly suppressing the training performance. The proposed extension is to make PlaNet uncertainty-aware on the basis of Bayesian inference, in which both model and action uncertainty are incorporated. Uncertainty in latent models is represented using a neural network ensemble to approximately infer model posteriors. The ensemble of optimal action candidates is also employed to capture multimodal uncertainty in the optimality. The concept of the action ensemble relies on a general variational inference MPC (VI-MPC) framework and its instance, probabilistic action ensemble with trajectory sampling (PaETS). In this paper, we extend VI-MPC and PaETS, which have been originally introduced in previous literature, to address partially observable cases. We experimentally compare the performances on continuous control tasks, and conclude that our method can consistently improve the asymptotic performance compared with PlaNet.